Kafka 消费者(一)
1、kafka 消费方式
- pull(拉)模式:Kafka 消费方式消费速度:10m/s消费速度:20m/s消费速度:50m/s➢push(推)模式:consumer采用从broker中主动拉取数据。Kafka采用这种方式。
- push(推)模式:Kafka没有采用这种方式,因为由broker决定消息发送速率,很难适应所有消费者的消费速率。例如推送的速度是50m/s,Consumer1、Consumer2就来不及处理消息。

2、kafka 消费者工作流程
2.1、消费者总体工作流程
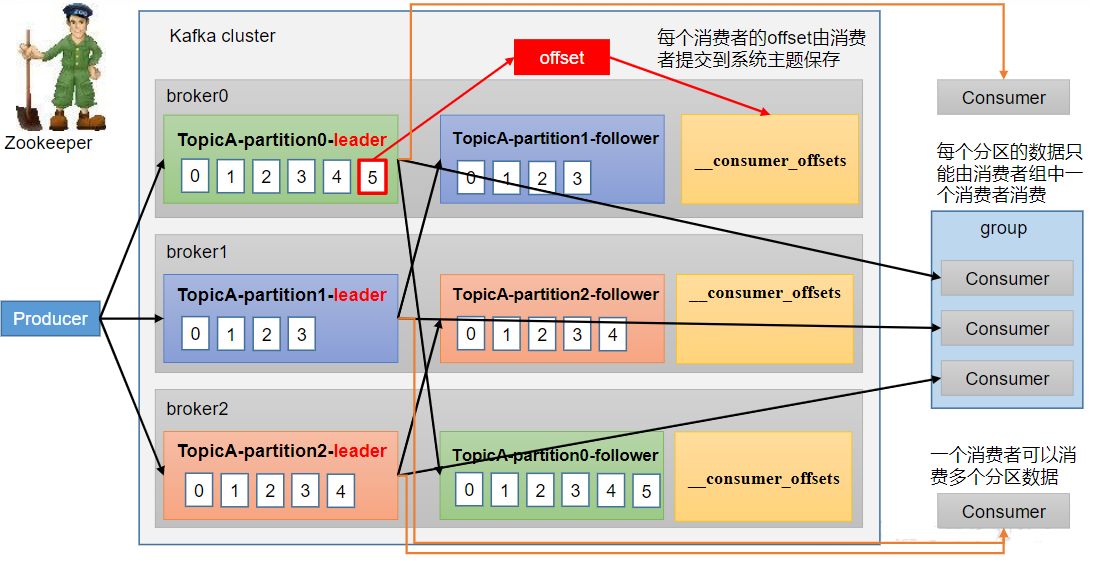
2.2、消费者组原理
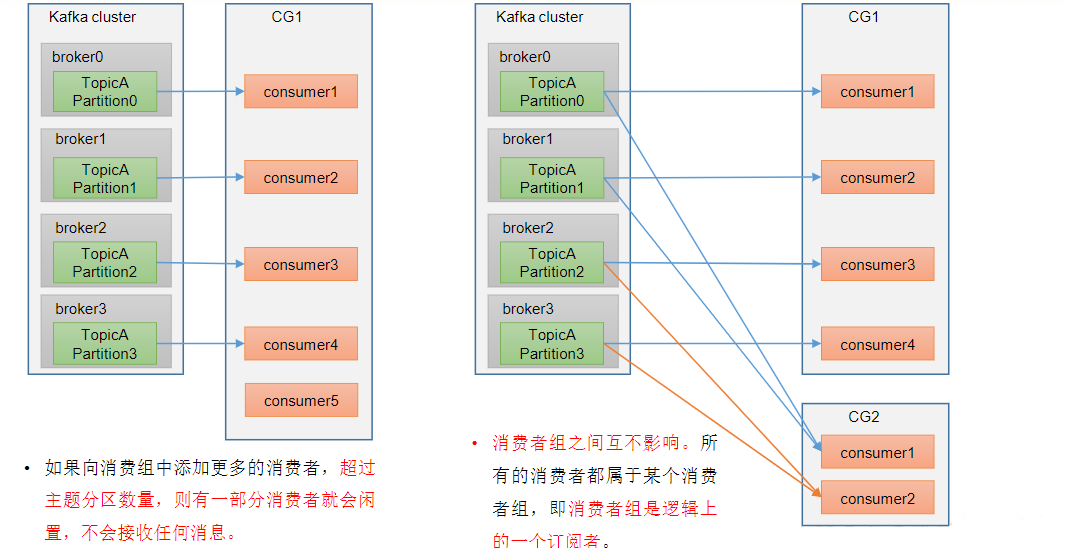
ConsumerGroup(CG):消费者组,由多个consumer组成。形成一个消费者组的条件,是所有消费者的groupid相同。
- 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费。
- 消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者

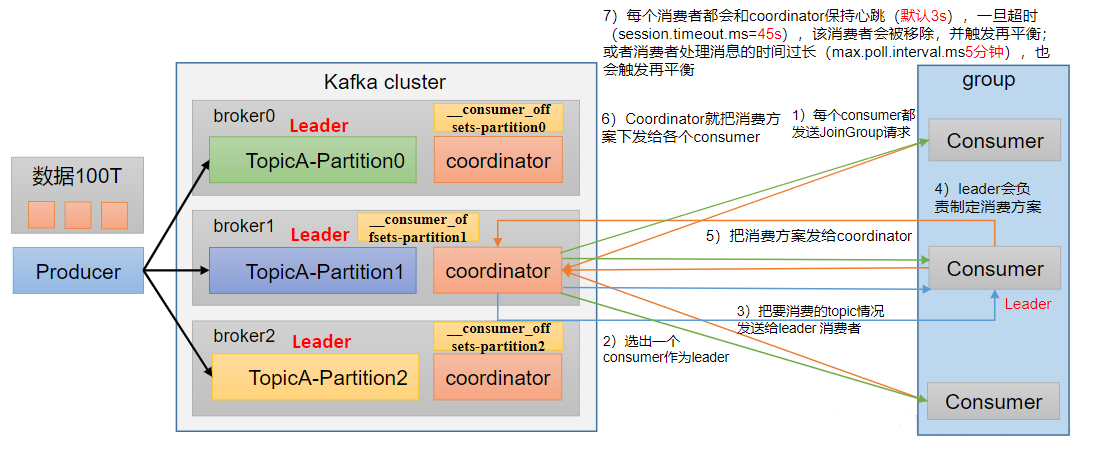
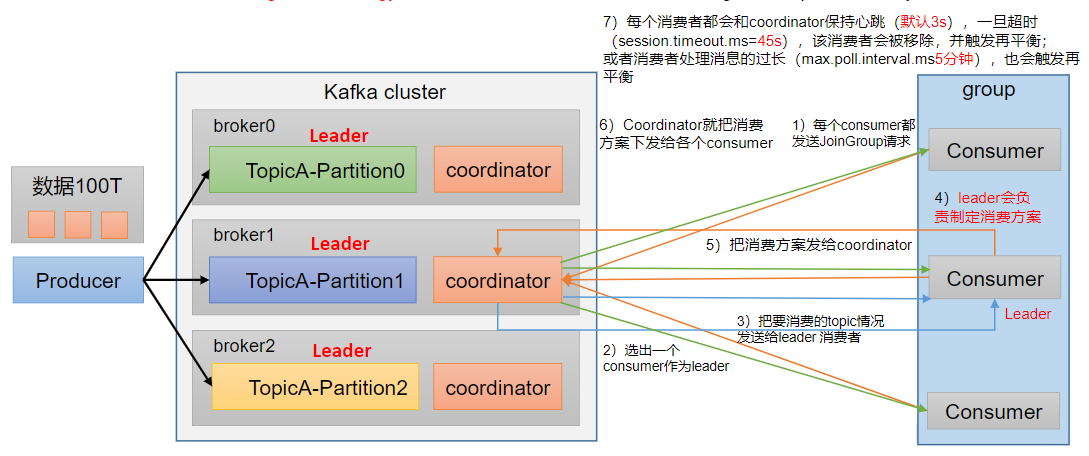
消费者初始化流程
coordinator:辅助实现消费者组的初始化和分区的分配。coordinator节点选择= groupid的hashcode值% 50(__consumer_offsets的分区数量)例如:groupid的hashcode值= 1,1% 50 = 1,那么__consumer_offsets主题的1号分区,在哪个broker上,就选择这个节点的coordinator作为这个消费者组的老大。消费者组下的所有的消费者提交offset的时候就往这个分区去提交offset。
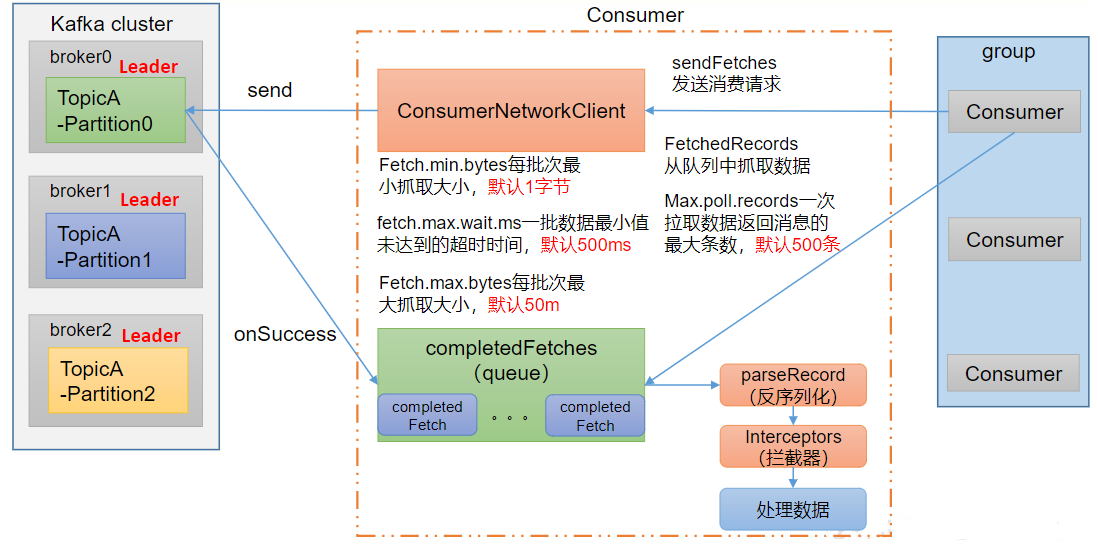
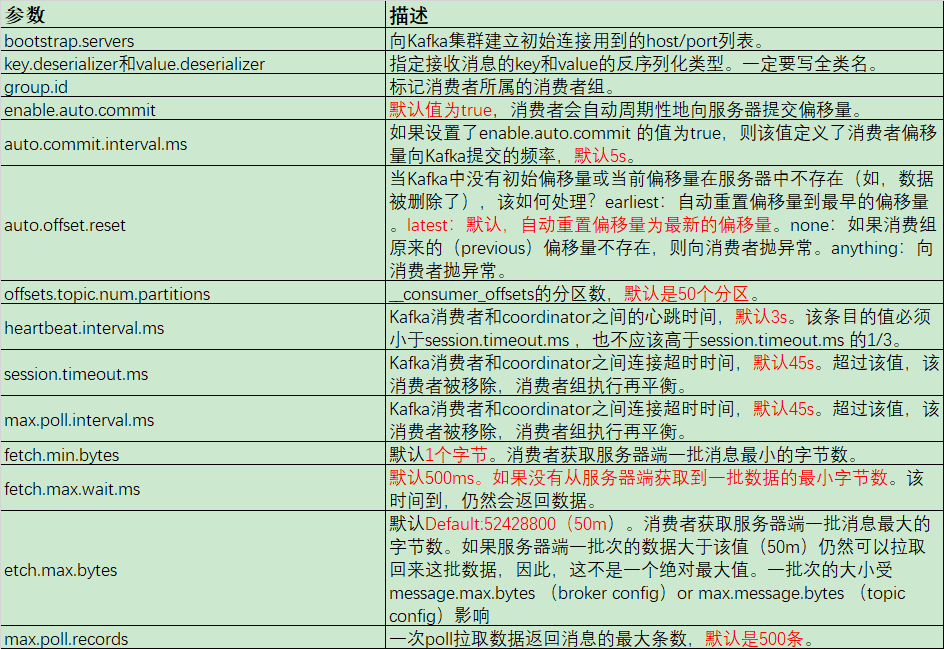
2.3、消费者参数
3、消费者API
3.1、独立消费者案例(订阅主题)
创建一个独立消费者,消费 lhc 主题中数据。
注意:在消费者API代码中必须配置消费者组id。命令行启动消费者不填写消费者组id会被自动填写随机的消费者组id。


import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.common.serialization.StringDeserializer; import java.time.Duration; import java.util.ArrayList; import java.util.Properties; public class CustomeConsumer { public static void main(String[] args) { Properties properties = new Properties(); //连接 properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop103:9092,hadoop104:9092,hadoop105:9092"); //反序列化 properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); //配置消费者组ID properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test"); //创建消费者 KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties); //订阅主题 ArrayList<String> topics = new ArrayList<>(); topics.add("lhc"); kafkaConsumer.subscribe(topics); //消费数据 while (true) { ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1)); for (ConsumerRecord<String, String> consumerRecord : consumerRecords) { System.out.println(consumerRecord); } } } }
运行之前的生成者代码
import org.apache.kafka.clients.producer.*; import org.apache.kafka.common.serialization.StringSerializer; import java.util.Properties; public class CustomProducerCallBack { public static void main(String[] args) throws InterruptedException { Properties properties = new Properties(); //连接ZK properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop103:9092,hadoop104:9092,hadoop105:9092"); //设置KV序列化 properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); //指定 kv 的序列化类型 //1、创建 生产者 KafkaProducer<String, String> KafkaProducer = new KafkaProducer<String, String>(properties); //2、发送数据 put异步发送 for (int i = 0; i < 5; i++) { KafkaProducer.send(new ProducerRecord<>("lhc", i + " hello wdh01"), new Callback() { // new Callback( 回调函数 @Override public void onCompletion(RecordMetadata metadata, Exception exception) { if (exception == null) { System.out.println("主题 " + metadata.topic() + " 分区 " + metadata.partition()); } } }); Thread.sleep(1); } //3、关闭资源 KafkaProducer.close(); } }
主题 lhc 分区 2 主题 lhc 分区 2 主题 lhc 分区 2 主题 lhc 分区 2 主题 lhc 分区 2
消费结果
ConsumerRecord(topic = lhc, partition = 2, leaderEpoch = 3, offset = 0, CreateTime = 1649064284368, serialized key size = -1, serialized value size = 14, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 0 hello wdh01) ConsumerRecord(topic = lhc, partition = 2, leaderEpoch = 3, offset = 1, CreateTime = 1649064284483, serialized key size = -1, serialized value size = 14, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 1 hello wdh01) ConsumerRecord(topic = lhc, partition = 2, leaderEpoch = 3, offset = 2, CreateTime = 1649064284485, serialized key size = -1, serialized value size = 14, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 2 hello wdh01) ConsumerRecord(topic = lhc, partition = 2, leaderEpoch = 3, offset = 3, CreateTime = 1649064284488, serialized key size = -1, serialized value size = 14, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 3 hello wdh01) ConsumerRecord(topic = lhc, partition = 2, leaderEpoch = 3, offset = 4, CreateTime = 1649064284490, serialized key size = -1, serialized value size = 14, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 4 hello wdh01)
3.2、 独立消费者案例(订阅分区)
创建一个独立消费者,消费 lhc 主题0号分区的数据
import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.common.TopicPartition; import org.apache.kafka.common.serialization.StringDeserializer; import java.time.Duration; import java.util.ArrayList; import java.util.Properties; public class CustomeConsumerPartition { public static void main(String[] args) { Properties properties = new Properties(); //连接 properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop103:9092,hadoop104:9092,hadoop105:9092"); //反序列化 properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); //设置消费者组ID properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test"); //创建消费者对象 KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties); //注册消费主题&指定消费的分区 ArrayList<TopicPartition> topicPartitions = new ArrayList<>(); topicPartitions.add(new TopicPartition("lhc", 0)); kafkaConsumer.assign(topicPartitions); while (true) { ConsumerRecords<String, String> poll = kafkaConsumer.poll(Duration.ofSeconds(1)); for (ConsumerRecord<String, String> stringStringConsumerRecord : poll) { System.out.println(stringStringConsumerRecord); } } } }
运行
import org.apache.kafka.clients.producer.*; import org.apache.kafka.common.serialization.StringSerializer; import java.util.Properties; public class CustomProducerCallBackPartitions { public static void main(String[] args) throws InterruptedException { Properties properties = new Properties(); //连接ZK properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop103:9092,hadoop104:9092"); //设置KV序列化 properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); //指定 kv 的序列化类型 //1、创建 生产者 KafkaProducer<String, String> KafkaProducer = new KafkaProducer<String, String>(properties); //2、发送数据 put异步发送 for (int i = 0; i < 5; i++) { KafkaProducer.send(new ProducerRecord<>("lhc", 0, "", i + " hello wdh01 a "), new Callback() { // new Callback( 回调函数 @Override public void onCompletion(RecordMetadata metadata, Exception exception) { if (exception == null) { System.out.println(" a 主题 " + metadata.topic() + " 分区 " + metadata.partition()); } } }); } //3、关闭资源 KafkaProducer.close(); } }
观察消费结果
ConsumerRecord(topic = lhc, partition = 0, leaderEpoch = 1, offset = 0, CreateTime = 1649064682468, serialized key size = 0, serialized value size = 17, headers = RecordHeaders(headers = [], isReadOnly = false), key = , value = 0 hello wdh01 a ) ConsumerRecord(topic = lhc, partition = 0, leaderEpoch = 1, offset = 1, CreateTime = 1649064682503, serialized key size = 0, serialized value size = 17, headers = RecordHeaders(headers = [], isReadOnly = false), key = , value = 1 hello wdh01 a ) ConsumerRecord(topic = lhc, partition = 0, leaderEpoch = 1, offset = 2, CreateTime = 1649064682503, serialized key size = 0, serialized value size = 17, headers = RecordHeaders(headers = [], isReadOnly = false), key = , value = 2 hello wdh01 a ) ConsumerRecord(topic = lhc, partition = 0, leaderEpoch = 1, offset = 3, CreateTime = 1649064682503, serialized key size = 0, serialized value size = 17, headers = RecordHeaders(headers = [], isReadOnly = false), key = , value = 3 hello wdh01 a ) ConsumerRecord(topic = lhc, partition = 0, leaderEpoch = 1, offset = 4, CreateTime = 1649064682503, serialized key size = 0, serialized value size = 17, headers = RecordHeaders(headers = [], isReadOnly = false), key = , value = 4 hello wdh01 a )
3.3、消费者组案例
测试同一个主题的分区数据,只能由一个消费者组中的一个消费。
复制2份基础消费者的代码,在IDEA中同时启动,即可启动同一个消费者组中的3个消费者。
运行生产者
import org.apache.kafka.clients.producer.*; import org.apache.kafka.common.serialization.StringSerializer; import java.util.Properties; public class CustomProducerCallBack { public static void main(String[] args) throws InterruptedException { Properties properties = new Properties(); //连接ZK properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop103:9092,hadoop104:9092,hadoop105:9092"); //设置KV序列化 properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); //指定 kv 的序列化类型 //1、创建 生产者 KafkaProducer<String, String> KafkaProducer = new KafkaProducer<String, String>(properties); //2、发送数据 put异步发送 for (int i = 0; i < 50; i++) { KafkaProducer.send(new ProducerRecord<>("lhc", i + " hello wdh01"), new Callback() { // new Callback( 回调函数 @Override public void onCompletion(RecordMetadata metadata, Exception exception) { if (exception == null) { System.out.println("主题 " + metadata.topic() + " 分区 " + metadata.partition()); } } }); Thread.sleep(1); } //3、关闭资源 KafkaProducer.close(); } }
生产者数据发往了三个分区
主题 lhc 分区 2 主题 lhc 分区 2 主题 lhc 分区 2 主题 lhc 分区 2 主题 lhc 分区 2 主题 lhc 分区 2 主题 lhc 分区 2 主题 lhc 分区 1 主题 lhc 分区 1 主题 lhc 分区 1 主题 lhc 分区 1 主题 lhc 分区 1 主题 lhc 分区 1 主题 lhc 分区 1 主题 lhc 分区 1 主题 lhc 分区 1 主题 lhc 分区 1 主题 lhc 分区 1 主题 lhc 分区 1 主题 lhc 分区 2 主题 lhc 分区 1 主题 lhc 分区 2 主题 lhc 分区 0 主题 lhc 分区 1 主题 lhc 分区 0 主题 lhc 分区 0 主题 lhc 分区 0 主题 lhc 分区 0 主题 lhc 分区 0 主题 lhc 分区 0 主题 lhc 分区 0 主题 lhc 分区 0 主题 lhc 分区 0 主题 lhc 分区 0 主题 lhc 分区 0 主题 lhc 分区 0 主题 lhc 分区 0 主题 lhc 分区 0 主题 lhc 分区 0 主题 lhc 分区 0 主题 lhc 分区 0 主题 lhc 分区 0 主题 lhc 分区 0 主题 lhc 分区 0 主题 lhc 分区 0 主题 lhc 分区 0 主题 lhc 分区 0 主题 lhc 分区 0 主题 lhc 分区 0 主题 lhc 分区 0
消费0号分区
ConsumerRecord(topic = lhc, partition = 0, leaderEpoch = 1, offset = 5, CreateTime = 1649064880655, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 20 hello wdh01) ConsumerRecord(topic = lhc, partition = 0, leaderEpoch = 1, offset = 6, CreateTime = 1649064880662, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 23 hello wdh01) ConsumerRecord(topic = lhc, partition = 0, leaderEpoch = 1, offset = 7, CreateTime = 1649064880669, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 25 hello wdh01) ConsumerRecord(topic = lhc, partition = 0, leaderEpoch = 1, offset = 8, CreateTime = 1649064880694, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 26 hello wdh01) ConsumerRecord(topic = lhc, partition = 0, leaderEpoch = 1, offset = 9, CreateTime = 1649064880696, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 27 hello wdh01) ConsumerRecord(topic = lhc, partition = 0, leaderEpoch = 1, offset = 10, CreateTime = 1649064880704, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 28 hello wdh01) ConsumerRecord(topic = lhc, partition = 0, leaderEpoch = 1, offset = 11, CreateTime = 1649064880706, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 29 hello wdh01) ConsumerRecord(topic = lhc, partition = 0, leaderEpoch = 1, offset = 12, CreateTime = 1649064880708, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 30 hello wdh01) ConsumerRecord(topic = lhc, partition = 0, leaderEpoch = 1, offset = 13, CreateTime = 1649064880710, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 31 hello wdh01) ConsumerRecord(topic = lhc, partition = 0, leaderEpoch = 1, offset = 14, CreateTime = 1649064880712, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 32 hello wdh01) ConsumerRecord(topic = lhc, partition = 0, leaderEpoch = 1, offset = 15, CreateTime = 1649064880714, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 33 hello wdh01) ConsumerRecord(topic = lhc, partition = 0, leaderEpoch = 1, offset = 16, CreateTime = 1649064880716, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 34 hello wdh01) ConsumerRecord(topic = lhc, partition = 0, leaderEpoch = 1, offset = 17, CreateTime = 1649064880719, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 35 hello wdh01) ConsumerRecord(topic = lhc, partition = 0, leaderEpoch = 1, offset = 18, CreateTime = 1649064880722, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 36 hello wdh01) ConsumerRecord(topic = lhc, partition = 0, leaderEpoch = 1, offset = 19, CreateTime = 1649064880724, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 37 hello wdh01) ConsumerRecord(topic = lhc, partition = 0, leaderEpoch = 1, offset = 20, CreateTime = 1649064880726, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 38 hello wdh01) ConsumerRecord(topic = lhc, partition = 0, leaderEpoch = 1, offset = 21, CreateTime = 1649064880728, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 39 hello wdh01) ConsumerRecord(topic = lhc, partition = 0, leaderEpoch = 1, offset = 22, CreateTime = 1649064880730, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 40 hello wdh01) ConsumerRecord(topic = lhc, partition = 0, leaderEpoch = 1, offset = 23, CreateTime = 1649064880732, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 41 hello wdh01) ConsumerRecord(topic = lhc, partition = 0, leaderEpoch = 1, offset = 24, CreateTime = 1649064880734, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 42 hello wdh01) ConsumerRecord(topic = lhc, partition = 0, leaderEpoch = 1, offset = 25, CreateTime = 1649064880736, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 43 hello wdh01) ConsumerRecord(topic = lhc, partition = 0, leaderEpoch = 1, offset = 26, CreateTime = 1649064880737, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 44 hello wdh01) ConsumerRecord(topic = lhc, partition = 0, leaderEpoch = 1, offset = 27, CreateTime = 1649064880738, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 45 hello wdh01) ConsumerRecord(topic = lhc, partition = 0, leaderEpoch = 1, offset = 28, CreateTime = 1649064880739, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 46 hello wdh01) ConsumerRecord(topic = lhc, partition = 0, leaderEpoch = 1, offset = 29, CreateTime = 1649064880741, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 47 hello wdh01) ConsumerRecord(topic = lhc, partition = 0, leaderEpoch = 1, offset = 30, CreateTime = 1649064880743, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 48 hello wdh01) ConsumerRecord(topic = lhc, partition = 0, leaderEpoch = 1, offset = 31, CreateTime = 1649064880744, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 49 hello wdh01)
消费1号分区
ConsumerRecord(topic = lhc, partition = 1, leaderEpoch = 2, offset = 0, CreateTime = 1649064880519, serialized key size = -1, serialized value size = 14, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 0 hello wdh01) ConsumerRecord(topic = lhc, partition = 1, leaderEpoch = 2, offset = 1, CreateTime = 1649064880565, serialized key size = -1, serialized value size = 14, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 1 hello wdh01) ConsumerRecord(topic = lhc, partition = 1, leaderEpoch = 2, offset = 2, CreateTime = 1649064880567, serialized key size = -1, serialized value size = 14, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 2 hello wdh01) ConsumerRecord(topic = lhc, partition = 1, leaderEpoch = 2, offset = 3, CreateTime = 1649064880570, serialized key size = -1, serialized value size = 14, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 3 hello wdh01) ConsumerRecord(topic = lhc, partition = 1, leaderEpoch = 2, offset = 4, CreateTime = 1649064880572, serialized key size = -1, serialized value size = 14, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 4 hello wdh01) ConsumerRecord(topic = lhc, partition = 1, leaderEpoch = 2, offset = 5, CreateTime = 1649064880577, serialized key size = -1, serialized value size = 14, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 5 hello wdh01) ConsumerRecord(topic = lhc, partition = 1, leaderEpoch = 2, offset = 6, CreateTime = 1649064880579, serialized key size = -1, serialized value size = 14, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 6 hello wdh01) ConsumerRecord(topic = lhc, partition = 1, leaderEpoch = 2, offset = 7, CreateTime = 1649064880585, serialized key size = -1, serialized value size = 14, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 7 hello wdh01) ConsumerRecord(topic = lhc, partition = 1, leaderEpoch = 2, offset = 8, CreateTime = 1649064880592, serialized key size = -1, serialized value size = 14, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 8 hello wdh01) ConsumerRecord(topic = lhc, partition = 1, leaderEpoch = 2, offset = 9, CreateTime = 1649064880593, serialized key size = -1, serialized value size = 14, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 9 hello wdh01) ConsumerRecord(topic = lhc, partition = 1, leaderEpoch = 2, offset = 10, CreateTime = 1649064880595, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 10 hello wdh01) ConsumerRecord(topic = lhc, partition = 1, leaderEpoch = 2, offset = 11, CreateTime = 1649064880597, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 11 hello wdh01) ConsumerRecord(topic = lhc, partition = 1, leaderEpoch = 2, offset = 12, CreateTime = 1649064880652, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 19 hello wdh01) ConsumerRecord(topic = lhc, partition = 1, leaderEpoch = 2, offset = 13, CreateTime = 1649064880657, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 21 hello wdh01)
消费2号分区
ConsumerRecord(topic = lhc, partition = 2, leaderEpoch = 3, offset = 5, CreateTime = 1649064880601, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 12 hello wdh01) ConsumerRecord(topic = lhc, partition = 2, leaderEpoch = 3, offset = 6, CreateTime = 1649064880609, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 13 hello wdh01) ConsumerRecord(topic = lhc, partition = 2, leaderEpoch = 3, offset = 7, CreateTime = 1649064880613, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 14 hello wdh01) ConsumerRecord(topic = lhc, partition = 2, leaderEpoch = 3, offset = 8, CreateTime = 1649064880646, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 15 hello wdh01) ConsumerRecord(topic = lhc, partition = 2, leaderEpoch = 3, offset = 9, CreateTime = 1649064880648, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 16 hello wdh01) ConsumerRecord(topic = lhc, partition = 2, leaderEpoch = 3, offset = 10, CreateTime = 1649064880649, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 17 hello wdh01) ConsumerRecord(topic = lhc, partition = 2, leaderEpoch = 3, offset = 11, CreateTime = 1649064880650, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 18 hello wdh01) ConsumerRecord(topic = lhc, partition = 2, leaderEpoch = 3, offset = 12, CreateTime = 1649064880660, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 22 hello wdh01) ConsumerRecord(topic = lhc, partition = 2, leaderEpoch = 3, offset = 13, CreateTime = 1649064880667, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 24 hello wdh01)
4、分区的分配以及再平衡
- 一个consumer group中有多个consumer组成,一个topic有多个partition组成,现在的问题是,到底由哪个consumer来消费哪个partition的数据。
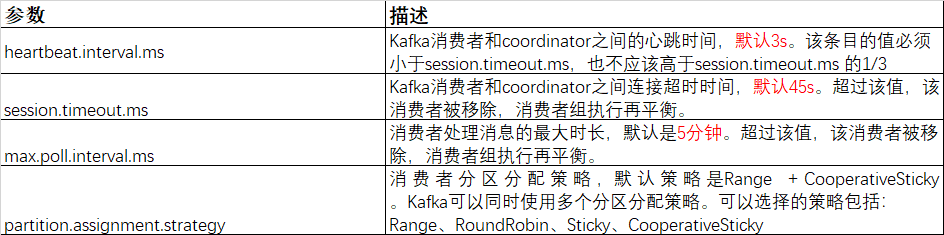
- Kafka有四种主流的分区分配策略:Range、RoundRobin、Sticky、CooperativeSticky。可以通过配置参数partition.assignment.strategy,修改分区的分配策略。默认策略是Range + CooperativeSticky。Kafka可以同时使用多个分区分配策略。
4.1、Range以及再平衡
Range 是对每个topic 而言的。首先对同一个topic 里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序。假如现在有7 个分区,3 个消费者,排序后的分区将会是0,1,2,3,4,5,6;消费者排序完之后将会是C0,C1,C2。例如,7/3 = 2 余1 ,除不尽,那么消费者C0 便会多消费1 个分区。8/3=2余2,除不尽,那么C0和C1分别多消费一个。通过partitions数/consumer数来决定每个消费者应该消费几个分区。如果除不尽,那么前面几个消费者将会多消费1 个分区。注意:如果只是针对1 个topic 而言,C0消费者多消费1个分区影响不是很大。但是如果有N 多个topic,那么针对每个topic,消费者C0都将多消费1 个分区,topic越多,C0消费的分区会比其他消费者明显多消费N 个分区。容易产生数据倾斜!
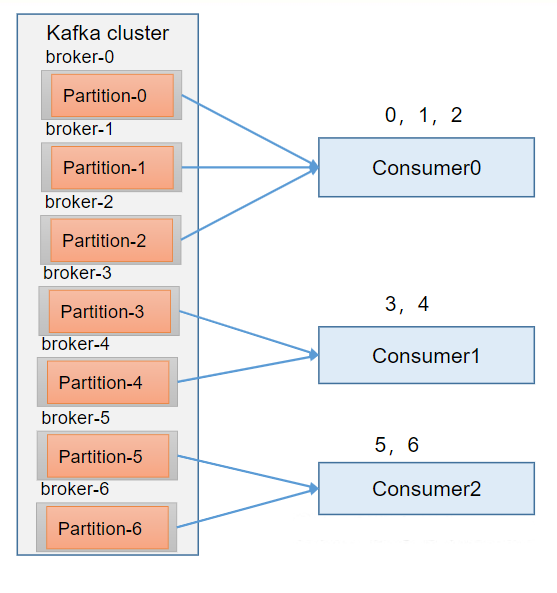
Range分区分配策略案例
修改主题 lhc 为7个分区
[hui@hadoop103 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop103:9092 --alter --topic lhc --partitions 7 [hui@hadoop103 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop103:9092 --describe --topic lhc Topic: lhc TopicId: rf7bjcn0RfqOXhqSCwKqZw PartitionCount: 7 ReplicationFactor: 2 Configs: segment.bytes=1073741824 Topic: lhc Partition: 0 Leader: 2 Replicas: 2,0 Isr: 2,0 Topic: lhc Partition: 1 Leader: 2 Replicas: 1,2 Isr: 2,1 Topic: lhc Partition: 2 Leader: 1 Replicas: 0,1 Isr: 1,0 Topic: lhc Partition: 3 Leader: 2 Replicas: 2,1 Isr: 2,1 Topic: lhc Partition: 4 Leader: 0 Replicas: 0,2 Isr: 0,2 Topic: lhc Partition: 5 Leader: 1 Replicas: 1,0 Isr: 1,0 Topic: lhc Partition: 6 Leader: 2 Replicas: 2,0 Isr: 2,0
启动三个消费者、一个生产者发送100条消息,查看消费结果
生产者逻辑
import org.apache.kafka.clients.producer.*; import org.apache.kafka.common.serialization.StringSerializer; import java.util.Properties; public class CustomProducerCallBack { public static void main(String[] args) throws InterruptedException { Properties properties = new Properties(); //连接ZK properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop103:9092,hadoop104:9092,hadoop105:9092"); //设置KV序列化 properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); //指定 kv 的序列化类型 //1、创建 生产者 KafkaProducer<String, String> KafkaProducer = new KafkaProducer<String, String>(properties); //2、发送数据 put异步发送 for (int i = 0; i < 500; i++) { KafkaProducer.send(new ProducerRecord<>("lhc", i + " hello wdh01"), new Callback() { // new Callback( 回调函数 @Override public void onCompletion(RecordMetadata metadata, Exception exception) { if (exception == null) { System.out.println("主题 " + metadata.topic() + " 分区 " + metadata.partition()); } } }); Thread.sleep(1); } //3、关闭资源 KafkaProducer.close(); } }
消费者0 消费了 0 1 2 分区

消费者1 消费了 5 6 两个分区

消费者 2 消费 3 4 分区

现在把 消费者0 停掉,45s 内再生成一批消息,观察 消费者 1 2 的消费情况,已停止消费者0

发现消费者1 消费的还是 分区 5 6

其余的分区都被消费者2消费了


 再次启动生产者,此时观察 消费1 消费者2 的消费情况
再次启动生产者,此时观察 消费1 消费者2 的消费情况
消费者1 消费了 4 5 6
 消费者2消费了0 1 2 3
消费者2消费了0 1 2 3 
Range分区分配再平衡案例
(1)停止掉0号消费者,快速重新发送消息观看结果(45s以内,越快越好)。
1号消费者:消费到5、6号分区数据。
2号消费者:消费到5、6号分区数据。0号消费者的任务会整体被分配到1号消费者或者2号消费者。
说明:0号消费者挂掉后,消费者组需要按照超时时间45s来判断它是否退出,所以需要等待,时间到了45s后,判断它真的退出就会把任务分配给其他broker执行。
(2)再次重新发送消息观看结果(45s以后)。1号消费者:消费到4、5、2 6号分区数据。
2号消费者:消费到0、1、2、3号分区数据。
说明:消费者0已经被踢出消费者组,所以重新按照range方式分配。
4.2 RoundRobin以及再平衡
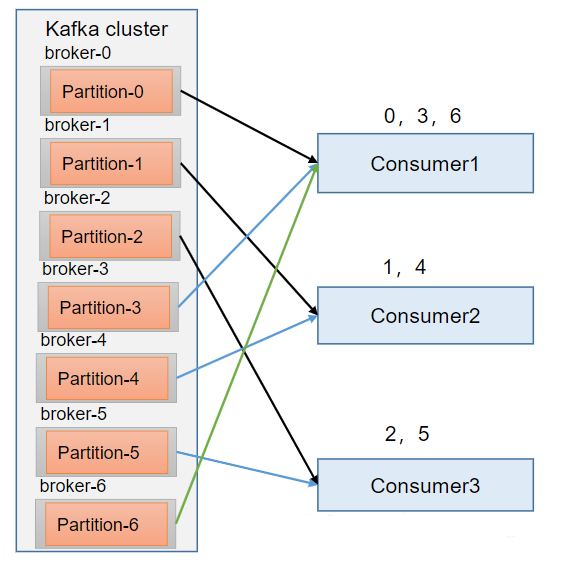
RoundRobin针对集群中所有Topic而言。RoundRobin轮询分区策略,是把所有的partition 和所有的consumer 都列出来,然后按照hashcode进行排序,最后通过轮询算法来分配partition 给到各个消费者。
消费者配置修改分区策略



RoundRobin分区分配再平衡案例(1)停止掉0号消费者,快速重新发送消息观看结果(45s以内,越快越好)。1号消费者:消费到2、5号分区数据2号消费者:消费到4、1号分区数据0号消费者的任务会按照RoundRobin的方式,把数据轮询分成0、6和3号分区数据,分别由1号消费者或者2号消费者消费。说明:0号消费者挂掉后,消费者组需要按照超时时间45s来判断它是否退出,所以需要等待,时间到了45s后,判断它真的退出就会把任务分配给其他broker执行。(2)再次重新发送消息观看结果(45s以后)。1号消费者:消费到0、2、4、6号分区数据2号消费者:消费到1、3、5号分区数据说明:消费者0已经被踢出消费者组,所以重新按照RoundRobin方式分配
4.3 Sticky以及再平衡
粘性分区定义:可以理解为分配的结果带有“粘性的”。即在执行一次新的分配之前,考虑上一次分配的结果,尽量少的调整分配的变动,可以节省大量的开销。粘性分区是Kafka从0.11.x版本开始引入这种分配策略,首先会尽量均衡的放置分区到消费者上面,在出现同一消费者组内消费者出现问题的时候,会尽量保持原有分配的分区不变化。
修改策略
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, "org.apache.kafka.clients.consumer.StickyAssignor");


Sticky分区分配再平衡案例(1)停止掉0号消费者,快速重新发送消息观看结果(45s以内,越快越好)。1号消费者:消费到2、5、3号分区数据。2号消费者:消费到4、6号分区数据。0号消费者的任务会按照粘性规则,尽可能均衡的随机分成0和1号分区数据,分别由1号消费者或者2号消费者消费。说明:0号消费者挂掉后,消费者组需要按照超时时间45s来判断它是否退出,所以需要等待,时间到了45s后,判断它真的退出就会把任务分配给其他broker执行。(2)再次重新发送消息观看结果(45s以后)。1号消费者:消费到2、3、5号分区数据。2号消费者:消费到0、1、4、6号分区数据。说明:消费者0已经被踢出消费者组,所以重新按照粘性方式分配。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号