RDD 编程一些细节
Spark 中的 RDD 其实是一个分布式对象集合,每个 RDD 都被分为多个分区,这些分区运行在集群的不同的节点上。RDD 支持转换操作和行动操作。转化操作会由一个 RDD 生成一个新的 RDD ,例如
scala> val lines = sc.textFile("README.md")
这里通过读取 README.md 创建了一个 RDD
scala> val pythonLines = lines.filter(line=>line.contains("Python"))
pythonLines: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[2] at filter at :26
这里就是对 lines 进行了转化,意思是过滤 包含有 Python 关键字的数据创建新的 RDD。行动操作其实对 RDD进行计算,并把结果返回到驱动程序中,或把结果存储到指定路径。first() 就是一个行动操作,意思是返回当前 RDD 的第一个元素,count() 也是一个行动操作,返回了当前RDD的元素个数,
scala> pythonLines.first() res5: String = high-level APIs in Scala, Java, Python, and R, and an optimized engine that scala> pythonLines.count() res6: Long = 3
转化操作和行动操作的区别在于 Spark 计算 RDD 的方式有所不同。虽然可以随时定义新的 RDD,但是 Spark 有惰性计算的特性。也就是说只有在行动操作的时候才会真正计算。这种设计思想看起来会有些奇怪,不过大数据领域是很有道理的。比如以上案例,我们读取 README.md 文档创建 RDD ,又通过 filter 算子创建新的只包含 Python 关键字的 RDD,在 定义 line 时就直接把整个文案多有的数据都读取进行保存,那么是会消耗很多存储的,我们只是想保留关键字部分数据,相反,一旦 Spark 了解完整的转化操作后,只计算我们要的那部分数据,比如 first() 只读取 pythonLines 第一行匹配数据,而不是整个文件。默认情况下,Spark 对 同一个 RDD 进行两次行动操作时其实对 这个 RDD 进行了重复计算。比如
pythonLines.first() pythonLines.count()
这个是对 同一个 RDD进行了 重复计算,两者都是先计算 pythonLines 在计算 第一行和总行数。
1 RDD 转换操作简介
RDD 的转换操作是返回新的RDD,转换出来的新的RDD是惰性求值的,只有在第一次行动操作的时候才会计算RDD。许多转换操作都是准对各个元素进行操作。这些转换操作每次只会操作RDD的一个元素,不过并不是所有的转换操作都是这样的。假定在这里有一个日志文件log.txt,记录了许多服务运行信息,我们需要过滤错误消息。需要使用到 filter算子进行计算。
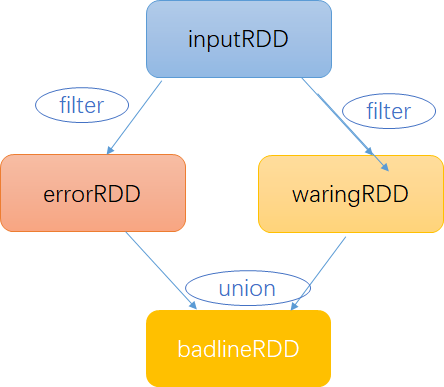
val inputRDD: RDD[String] = sc.textFile("log.txt")
val errorRDD: RDD[String] = inputRDD.filter(line => line.contains("error"))
说明,filter 不会改变 inputRDD 的数据,而是在此基础上封装了新的RDD的计算逻辑,依然可以调用 inputRDD 进行转换操作。
val inputRDD: RDD[String] = sc.textFile("log.txt")
val errorRDD: RDD[String] = inputRDD.filter(line => line.contains("error"))
val warningRDD: RDD[String] = inputRDD.filter(line => line.contains("warning"))
val badlineRDD: RDD[String] = errorRDD.union(warningRDD)
比如 我们分别过滤了含有 error 和 waring 的两个 RDD,两个操作均不会改变原有数据 inputRDD的数据,这里的 union 是将两个 RDD进行了合并。RDD 是通过不同的转换算子将一个RDD转换为新的RDD的,Spark 会使用谱系图来记录RDD之间的依赖关系,Spark 需要使用这些信息来计算每个RDD,也可以依靠谱系图在持久化的RDD丢失部分数据时恢复丢失的数据。
2、RDD 行动操作简介
RDD 转换的本质是创建新的 RDD,不过有时我们希望对数据集进行实际的计算。行动操作会把最终的结果返回到驱动程序或者写入外部存储系统中,由于行动操作会生成实际的输出,它会强制执行那些必须用到的RDD的计算逻辑。比如上面通过 union 连接的一个RDD,此时我们可以通过count() 计算结果数量,或者通过 take(n) 来取出一些数据来看。
println(" input had " + badlineRDD.count() + " concering lines")
println(" here are 10 lines example:")
badlineRDD.take(10).foreach(println)
这里的 take(10) 是将RDD的数据获取10行,然后通过 collect() 进行打印。如果RDD的数据量很小这样是可以的,但是如果数据量有很多就不能使用 collect() 函数了,此时通过 saveAsTextFile/saveAsSequencetFile 对数据进行保存然后再通过文件系统对结果数据进行操作。
3、RDD 惰性求值
RDD 的转换操作是惰性求值的,也就是说在被调用行动算子之前Spark不会出发真正计算。惰性求值意味着在我们执行转换操作时,操作不会真正开始计算,而是Spark 在内部记录了RDD要要错和执行的相关信息。所以,大家不应该把 RDD看作特定的数据集,而是最好把每个RDD看作是通过转换操作转换过来的,记录如何计算数据的指令列表。把数据读取到RDD的操作也是 惰性的。因此我们调用sc.textFile() 时,数据并未有读取进来,而是必要时才会读取,和转换操作一样的是如果初始RDD不进行缓存,那么创建初始RDD也可能会调用多次。
4、RDD 传参
Spark 的大部分转换操作和一部分行动操作需要依赖用户传递的函数来计算。在Scala 中,我们可以把定义的内联函数、方法的引用或静态方法传递给Spark,就像scala 的其他函数的方式一样。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号