

Spark 广播变量&累加器
Spark 为了达到高并发,高吞吐数据处理能力除了封装RDD外,也封装了另外两个数据对象
- 广播变量:分布式共享只读变量
- 累加器:分布式共享只写变量
1、广播变量
1.1、广播变量存在的意义
如果我们需要在分布式计算里面分发大对象,例如:集合,字典或者黑白名单等,这个都会有 Driver 端进行分发,一般情况下如果这个变量不被定义为广播变量,那么这个变量需要每个task都会分发一份,这在task 数目十分多的情况下Driver 的带宽会占用系统相当大的资源,而且会大量的消耗task服务器上的资源,如果将这样的变量定义为广播变量,那么只是每个executor拥有一份,这个executor启动task会共享这个变量,节省了网络IO和服务器资源。
1.2、广播变量图解
1、不使用广播变量
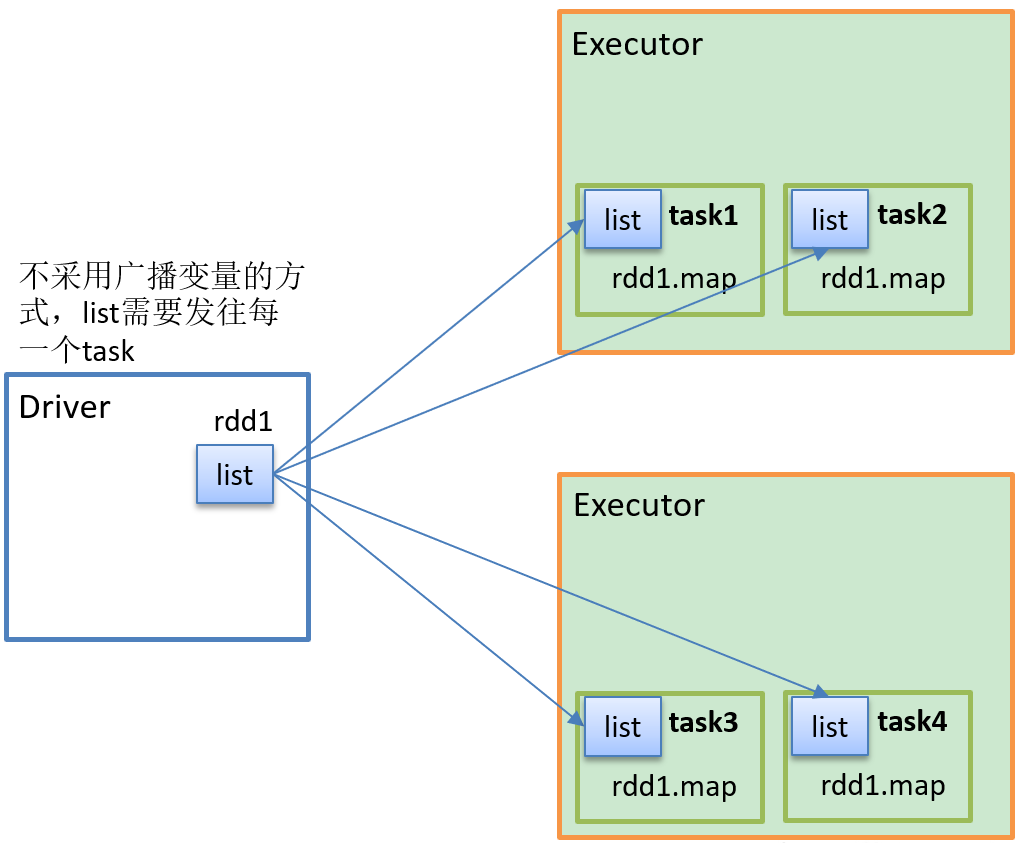
2、使用广播变量
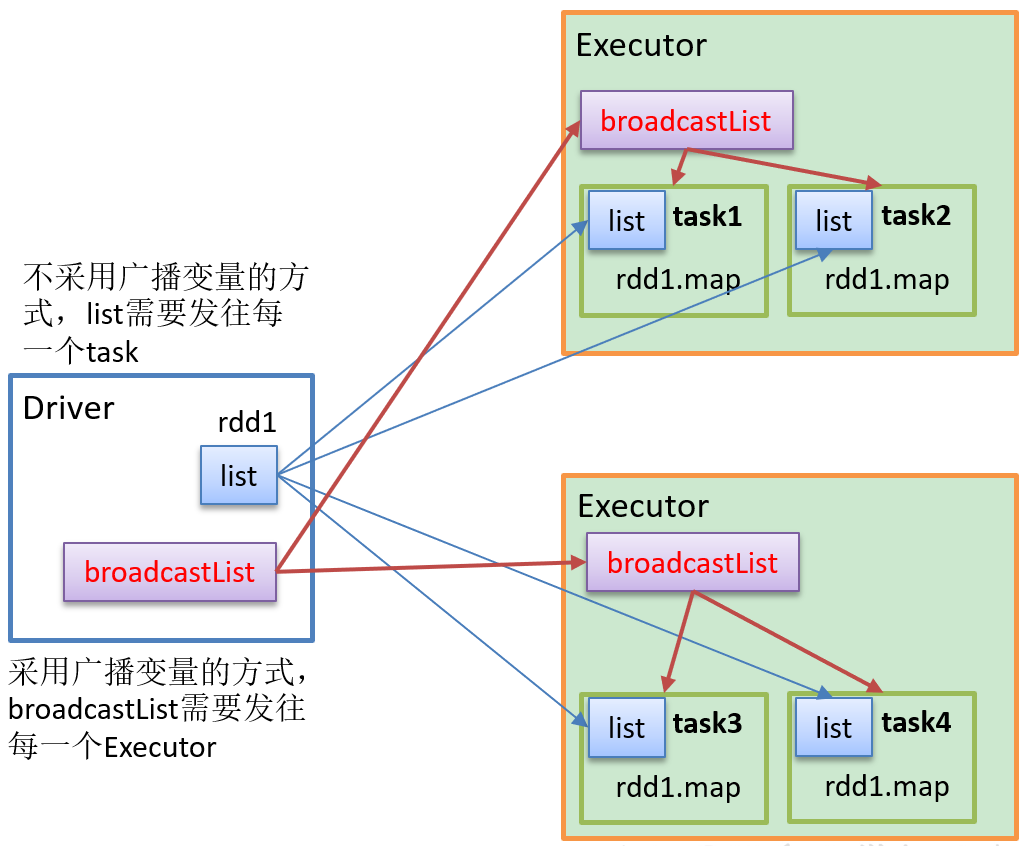
1.3、广播变量应用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | def main(args: Array[String]): Unit = { //1、声明配置信息 val conf: SparkConf = new SparkConf().setAppName("BroadCase").setMaster("local[*]") //2、获取执行环境 var sc: SparkContext = new SparkContext(conf) //创建两个RDD 实现join,此时用到了 shuffle 性能不高 val rdd1: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3))) /*val rdd2: RDD[(String, Int)] = sc.makeRDD(List(("a", 4), ("b", 5), ("c", 6))) rdd1.join(rdd2).collect().foreach(println)*/ //定义一个 list 实现 rdd1 与 list 的join var list: List[(String, Int)] = List(("a", 4), ("b", 5), ("c", 6)) //将 list 声明为广播变量 val broadcaseList: Broadcast[List[(String, Int)]] = sc.broadcast(list) val resulRDD: RDD[(String, (Int, Int))] = rdd1.map { case (k1, v1) => { var v2: Int = 0 //使用广播变量 for ((k3, v3) <- broadcaseList.value) { if (k1 == k3) { v2 = v3 } } (k1, (v1, v2)) } } resulRDD.collect().foreach(println) sc.stop() } |
运行结果
(a,(1,4)) (b,(2,5)) (c,(3,6))
1.4、广播变量使用注意细节
- 广播变量是只读变量,一旦被定义广播变量,不能修改;
- 不能将RDD广播出去,原因是RDD不存储数据,可以将RDD的结果进行广播;
- 广播变量只能在 Driver 端定义,不能在 Executor 端定义;
- 在Driver端可以修改广播变量的值,在Executor 端不能修改;
- 如果在 Executor 端用到了 Driver 变量,如果不使用广播变量在Executor 有多少task 就有多少 Driver 端的变量副本;
- 如果在 Executor 端用到了 Driver 变量,如果使用到广播变量每个Executor中只有一份Driver端的变量副本;
2、累加器.
2.1、累加器的意义
在spark应用程序中,我们经常会有这样的需求,如异常监控,调试,记录符合某特性的数据的数目,这种需求都需要用到计数器,如果一个变量不被声明为一个累加器,那么它将在被改变时不会再driver端进行全局汇总,即在分布式运行时每个task运行的只是原始变量的一个副本,并不能改变原始变量的值,但是当这个变量被声明为累加器后,该变量就会有分布式计数的功能。
2.2、累加器图解
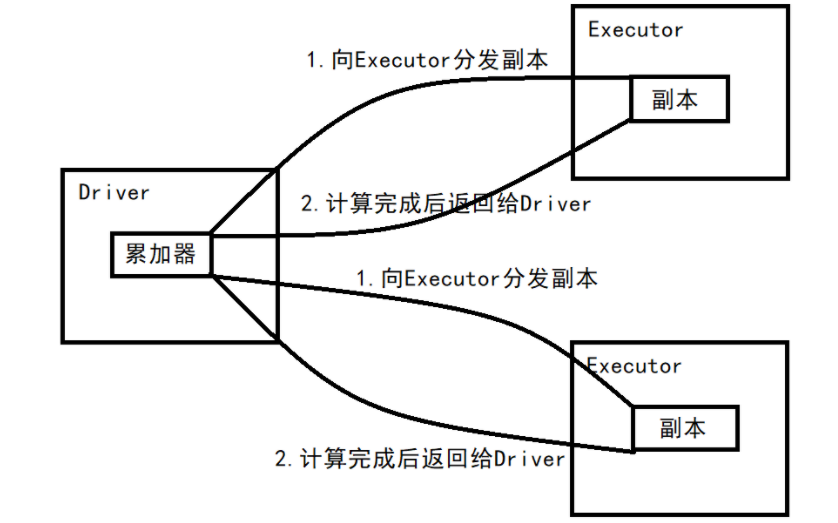
2.3、系统累加器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | def main(args: Array[String]): Unit = { //获取配置信息 val conf: SparkConf = new SparkConf().setAppName("LJQ").setMaster("local[*]") var sc: SparkContext = new SparkContext(conf) val rdd1: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("a", 2), ("a", 3), ("a", 4))) // 打印单词出现的次数(a,10) 代码执行了shuffle //rdd1.reduceByKey(_+_).collect().foreach(println) //使用另外一种方式处理 var sum = 0 //打印在 Executor 端 rdd1.foreach { case (a, count) => { sum += count println(s"Executor's sum= $sum") } } //打印在 Driver 端 println(s"Driver's $sum") //使用累加器实现数据聚合 //spark 自带常用累加器 val sum1: LongAccumulator = sc.longAccumulator("sum1") rdd1.foreach { case (a, count) => { //使用累加器 sum1.add(count) } } //调用累加器的值 println(sum1.value) sc.stop() } |
运行结果
Executor's sum= 2 Executor's sum= 4 Executor's sum= 3 Executor's sum= 1 Driver's 0 10
2.4、自定义累加器
自定义累加器方法:继承AccumulatorV2,设定输入、输出泛型,重写方法
需求:自定义累加器,统计RDD中首字母为“H”的单词以及出现的次数。
List("Hello", "Hello", "Hello", "Hello", "Hello", "Spark", "Spark")
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 | object Spark27_BroadCase_define { def main(args: Array[String]): Unit = { //获取执行环境 val conf: SparkConf = new SparkConf().setAppName("define").setMaster("local[*]") val sc: SparkContext = new SparkContext(conf) val rdd: RDD[String] = sc.makeRDD(List("Hello", "Hello", "Hello", "Hello", "Hello", "Spark", "Spark")) //创建累加器 val accumulator: MyAccumulator = new MyAccumulator //注册累加器 sc.register(accumulator, "wordcount") //使用累加器 rdd.foreach( word => { accumulator.add(word) } ) //获取累加器的值 println(accumulator.value) sc.stop }}//声明累加器//1、继承 AccumulatorV2 ,设置输入输出泛型&重写方法class MyAccumulator extends AccumulatorV2[String, mutable.Map[String, Long]] { //定义输出类型集合 var map = mutable.Map[String, Long]() //如果集合为空,则为初始化状态 override def isZero: Boolean = map.isEmpty //复制累加器 override def copy(): AccumulatorV2[String, mutable.Map[String, Long]] = { new MyAccumulator() } //充值累加器 override def reset(): Unit = map.clear() //增加数据 override def add(v: String): Unit = { //业务逻辑 if (v.startsWith("H")) { map(v) = map.getOrElse(v, 0L) + 1L; } } //合并累加器 override def merge(other: AccumulatorV2[String, mutable.Map[String, Long]]): Unit = { var map1 = map var map2 = other.value map = map.foldLeft(map2)( (map, kv) => { map(kv._1) = map.getOrElse(kv._1, 0L) + kv._2 map } ) } //累加器返回结果 override def value: mutable.Map[String, Long] = map} |
结果
Map(Hello -> 5)
累加器注意事项
累加器在 Driver 端声明,在 Executor 端更新。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
2020-04-11 数组模拟环形队列