Flink 物理分区
分区概述
分区是大数据处理中一个非常重要的一环。分区是将数据进行重新分布,传输到不同的通道进行下一步数据处理。之前在进行 wordcount 的时候已经使用过有关分区的算子 keyby,keiby 是按照键的哈希值进行的重分区操作。
KeyedStream<Tuple2<String, Long>, String> keyedDS = wordToOneDS.keyBy(data -> data.f0);//按照第一个远程 进行分组
这种分区只能把数据按 key 分开,至于分的均匀与否,每个key的数据具体会分到哪一个区,这些是无法控制的(原因是不能保证待分区数据key 是否均匀分布),因此将 keyby 称之为逻辑分区(软分区)。真正的硬核分区称之为物理分区。也就是我们真正要控制的分区策略,精准的调配数据,通知每个数据要去哪个分区进行处理,其实这种分区在之前已经使用过了,即设置任务的并行度,如果上下设置不同的并行度,那么当数据执行上下游任务并行度变化时,数据就不应该还在当前的分区直通(forward)方式传输,如果并行度减小,当前分区可能没有下游任务,如果并行度增大,所有数据还在原有的分区处理就会导致资源浪费。所以这种情况,系统会自动的将数据均匀的发往下游所有的并行任务,从而保证各分区负载均衡。
有些时候,我们还需要手动控制数据分区分配策略。比如当发生数据倾斜的时候,系统无法自动调整,这时就需要我们重新进行负载均衡,将数据流较为平均地发送到下游任务操作分区中去。Flink对于经过转换操作之后的DataStream,提供了一系列的底层操作接口,能够帮我们实现数据流的手动重分区。为了同keyBy相区别,我们把这些操作统称为“物理分区”操作。物理分区与keyBy另一大区别在于,keyBy之后得到的是一个KeyedStream,而物理分区之后结果仍是DataStream,且流中元素数据类型保持不变。从这一点也可以看出,分区算子并不对数据进行转换处理,只是定义了数据的传输方式。常见的物理分区策略有随机分配(Random)、轮询分配(Round-Robin)、重缩放(Rescale)和广播(Broadcast)
物理分区
数据准备,我们现在拿几个对象为例,读取一些POJO,并且做一个简单的转换返回用户的名称,来验证几个分区策略
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); //从元素中读取数据 DataStreamSource<Event> elementStream = //直接构建对象进行读取数据 env.fromElements(new Event("令狐冲", "./cart", 1000L), new Event("依琳", "./pro?id191", 3200L), new Event("任盈盈", "./pro?id101", 3000L), new Event("依琳", "./home", 6300L), new Event("任盈盈", "./cart", 3500L), new Event("依琳", "./home", 6900L), new Event("令狐冲", "./home", 2000L), new Event("依琳", "./cart", 6500L));
方式一 随机分区(shuffle)
最简单的重分区方式就是直接“洗牌”。通过调用DataStream的.shuffle()方法,将数据随机地分配到下游算子的并行任务中去。100随机分区服从均匀分布(uniform distribution),所以可以把流中的数据随机打乱,均匀地传递到下游任务分区。因为是完全随机的,所以对于同样的输入数据, 每次执行得到的结果也不会相同
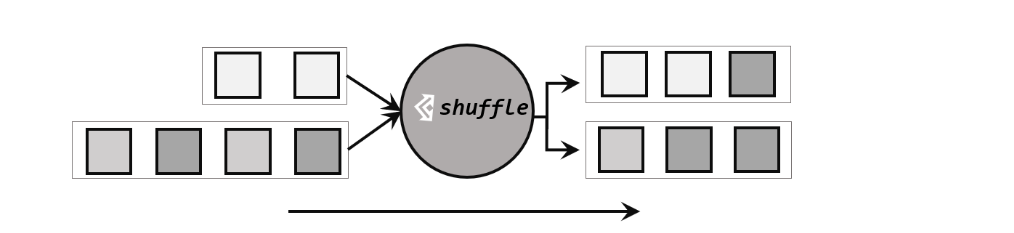
经过随机分区之后,得到的依然是一个DataStream。我们可以做个简单测试:将数据读入之后直接打印到控制台,将输出的并行度设置为4,中间经历一次shuffle。执行多次,观察结果是否相同。
elementStream.shuffle().print("shuffle--").setParallelism(4);
第一次执行结果
shuffle--:2> Event{user='令狐冲', url='./cart', timestamp=1970-01-01 08:00:01.0}
shuffle--:3> Event{user='任盈盈', url='./cart', timestamp=1970-01-01 08:00:03.5}
shuffle--:2> Event{user='依琳', url='./pro?id191', timestamp=1970-01-01 08:00:03.2}
shuffle--:2> Event{user='依琳', url='./home', timestamp=1970-01-01 08:00:06.3}
shuffle--:1> Event{user='任盈盈', url='./pro?id101', timestamp=1970-01-01 08:00:03.0}
shuffle--:3> Event{user='令狐冲', url='./home', timestamp=1970-01-01 08:00:02.0}
shuffle--:1> Event{user='依琳', url='./home', timestamp=1970-01-01 08:00:06.9}
shuffle--:3> Event{user='依琳', url='./cart', timestamp=1970-01-01 08:00:06.5}
第二次执行结果
shuffle--:4> Event{user='令狐冲', url='./home', timestamp=1970-01-01 08:00:02.0}
shuffle--:1> Event{user='依琳', url='./pro?id191', timestamp=1970-01-01 08:00:03.2}
shuffle--:1> Event{user='依琳', url='./home', timestamp=1970-01-01 08:00:06.3}
shuffle--:1> Event{user='任盈盈', url='./cart', timestamp=1970-01-01 08:00:03.5}
shuffle--:1> Event{user='依琳', url='./home', timestamp=1970-01-01 08:00:06.9}
shuffle--:2> Event{user='令狐冲', url='./cart', timestamp=1970-01-01 08:00:01.0}
shuffle--:2> Event{user='任盈盈', url='./pro?id101', timestamp=1970-01-01 08:00:03.0}
shuffle--:2> Event{user='依琳', url='./cart', timestamp=1970-01-01 08:00:06.5}
可见无论执行几次,随机分区的结果都不会保持一致,可见 .shuffle() 分区的特点就是随机分区。
方式二 轮询分区(Round-Robin)
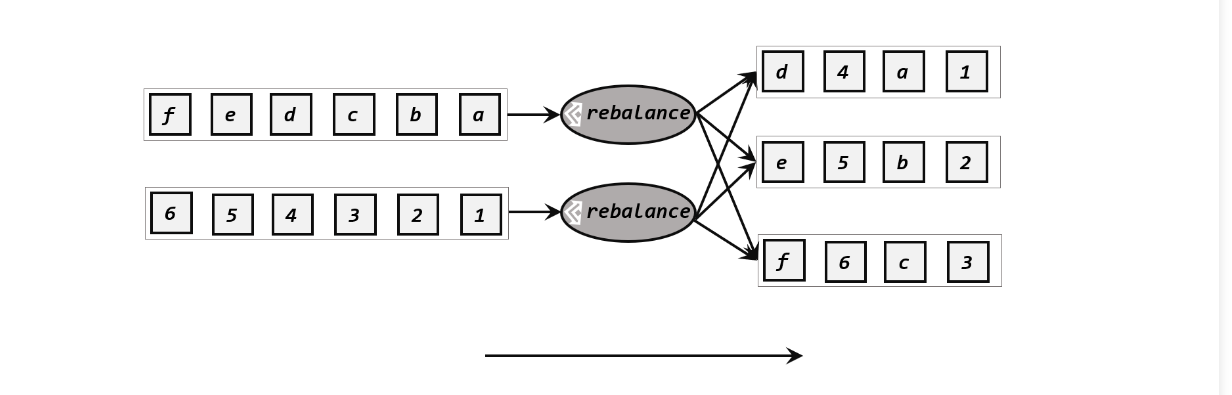
elementStream.rebalance().print().setParallelism(4);
执行结果
1> Event{user='任盈盈', url='./pro?id101', timestamp=1970-01-01 08:00:03.0}
1> Event{user='令狐冲', url='./home', timestamp=1970-01-01 08:00:02.0}
3> Event{user='令狐冲', url='./cart', timestamp=1970-01-01 08:00:01.0}
3> Event{user='任盈盈', url='./cart', timestamp=1970-01-01 08:00:03.5}
4> Event{user='依琳', url='./pro?id191', timestamp=1970-01-01 08:00:03.2}
4> Event{user='依琳', url='./home', timestamp=1970-01-01 08:00:06.9}
2> Event{user='依琳', url='./home', timestamp=1970-01-01 08:00:06.3}
2> Event{user='依琳', url='./cart', timestamp=1970-01-01 08:00:06.5}
方式三 重缩放分区(rescale)
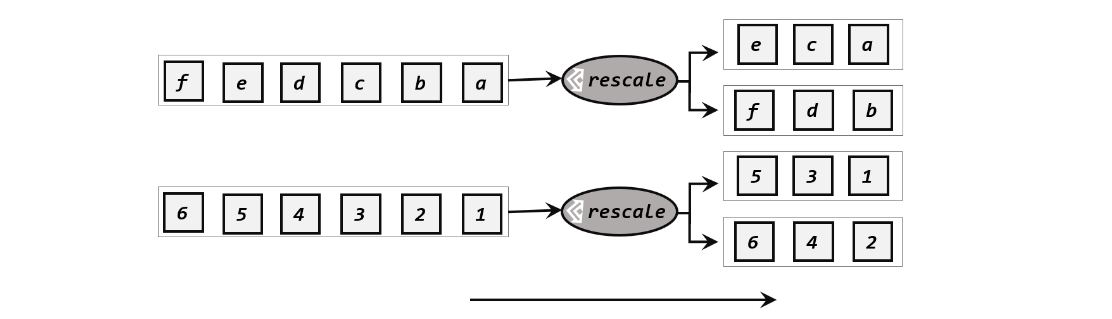
env.addSource(new RichParallelSourceFunction<Integer>() { @Override public void run(SourceContext<Integer> ctx) throws Exception { for (int i = 1; i <= 8; i++) { //将 奇偶数分配到不同的分区 if (i % 2 == getRuntimeContext().getIndexOfThisSubtask()) { ctx.collect(i); } } } @Override public void cancel() { } }).setParallelism(2).rescale().print().setParallelism(4);
执行结果
2> 4 2> 8 1> 2 1> 6 3> 1 3> 5 4> 3 4> 7
分区方式四 广播(broadcast)
这种方式其实不应该叫做“重分区”,因为经过广播之后,数据会在不同的分区都保留一份,可能进行重复处理。可以通过调用DataStream的broadcast()方法,将输入数据复制并发送到下游算子的所有并行任务中去。
elementStream.broadcast().print().setParallelism(4);
执行结果


1> Event{user='令狐冲', url='./cart', timestamp=1970-01-01 08:00:01.0}
3> Event{user='令狐冲', url='./cart', timestamp=1970-01-01 08:00:01.0}
3> Event{user='依琳', url='./pro?id191', timestamp=1970-01-01 08:00:03.2}
3> Event{user='任盈盈', url='./pro?id101', timestamp=1970-01-01 08:00:03.0}
2> Event{user='令狐冲', url='./cart', timestamp=1970-01-01 08:00:01.0}
4> Event{user='令狐冲', url='./cart', timestamp=1970-01-01 08:00:01.0}
2> Event{user='依琳', url='./pro?id191', timestamp=1970-01-01 08:00:03.2}
4> Event{user='依琳', url='./pro?id191', timestamp=1970-01-01 08:00:03.2}
4> Event{user='任盈盈', url='./pro?id101', timestamp=1970-01-01 08:00:03.0}
4> Event{user='依琳', url='./home', timestamp=1970-01-01 08:00:06.3}
4> Event{user='任盈盈', url='./cart', timestamp=1970-01-01 08:00:03.5}
4> Event{user='依琳', url='./home', timestamp=1970-01-01 08:00:06.9}
4> Event{user='令狐冲', url='./home', timestamp=1970-01-01 08:00:02.0}
4> Event{user='依琳', url='./cart', timestamp=1970-01-01 08:00:06.5}
1> Event{user='依琳', url='./pro?id191', timestamp=1970-01-01 08:00:03.2}
1> Event{user='任盈盈', url='./pro?id101', timestamp=1970-01-01 08:00:03.0}
1> Event{user='依琳', url='./home', timestamp=1970-01-01 08:00:06.3}
3> Event{user='依琳', url='./home', timestamp=1970-01-01 08:00:06.3}
3> Event{user='任盈盈', url='./cart', timestamp=1970-01-01 08:00:03.5}
3> Event{user='依琳', url='./home', timestamp=1970-01-01 08:00:06.9}
3> Event{user='令狐冲', url='./home', timestamp=1970-01-01 08:00:02.0}
3> Event{user='依琳', url='./cart', timestamp=1970-01-01 08:00:06.5}
1> Event{user='任盈盈', url='./cart', timestamp=1970-01-01 08:00:03.5}
1> Event{user='依琳', url='./home', timestamp=1970-01-01 08:00:06.9}
1> Event{user='令狐冲', url='./home', timestamp=1970-01-01 08:00:02.0}
2> Event{user='任盈盈', url='./pro?id101', timestamp=1970-01-01 08:00:03.0}
2> Event{user='依琳', url='./home', timestamp=1970-01-01 08:00:06.3}
2> Event{user='任盈盈', url='./cart', timestamp=1970-01-01 08:00:03.5}
2> Event{user='依琳', url='./home', timestamp=1970-01-01 08:00:06.9}
2> Event{user='令狐冲', url='./home', timestamp=1970-01-01 08:00:02.0}
2> Event{user='依琳', url='./cart', timestamp=1970-01-01 08:00:06.5}
1> Event{user='依琳', url='./cart', timestamp=1970-01-01 08:00:06.5}
分区方式五 全局分区(global)
elementStream.global().print().setParallelism(4);
执行结果
1> Event{user='令狐冲', url='./cart', timestamp=1970-01-01 08:00:01.0}
1> Event{user='依琳', url='./pro?id191', timestamp=1970-01-01 08:00:03.2}
1> Event{user='任盈盈', url='./pro?id101', timestamp=1970-01-01 08:00:03.0}
1> Event{user='依琳', url='./home', timestamp=1970-01-01 08:00:06.3}
1> Event{user='任盈盈', url='./cart', timestamp=1970-01-01 08:00:03.5}
1> Event{user='依琳', url='./home', timestamp=1970-01-01 08:00:06.9}
1> Event{user='令狐冲', url='./home', timestamp=1970-01-01 08:00:02.0}
1> Event{user='依琳', url='./cart', timestamp=1970-01-01 08:00:06.5}
分区方式六 自定义分区
env.fromElements(1, 2, 3, 4, 5, 6, 7, 8).partitionCustom( new Partitioner<Integer>() { @Override public int partition(Integer key, int numPartitions) { return key % 2; } }, new KeySelector<Integer, Integer>() { @Override public Integer getKey(Integer value) throws Exception { return value; } } ).print().setParallelism(4);
执行结果
2> 1 2> 3 2> 5 2> 7 1> 2 1> 4 1> 6 1> 8

 浙公网安备 33010602011771号
浙公网安备 33010602011771号