Kafka 消费者(二)
1、offset位移
1.1、offset的默认维护位置
从0.9版本开始,consumer默认将offset保存在Kafka一个内置的topic中,该topic为__consumer_offsets,Kafka0.9版本之前,consumer默认将offset保存在Zookeeper中
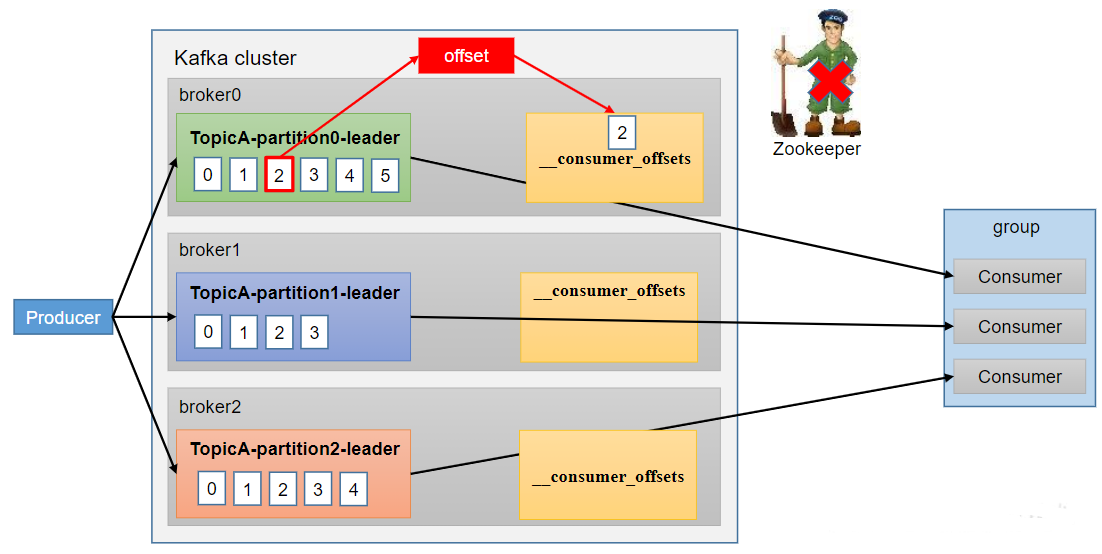
__consumer_offsets主题里面采用key和value的方式存储数据。key是group.id+topic+分区号,value就是当前offset的值。每隔一段时间,kafka内部会对这个topic进行compact,也就是每个group.id+topic+分区号就保留最新数据。
消费offset案例
思想:__consumer_offsets为Kafka中的topic,那就可以通过消费者进行消费。
在配置文件config/consumer.properties中添加配置exclude.internal.topics=false,默认是true,表示不能消费系统主题。为了查看该系统主题数据,所以该参数修改为false。
采用命令行方式,创建一个新的topic
bin/kafka-topics.sh --bootstrap-server hadoop103:9092 --create --partitions 3 --replication-factor 2 --topic tbg
bin/kafka-console-producer.sh --bootstrap -server hadoop103:9092 --topic tbg
消费消息
[hui@hadoop103 kafka]$ bin/kafka-console-consumer.sh -bootstrap-server hadoop103:9092 --topic tbg --group test
hello
tbg
通过命令查看 偏移量
bin/kafka-console-consumer.sh --topic __consumer_offsets --bootstrap-server hadoop103:9092 --consumer.config config/consumer.properties --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --from-beginning

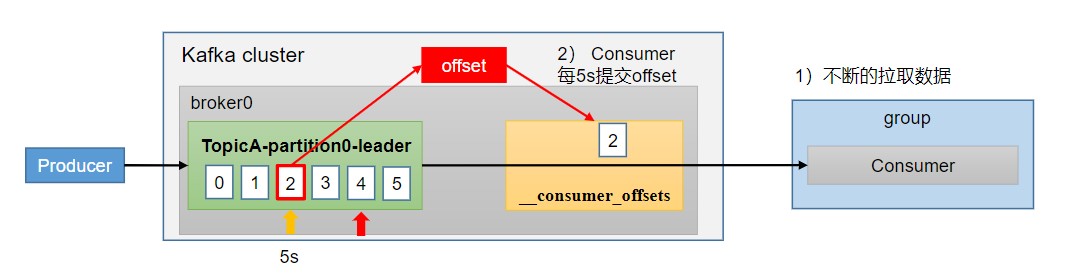
1.2、自动提交offset
为了使我们能够专注于自己的业务逻辑,Kafka提供了自动提交offset的功能。5s自动提交offset的相关参数:
- enable.auto.commit:是否开启自动提交offset功能,默认是true
- auto.commit.interval.ms:自动提交offset的时间间隔,默认是5s

自动提交示例
public class CustomeConsumerAutoOffset { public static void main(String[] args) { Properties properties = new Properties(); //连接 properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop103:9092,hadoop104:9092,hadoop105:9092"); //反序列化 properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); //配置消费者组ID properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test3"); //设置自动提交(其实默认就是自动提交offset) properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true); //修改自动提交间隔 1m properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,1000 ); //创建消费者 KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties); //订阅主题 ArrayList<String> topics = new ArrayList<>(); topics.add("lhc"); kafkaConsumer.subscribe(topics); //消费数据 while (true) { ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1)); for (ConsumerRecord<String, String> consumerRecord : consumerRecords) { System.out.println(consumerRecord); } } } }
启动生产者,查看消费数据是可以正常消费的。
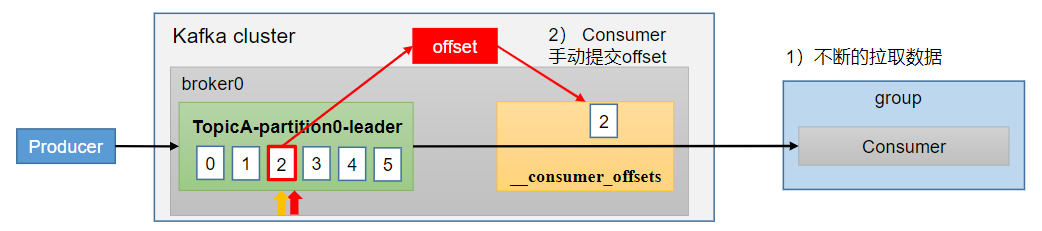
1.3、手动提交offset
虽然自动提交offset十分简单便利,但由于其是基于时间提交的,开发人员难以把握offset提交的时机。因此Kafka还提供了手动提交offset的API。手动提交offset的方法有两种:分别是commitSync(同步提交)和commitAsync(异步提交)。两者的相同点是,都会将本次提交的一批数据最高的偏移量提交;不同点是,同步提交阻塞当前线程,一直到提交成功,并且会自动失败重试(由不可控因素导致,也会出现提交失败);而异步提交则没有失败重试机制,故有可能提交失败
- commitSync(同步提交):必须等待offset提交完毕,再去消费下一批数据。
- commitAsync(异步提交):发送完提交offset请求后,就开始消费下一批数据了。
手动提交示例
import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.common.serialization.StringDeserializer; import java.time.Duration; import java.util.ArrayList; import java.util.Properties; public class CustomeConsumerByHandSync { public static void main(String[] args) { Properties properties = new Properties(); //连接 properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop103:9092,hadoop104:9092,hadoop105:9092"); //反序列化 properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); //配置消费者组ID properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test3"); //设置手动提交 properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false); //创建消费者 KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties); //订阅主题 ArrayList<String> topics = new ArrayList<>(); topics.add("lhc"); kafkaConsumer.subscribe(topics); //消费数据 while (true) { ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1)); for (ConsumerRecord<String, String> consumerRecord : consumerRecords) { System.out.println(consumerRecord); } //手动提交偏移量 同步提交 //kafkaConsumer.commitSync(); //手动提交偏移量 异步提交 kafkaConsumer.commitAsync(); } } }
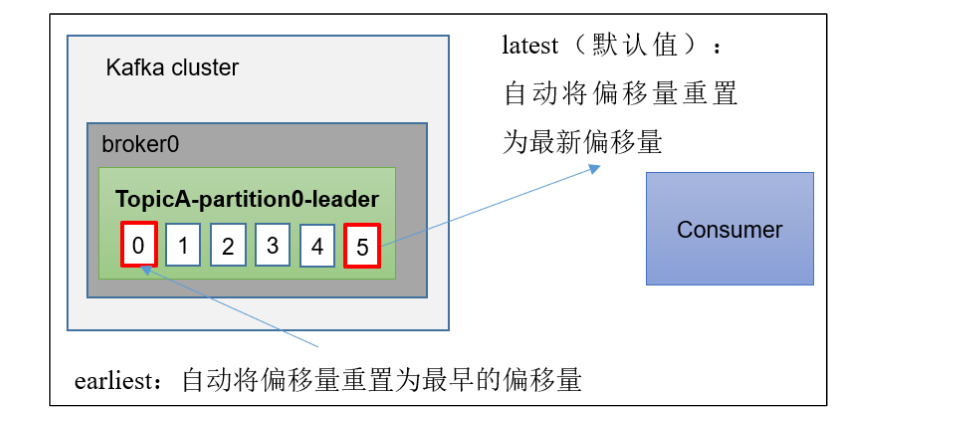
1.4、指定Offset消费
auto.offset.reset= earliest | latest |none 默认是latest。
当Kafka中没有初始偏移量(消费者组第一次消费)或服务器上不再存在当前偏移量时(例如该数据已被删除),该怎么办?
- earliest:自动将偏移量重置为最早的偏移量,--from-beginning。
- latest(默认值):自动将偏移量重置为最新偏移量。
- none:如果未找到消费者组的先前偏移量,则向消费者抛出异常。
任意指定offset位移开始消费
import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.common.TopicPartition; import org.apache.kafka.common.serialization.StringDeserializer; import java.time.Duration; import java.util.ArrayList; import java.util.Properties; import java.util.Set; public class CustomeConsumerSeek { public static void main(String[] args) { Properties properties = new Properties(); //连接 properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop103:9092,hadoop104:9092,hadoop105:9092"); //反序列化 properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); //配置消费者组ID properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test1"); //创建消费者 KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties); //订阅主题 ArrayList<String> topics = new ArrayList<>(); topics.add("tbg"); kafkaConsumer.subscribe(topics); //指定位置进行消费 Set<TopicPartition> assignment = kafkaConsumer.assignment(); //保证分区分配ok while(assignment.size()==0){ kafkaConsumer.poll(Duration.ofSeconds(1)); assignment = kafkaConsumer.assignment(); } for (TopicPartition topicPartition : assignment) { //指定消费 偏移量 60 之后的数据 kafkaConsumer.seek(topicPartition,60); } //消费数据 while (true) { ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1)); for (ConsumerRecord<String, String> consumerRecord : consumerRecords) { System.out.println(consumerRecord); } } } }
注意:每次执行完,需要修改消费者组名才能再次消费之前的数据
1.5、指定时间消费
import org.apache.kafka.clients.consumer.*; import org.apache.kafka.common.TopicPartition; import org.apache.kafka.common.serialization.StringDeserializer; import java.time.Duration; import java.util.*; public class CustomeConsumerSeekTime { public static void main(String[] args) { Properties properties = new Properties(); //连接 properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop103:9092,hadoop104:9092,hadoop105:9092"); //反序列化 properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); //配置消费者组ID properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test1"); //创建消费者 KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties); //订阅主题 ArrayList<String> topics = new ArrayList<>(); topics.add("tbg"); kafkaConsumer.subscribe(topics); Set<TopicPartition> assignment = new HashSet<>(); while (assignment.size() == 0) { kafkaConsumer.poll(Duration.ofSeconds(1)); // 获取消费者分区分配信息(有了分区分配信息才能开始消费) assignment = kafkaConsumer.assignment(); } HashMap<TopicPartition, Long> timestampToSearch = new HashMap<>(); // 封装集合存储,每个分区对应一天前的数据 for (TopicPartition topicPartition : assignment) { timestampToSearch.put(topicPartition, System.currentTimeMillis() - 1 * 24 * 3600 * 1000); } // 获取从1天前开始消费的每个分区的offset Map<TopicPartition, OffsetAndTimestamp> offsets = kafkaConsumer.offsetsForTimes(timestampToSearch); // 遍历每个分区,对每个分区设置消费时间。 for (TopicPartition topicPartition : assignment) { OffsetAndTimestamp offsetAndTimestamp = offsets.get(topicPartition); // 根据时间指定开始消费的位置 if (offsetAndTimestamp != null) { kafkaConsumer.seek(topicPartition, offsetAndTimestamp.offset()); } } //消费数据 while (true) { ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1)); for (ConsumerRecord<String, String> consumerRecord : consumerRecords) { System.out.println(consumerRecord); } } } }
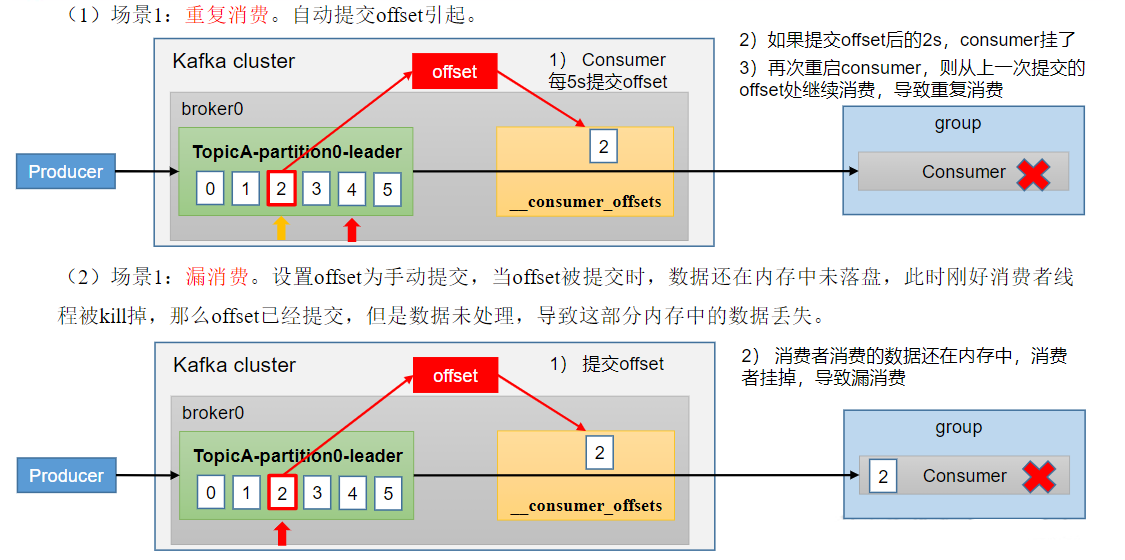
1.6、漏消费和重复消费
重复消费:已经消费了数据,但是offset没提交。
漏消费:先提交offset后消费,有可能会造成数据的漏消费。
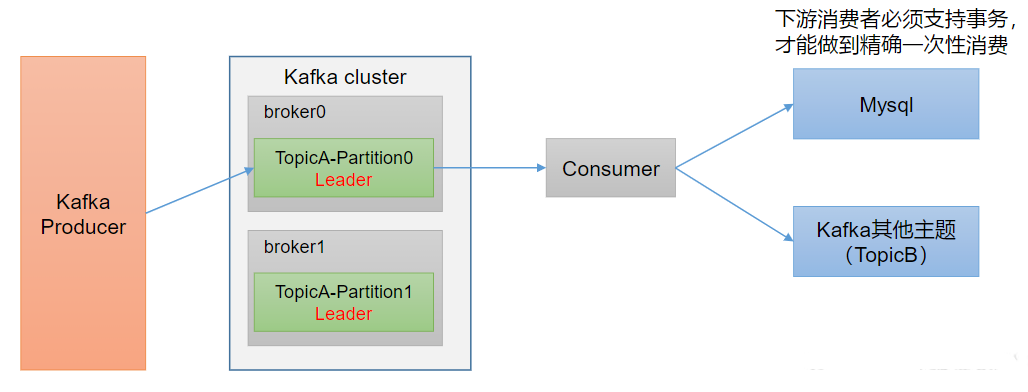
2、消费者事务
如果想完成Consumer端的精准一次性消费,那么需要Kafka消费端将消费过程和提交offset过程做原子绑定。此时我们需要将Kafka的offset保存到支持事务的自定义介质(比如MySQL)。
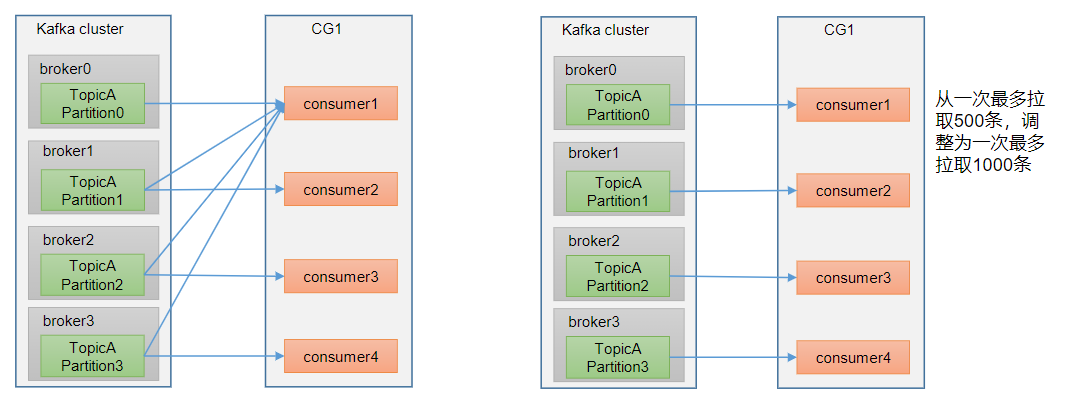
3、提高消费者吞吐量
- 如果是Kafka消费能力不足,则可以考虑增加Topic的分区数,并且同时提升消费组的消费者数量,消费者数=分区数。(两者缺一不可)
- 如果是下游的数据处理不及时:提高每批次拉取的数量。批次拉取数据过少(拉取数据/处理时间<生产速度),使处理的数据小于生产的数据,也会造成数据积压。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号