Hbase 整合Phoenix
1、Phoenix 简介
Phoenix 是 Hbase 的开源的 SQL 皮肤,可以使用标准的JDBC API 代替HBase 客户端 API来创建表,插入和查询Hbase数据.
Phoenix 特点:
- 易集成:如 Spark,Hive,Pig,Flume 等
- 操作进度:DML/DDL 支持和SQL标准化操作
- 支持HBase 二级索引创建
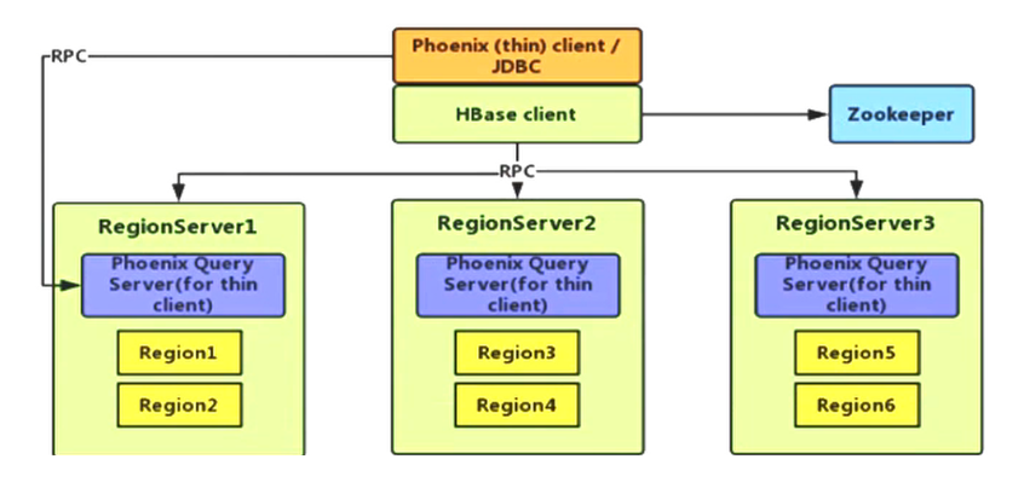
Phoenxi 架构
2、快速使用
2.1、安装
hui@hadoop201 software]$ tar -zxvf apache-phoenix-5.0.0-HBase-2.0-bin.tar.gz -C /opt/module/
[hui@hadoop201 module]$ mv apache-phoenix-5.0.0-HBase-2.0-bin/ phoenix-5.0.0
环境变量
[hui@hadoop201 phoenix-5.0.0]$ sudo vim /etc/profile.d/my_env.sh #PHOENIX export PHOENIX_HOME=/opt/module/phoenix-5.0.0 export PHOENIX_CLASSPATH=$PHOENIX_HOME export PATH=$PATH:$PHOENIX_HOME/bin [hui@hadoop201 phoenix-5.0.0]$ source /etc/profile
将 phoenix-5.0.0-HBase-2.0-server.jar cp 到hbase 的 lib 下
hui@hadoop201 phoenix-5.0.0]$ cp phoenix-5.0.0-HBase-2.0-server.jar /opt/module/hbase-2.0.5/lib/ [hui@hadoop201 phoenix-5.0.0]$ ll /opt/module/hbase-2.0.5/lib/phoenix-5.0.0-HBase-2.0-server.jar -rw-r--r--. 1 hui hui 41800313 May 9 19:15 /opt/module/hbase-2.0.5/lib/phoenix-5.0.0-HBase-2.0-server.jar [hui@hadoop201 hbase-2.0.5]$ cd lib/ [hui@hadoop201 lib]$ ll phoenix* -rw-r--r--. 1 hui hui 41800313 May 9 19:15 phoenix-5.0.0-HBase-2.0-server.jar [hui@hadoop201 lib]$ sxync.sh phoenix-5.0.0-HBase-2.0-server.jar
启动 hbase
[hui@hadoop201 hbase-2.0.5]$ bin/start-hbase.sh
链接phoenix
[hui@hadoop201 phoenix-5.0.0]$ bin/sqlline.py 0: jdbc:phoenix:> !! !quit !done !exit !connect !open !describe !indexes !primarykeys !exportedkeys !manual !importedkeys !procedures !tables !typeinfo !columns !reconnect !dropall !history !metadata !nativesql !dbinfo !rehash !verbose !run !batch !list !all !go !# !script !record !brief !close !closeall !isolation !outputformat !autocommit !commit !properties !rollback !help !? !set !save !scan !sql !call #列出所有表 0: jdbc:phoenix:> !tables
2.2、Phoneix Shell 操作
1、schema 操作
默认情况下,在phoenix 中不能创建schema ,需要将如下参数添加到hbse-site.xml 中,并copy 到phoenix的bin 下
<property> <name>phoenix.schema.isNamespaceMappingEnabled</name> <value>true</value> </property>
分发配置
[hui@hadoop201 hbase-2.0.5]$ sxync.sh conf/hbase-site.xml [hui@hadoop201 bin]$ pwd /opt/module/phoenix-5.0.0/bin [hui@hadoop201 bin]$ less hbase-site.xml <property> <name>hbase.regionserver.wal.codec</name> <value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value> </property> <property> <name>phoenix.schema.isNamespaceMappingEnabled</name> <value>true</value> </property>
创建schema
0: jdbc:phoenix:> create schema if not exists mydb ;
No rows affected (0.28 seconds)
hbase shell 查看
hbase(main):001:0> list_namespace NAMESPACE MYDB SYSTEM default hbase
发现 phoenix 建的 schema 名和 表名会转换为大写,若要使用小写,可以在名称两边加双引号
drop schema mydb
2、表 操作
创建表必须指定主键
create table student( id VARCHAR primary key, name VARCHAR, age VARCHAR);
插入/修改数据
upsert into student(id,name,age) values('1001','linghc','26'); upsert into student(id,name,age) values('1002','yilin','18');
查询数据
select id,name,age from student; select * from student;
带条件查询
select * from student where id='1002';
删除数据
delete from student where id='1002' ;
3、表映射
默认情况下,直接在hbase 创建的表,通过 phoenix 是看不到的,如果要在phoenix中操作直接在hbase创建的表,需要在phoenix 中进行映射,映射方式有两种,视图映射和表映射。
1、hbase 没有表,直接在phoenix中进行建表,已经测试过:phoenix 基本使用就是这种情况
2、hbase建表后,通过phoenix 创建视图只能查询数据
create 'emp','info'
插入数据
put 'emp','1001','info:name','linghc' put 'emp','1002','info:name','yilin'
phoenix 创建视图
create view "emp" (id varchar primary key,"info"."name" varchar)
进行查询:注意视图名小写要加引号
0: jdbc:phoenix:> select * from "emp";
删除视图
drop view "emp";
3、hbase 建表后,phoenix 进行表映射
create table "emp" ( id varchar primary key, "info"."name" varchar) COLUMN_ENCODED_BYTES= none;
此时可以对表数据进行修改;
2.3、Phoneix 二级索引
修改配置文件
<property> <name>hbase.regionserver.wal.codec</name> <value>org.apache.hadoop.hbase.regionserver.wal.IndexedwALEditCodec</value> </property>
分发后重启hbase
[hui@hadoop201 conf]$ sxync.sh hbase-site.xml ==================== hadoop201 ==================== sending incremental file list sent 63 bytes received 12 bytes 50.00 bytes/sec total size is 1,778 speedup is 23.71 ==================== hadoop202 ==================== sending incremental file list hbase-site.xml sent 496 bytes received 53 bytes 366.00 bytes/sec total size is 1,778 speedup is 3.24 ==================== hadoop203 ==================== sending incremental file list hbase-site.xml sent 496 bytes received 53 bytes 1,098.00 bytes/sec total size is 1,778 speedup is 3.24 [hui@hadoop201 conf]$ ../bin/start-hbase.sh
二级索引之前的查询计划
explain select id from student;//FULL SCAN explain select id from student where id='1002';//POINT LOOKUP explain select id from student where name='yilin';// FULL SCAN
建立二级索引
create index idx_student_name on student(name);
再次查看执行计划
explain select id from student;//FULL SCAN explain select id from student where id='1002';//POINT LOOKUP explain select id from student where name='yilin';// RANGE SCAN OVER IDX_STUDENT_NAME
索引在底层维护了一张名为 idx_student_name 的表,主键是 students 的ID和name 组成的联合索引
0: jdbc:phoenix:> !tables +------------+--------------+-------------------+---------------+----------+------------+----------------------------+-----------------+--------------+-----------------+ | TABLE_CAT | TABLE_SCHEM | TABLE_NAME | TABLE_TYPE | REMARKS | TYPE_NAME | SELF_REFERENCING_COL_NAME | REF_GENERATION | INDEX_STATE | IMMUTABLE_ROWS | +------------+--------------+-------------------+---------------+----------+------------+----------------------------+-----------------+--------------+-----------------+ | | | IDX_STUDENT_NAME | INDEX | | | | | ACTIVE | false | | | SYSTEM | CATALOG | SYSTEM TABLE | | | | | | false | | | SYSTEM | FUNCTION | SYSTEM TABLE | | | | | | false | | | SYSTEM | LOG | SYSTEM TABLE | | | | | | true | | | SYSTEM | SEQUENCE | SYSTEM TABLE | | | | | | false | | | SYSTEM | STATS | SYSTEM TABLE | | | | | | false | | | | STUDENT | TABLE | | | | | | false | | | | emp | TABLE | | | | | | false | +------------+--------------+-------------------+---------------+----------+------------+----------------------------+-----------------+--------------+-----------------+ 0: jdbc:phoenix:> select * from IDX_STUDENT_NAME; +---------+-------+ | 0:NAME | :ID | +---------+-------+ | linghc | 1001 | | renyy | 1003 | | yilin | 1002 |
总结:全局索引表:会创建一张索引表,在索引表中,将索引列与原表中的rowkey组合起来作为索引表的rowkey进行使用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号