Spark Streaming 简介
1、Spark Streaming 概述
1.1、离线&实时
离线计算:计算开始前已知所有输入数据,输入数据不会发生变化,一般计算量级较大,计算时间较长,例如月初对上月整月数据或者一天凌晨对前一天数据进行分析计算。一般使用常用hive作为分析引擎。
实时计算:输入数据是可以以序列化的方式一个个并行的处理,也就是说开始计算的时候并不知道所有的输入数据。与离线计算相比,运行时间短,计算量级相对较小,强调计算过程时间要短,快速出结果。
1.2 批量&流式
批流指的数据处理形式,
- 批:处理批量数据,冷数据,单个处理数据量大,处理速度比流慢。
- 流:在线实时生产的数据,单次处理的数据较小,单处理速度更快。
近年来,在 web,网络监控,传感器等领域,兴起了一种数据密集型应用--流数据,数据以大量,快速时变的流形式持续到达。流式数据具有一下特点
- 数据快速持续达到,潜在大小也许是无穷无尽的;
- 数据来源多样,格式不一;
- 数据量大,但不十分关注存储,一旦经过处理,要么丢弃,要么被归档存储;
- 注重数据整体价值,不过分关注个别数据。
1.3 Spark Streaming 是什么
Spark Streaming 是 Spark基于流式数据的处理模块。SparkStreaming 支持输入源很多,例如:kafka,flume,MQ,和简单的TCP套接字等等。输入输入后可以用Spark 高度抽象算子入:map,,reduce.join,window等进行处理运算,输出结果也可以进行保存到多种环境。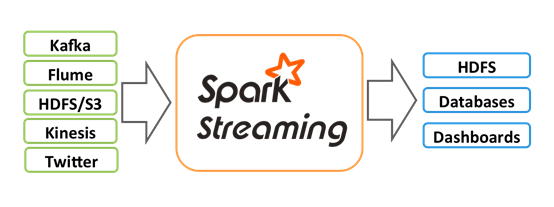
在 Spark Streaming 中,处理数据的单位是一批而不是单条,而数据采集却是逐条进行的,因此 Spark Streaming 系统需要设置间隔使得数据汇总到一定的量后再一并操作,这个间隔就是批处理间隔。批处理间隔是Spark Streaming的核心概念和关键参数,它决定了Spark Streaming提交作业的频率和数据处理的延迟,同时也影响着数据处理的吞吐量和性能。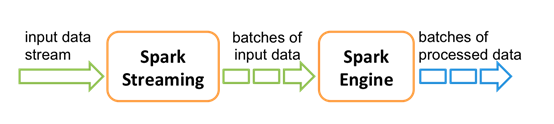
和 Spark 基于 RDD的概念很相似,Spark Streaming 使用了一个高级数据抽象,离散化流:DStreams,DSteams 是随时间推移而收到数据的序列,在内部,每个时间区间收到的数据都作为RDD存在,而SDtreams 是由这些RDD组成的序列。DStreams 有来自数据源输入的数据流来创建,也可以通过其他的 DStreams 上应用一些高阶操作来获取。
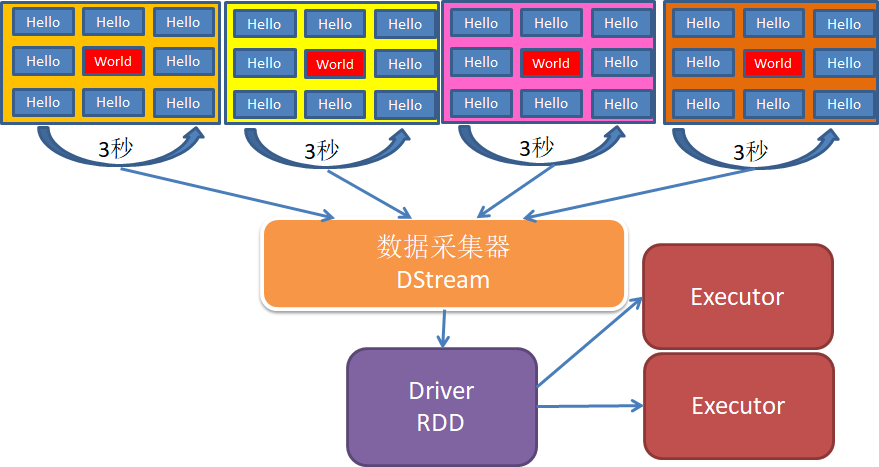
1.4、Spark Streaming 架构
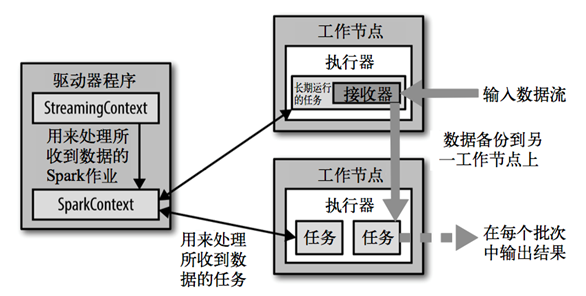
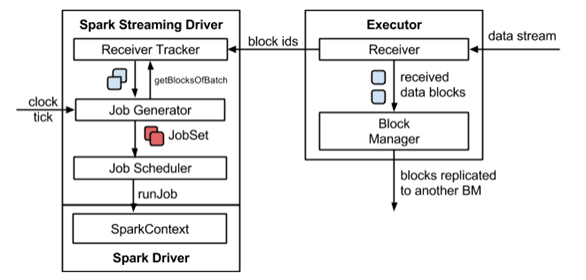
背压机制
Spark 1.5以前版本,用户如果要限制Receiver的数据接收速率,可以通过设置静态配制参数“spark.streaming.receiver.maxRate”的值来实现,此举虽然可以通过限制接收速率,来适配当前的处理能力,防止内存溢出,但也会引入其它问题。比如:producer数据生产高于maxRate,当前集群处理能力也高于maxRate,这就会造成资源利用率下降等问题。为了更好的协调数据接收速率与资源处理能力,1.5版本开始Spark Streaming可以动态控制数据接收速率来适配集群数据处理能力。背压机制(即Spark Streaming Backpressure): 根据JobScheduler反馈作业的执行信息来动态调整Receiver数据接收率。通过属性“spark.streaming.backpressure.enabled”来控制是否启用backpressure机制,默认值false,即不启用。
2、DStream 入门
2.1、WordCount 案例
使用netcat工具向9999端口不断的发送数据,通过SparkStreaming读取端口数据并统计不同单词出现的次数
引入依赖
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.12</artifactId> <version>3.0.0</version> </dependency>
编写代码
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaing")
//StreamingContext 两个参数 sparkConf 配置文件 Seconds(3) 微批采集周期
val ssc = new StreamingContext(sparkConf, Seconds(3))
//配置监听的IP和端口
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 9999)
//下面的和 wordcount 差不多
val words: DStream[String] = lines.flatMap(_.split(" "))
val wordTOne: DStream[(String, Int)] = words.map((_, 1))
val wordCount: DStream[(String, Int)] = wordTOne.reduceByKey(_ + _)
wordCount.print()
//streaming 处于长期运行,所以不能关闭
// 启动采集器
ssc.start()
//等待采集器关闭
ssc.awaitTermination()
}
启动nc
[hui@hadoop103 ~]$ nc -lk 9999
运行程序,输入单词 观察结果
2.2、WordCount 说明
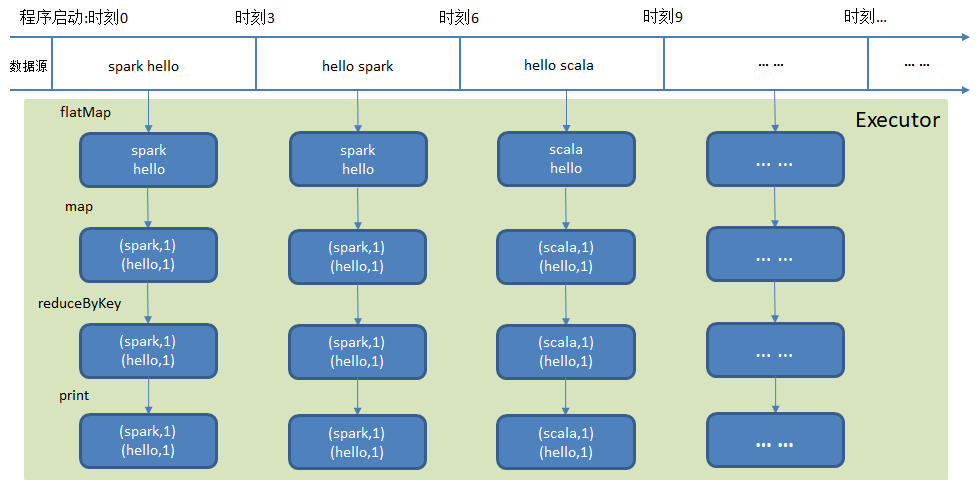
Discretized Stream是Spark Streaming的基础抽象,代表持续性的数据流和经过各种Spark算子操作后的结果数据流。在内部实现上,DStream是一系列连续的RDD来表示,每个RDD含有一段时间间隔内的数据,对这些 RDD的转换是由Spark引擎来计算的, DStream的操作隐藏的大多数的细节, 然后给开发者提供了方便使用的高级 API如下图:
2.3、注意事项
- 一旦StreamingContext已经启动, 则不能再添加新的 streaming computations
- 一旦一个StreamingContext已经停止(StreamingContext.stop()), 他也不能再重启
- 在一个 JVM 内, 同一时间只能启动一个StreamingContext
- stop() 的方式停止StreamingContext, 也会把SparkContext停掉. 如果仅仅想停止StreamingContext, 则应该这样: stop(false)
- 一个SparkContext可以重用去创建多个StreamingContext, 前提是以前的StreamingContext已经停掉,并且SparkContext没有被停掉

 浙公网安备 33010602011771号
浙公网安备 33010602011771号