RDD编程
接下来我们看下常见RDD的转换算子和行动算子。
1、基本RDD的操作
首先来讲讲那些转化操作和行动操作受任意数据类型的RDD支持。
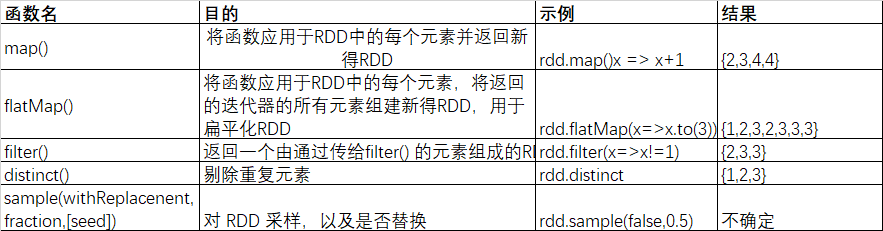
1.1、针对每个元素的转换操作
你很可能会用到的两个最常用的转化操作是map()和filter()。转化操作map()接收一个函数,把这个函数用于RDD中的每个元素,将函数的返回结果作为结果RDD中对应元素的值。而转化操作filter()则接收一个函数,并将RDD中满足该函数的元素放入新的RDD中返回。
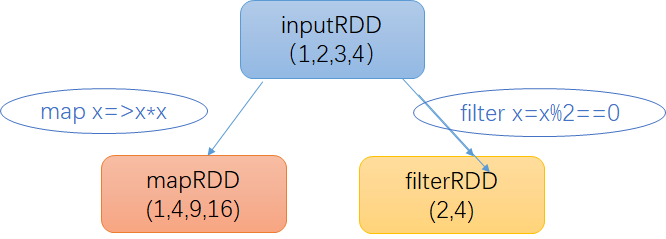
我们可以通过map() 来做各种各样的事情,可以把我们的URL集合中的对应的主机名过滤出来,也可以简单的对数字求平方根。map() 的返回值类型不一定要和输入类型保持一致。这样如果有一个字符串RDD,并且需要我们解析出每一行的一个Double值并返回,这样的话 我们的输入类型是 RDD[String],输出类型是 RDD[Double]。接下来看一下map 求每个元素的平方根案例。
def mapSqrt() = { val inputRDD: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4)) val outPutRDD: RDD[Int] = inputRDD.map(x => x * x) println(outPutRDD.collect().mkString(",")) }
有时候我们需要对一个输入元素生成多个输出元素,这个时候我们需要使用 flatMap()。和 map() 类似,我们提供给flatMap() 的函数被分别应用到了每个输入RDD的元素上,不过返回的不一定是一个元素了,而是一个值得序列迭代器。输出的RDD倒不是由迭代器组成的。我们得到的是一个含有各个迭代器可访问的所有元素的RDD。flatMap() 的一个简单用途是吧输入的字符串切分为单词。
def flatMap() = { val flatMapRdd: List[String] = List("令狐冲 依琳", "任盈盈 田伯光"). flatMap(line => line.split(" ")).map(name => name + " 过年好...") flatMapRdd.foreach(name => println(name)) }
1.2. 伪集合操作
尽管RDD本身不是严格意义上的集合,但它也支持许多数学上的集合操作,比如合并和相交操作。图3-4展示了四种操作。注意,这些操作都要求操作的RDD是相同数据类型的。我们的RDD中最常缺失的集合属性是元素的唯一性,因为常常有重复的元素。如果只要唯一的元素,我们可以使用RDD.distinct()转化操作来生成一个只包含不同元素的新RDD。不过需要注意,distinct()操作的开销很大,因为它需要将所有数据通过网络进行混洗(shuffle),以确保每个元素都只有一份。
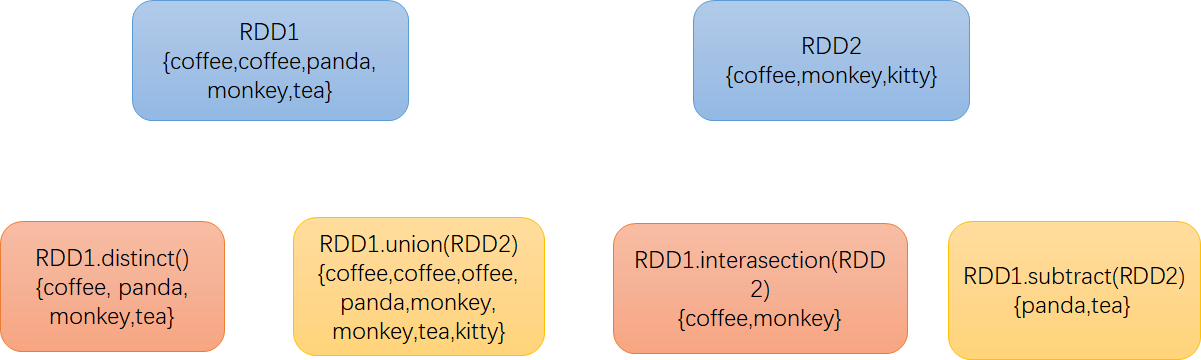
最简单的集合操作是union(other),它会返回一个包含两个RDD中所有元素的RDD。这在很多用例下都很有用,比如处理来自多个数据源的日志文件。与数学中的union()操作不同的是,如果输入的RDD中有重复数据,Spark的union()操作也会包含这些重复数据(如有必要,我们可以通过distinct()实现相同的效果)。Spark还提供了intersection(other)方法,只返回两个RDD中都有的元素。intersection()在运行时也会去掉所有重复的元素(单个RDD内的重复元素也会一起移除)。尽管intersection()与union()的概念相似,intersection()的性能却要差很多,因为它需要通过网络混洗数据来发现共有的元素。有时我们需要移除一些数据。subtract(other)函数接收另一个RDD作为参数,返回一个由只存在于第一个RDD中而不存在于第二个RDD中的所有元素组成的RDD。和intersection()一样,它也需要数据混洗。
对一个数据为{1, 2, 3, 3}的RDD进行基本的RDD转化操作
对数据分别为{1, 2, 3}和{3, 4, 5}的RDD进行针对两个RDD的转化操作

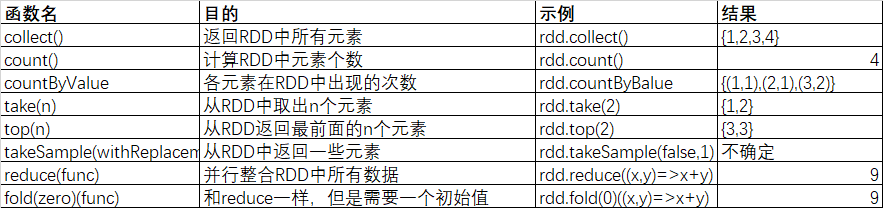
1.3、RDD 行动算子
最基本的行动算子就是 reduce() 了,它接收一个函数作为参数,该函数要操作两个RDD的元素类型的数据并返回一个同样类型的元素。一个简单的例子就是累加求和了。将所有的元素进行累加。
val sum = rdd.reduce((x, y) => x + y)
对一个数据为{1, 2, 3, 3}的RDD进行基本的RDD行动操作
下面是这一段时间练习的转换算子
object Transrdd { private val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD") private val sc: SparkContext = new SparkContext(conf) def main(args: Array[String]): Unit = { flatMap //map flatMap mapPartitions mapPartitionsWithInde //reduce reduceBykey union groupBYKey join sample //filter distinct intersection coalesce replication repartitionAndSortWithinPartitions //coGroup //sortByKey } /** * 对于 map 算子,数据源rdd每个元素都会进行处理,由于依次进行传参,所以map是有序的,map 转换 * 后的rdd 与源 rdd 顺序一样 */ def map() = { val listRDD: RDD[String] = sc.makeRDD(List("令狐冲", "依琳", "任盈盈", "田伯光")) val nameRDD: RDD[String] = listRDD.map(name => name + " 大侠你好...") nameRDD.foreach(name => println(name)) } /** * flatMap 的特性决定了这个算子在对需要元素的时候很好用,比如对 源RDD 查漏补缺 * map 和 flatMap 都是依次进行参数传递,但在有时候需要 RDD 中的两个元素进行相应操作, * 例如:计算存款所得时,下一个月所得的利息是在原来本金和上一个月所得利息的,这两个算子就无法达到目的,这里 * 需要 mapParititions 算子,将整个RDD传入,然后返回一个迭代器 */ def flatMap() = { val flatMapRdd: List[String] = List("令狐冲 依琳", "任盈盈 田伯光"). flatMap(line => line.split(" ")).map(name => name + " 过年好...") flatMapRdd.foreach(name => println(name)) } /** * 传入迭代器返回迭代器 */ def mapPartitions() = { sc.makeRDD(List(1, 2, 3, 4, 5, 6), 2) .mapPartitions( iter => { val buffer: ListBuffer[String] = ListBuffer() while (iter.hasNext) { buffer.append("hello " + iter.next()) } buffer.toIterator //mapPartitions 需要返回迭代器 } ).foreach(name => println(name)) } /** * 每次打印获取 分区所在索引 */ def mapPartitionsWithIndex = { sc.makeRDD(List(1, 2, 3, 4, 5, 6), 2) .mapPartitionsWithIndex((index, iter) => { val buffer: ListBuffer[String] = new ListBuffer while (iter.hasNext) { buffer.append(index + " " + iter.next()) } buffer.toIterator }, true) }.foreach(name => println(name)) /** * reduce 其实是将RDD中的所有元素进行合并,当运行方法时,会传入两个参数,在方法中将两个参数合并后返回 * 而这个返回值会和一个新的RDD的元素再次传入方法中,继续合并,直到合到最后一个元素 */ def reduce() = { val listRDD: RDD[Int] = sc.makeRDD(List(0, 1, 2, 3, 4, 5)) println(listRDD.reduce((x, y) => x + y)) //所有元素相加 返回一个综合 结果是 15 } /** * reduceBykey 仅将RDD中所有的 K 相同的 V 进行求和,就是 wordCount */ def reduceBykey() = { val list: List[(String, Int)] = List(("令狐冲", 89), ("依琳", 80), ("任盈盈", 82), ("依琳", 9), ("任盈盈", 5), ("东方伯", 99)) val res: RDD[(String, Int)] = sc.makeRDD(list).reduceByKey(_ + _) res.foreach(tuple => println(tuple._1 + " 大侠" + "->" + tuple._2)) } /** * 对两个 rdd 进行简单合并。不剔除重复数据 */ def union = { val l1: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4)) val l2: RDD[Int] = sc.makeRDD(List(3, 4, 5, 6)) l1.union(l2).foreach(println(_)) } /** * union 只是将两个 rdd 进行合并,join 则不一样,join 类似于 Hadoop 中的 combiner 操作,只是少了排序这一段功能 * join 可以理解为 grupByKey 和 union 的集合。groupBy 是对 rdd 元素进行分组,groupByKey 按 key 进行分组 */ def groupBYKey() = { val tuples: List[(String, String)] = List(("日月神教", "东方伯"), ("衡山派", "刘正风"), ("嵩山派", "左冷禅"), ("华山派", "令狐冲"), ("衡山派", "莫大"), ("日月神教", "任我行"), ("华山派", "风清扬")) val rdd: RDD[(String, String)] = sc.makeRDD(tuples) val groupByKeyRDD: RDD[(String, Iterable[String])] = rdd.groupByKey() groupByKeyRDD.foreach(t => { val mp: String = t._1 val iterator: Iterator[String] = t._2.iterator var peopel = "" while (iterator.hasNext) { peopel = peopel + iterator.next() + " " } println("门派:" + mp + " 高手: " + peopel) }) } /** * join是对两个 RDD 进行合并,并将有相同key的元素分为一组, * 可以理解为groupByKey和Union的结合 */ def join = { val l1: RDD[(Int, String)] = sc.makeRDD(List((1, "左冷禅"), (2, "莫大"), (3, "依琳"), (4, "任我行"))) val l2: RDD[(Int, Int)] = sc.makeRDD(List((1, 92), (2, 89), (3, 99), (4, 98))) val joinRDD: RDD[(Int, (String, Int))] = l1.join(l2) //结果无序 /* (4,(任我行,98)) (1,(左冷禅,92)) (2,(莫大,89)) (3,(依琳,99))*/ joinRDD.foreach(t => println("ID:" + t._1 + " Name:" + t._2._1 + " Score:" + t._2._2)) } /** * 抽样 第一个参数 抽样数据是否放回,第二个 抽样概率 */ def sample() = { val rdd: RDD[Int] = sc.makeRDD(1 to 100) rdd.sample(false, 0.1, 0).foreach(num => println(num + " ")) } /** * 过滤 */ def filter = { val list: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)) list.filter(n => n % 2 == 1).foreach(println(_)) } /** * 剔除重复数据 */ def distinct() = { val list: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 6, 3, 5, 6, 4, 0)) list.distinct().foreach(println) } /** * 找出相同的元素生成一个 rdd */ def intersection() = { val list1: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5)) val list2: RDD[Int] = sc.makeRDD(List(0, 2, 3, 7, 0)) list1.intersection(list2).foreach(println) } /** * 调整 rdd 分区数 由多变少 缩减分区 */ def coalesce() = { val list: RDD[Int] = sc.makeRDD(List(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11), 6) //将原有6个分区的数据进行调整 val coalesceRDD: RDD[Int] = list.coalesce(2) //演示 原有分区 list.mapPartitionsWithIndex(mapPartitionsWithIndexFun).foreach(println(_)) println("---------------------") //演示 现有分区 coalesceRDD.mapPartitionsWithIndex(mapPartitionsWithIndexFun).foreach(println(_)) } /** * 增加分区 */ def replication() = { val list: RDD[Int] = sc.makeRDD(List(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11), 2) //增加4个分区 val replicationRDD: RDD[Int] = list.repartition(6) //演示 原有分区 list.mapPartitionsWithIndex(mapPartitionsWithIndexFun).foreach(println(_)) println("---------------------") //演示 现有分区 replicationRDD.mapPartitionsWithIndex(mapPartitionsWithIndexFun).foreach(println(_)) } /** * repartitionAndSortWithinPartitions 函数是 repartition 函数的变种,与 repartition 函数不同的是, * repartitionAndSortWithinPartitions 在给定的 partitioner 内部进行排序,性能比 repartition 要高 */ def repartitionAndSortWithinPartitions = { val list: RDD[Int] = sc.makeRDD(List(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11), 2) list.mapPartitionsWithIndex(mapPartitionsWithIndexFun).foreach(println(_)) println("-------------") list.map(num => (num, num)).repartitionAndSortWithinPartitions(new HashPartitioner(6)) .mapPartitionsWithIndex((index, iter) => { val buf: ListBuffer[String] = new ListBuffer while (iter.hasNext) { buf.append(index + " " + iter.next()) } buf.toIterator }, true).foreach(println(_)) } /** * mapPartitionsWithIndex 通用遍历函数 * * @param index * @param iter * @return */ def mapPartitionsWithIndexFun(index: Int, iter: Iterator[AnyVal]): Iterator[Any] = { iter.toList.map(x => index + " --> " + x).iterator } /** * 对两个RDD 的 元素 ,每个RDD中相同的 key 的元素分别聚合成一个集合。与 reduceByKey 不同的是针对没两个RDD中 * 相同的 key 元素进行合并 */ def coGroup() = { val list1: RDD[(Int, String)] = sc.makeRDD(List((1, "www"), (2, "bba"))) val list2: RDD[(Int, String)] = sc.makeRDD(List((1, "cnblog"), (2, "cnblog"), (3, "very"))) val list3: RDD[(Int, String)] = sc.makeRDD(List((1, "www"), (2, "com"), (3, "good"))) list1.cogroup(list2, list3).foreach(tuple => println(tuple._1 + " " + tuple._2._1 + " " + tuple._2._2 + " " + tuple._2._3) ) } /** * 用于 KV 形式的 RDD ,并对 key 进行排序 */ def sortByKey() = { val list: RDD[(Int, String)] = sc.makeRDD(List((99, "令狐冲"), (66, "依琳"), (80, "任盈盈"), (73, "东方伯"))) list.sortByKey(false).foreach(t => println(t._2 + " --> " + t._1)) //测试未达到预期排序效果,不知为何 } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号