Spark学习 RDD 概述
- RDD 弹性分布式数据集
- 累加器:分布式共享只写变量
- 广播变量:分布式共享只读变量
1、RDD 概述
1.1、RDD 引入之IO流
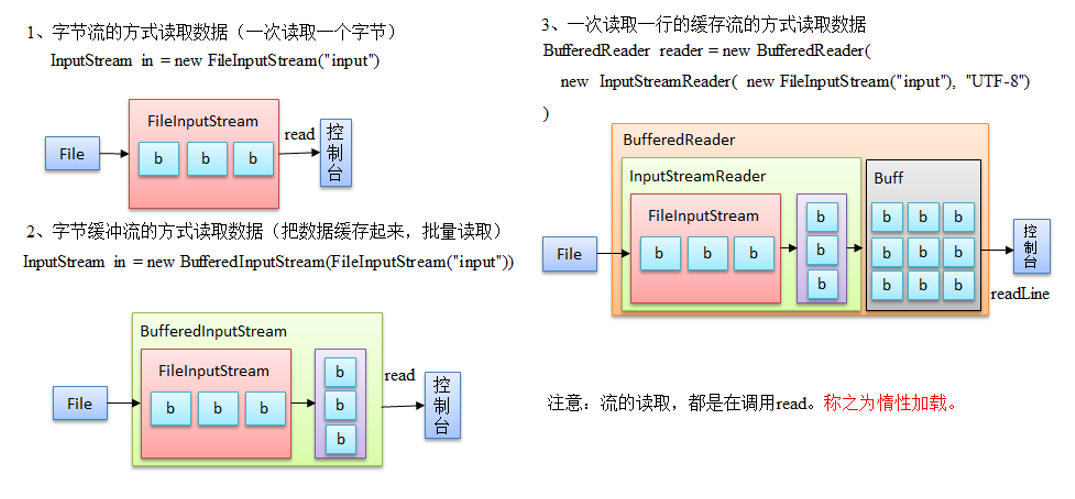

1.2、什么是RDD
1.3、RDD 核心属性
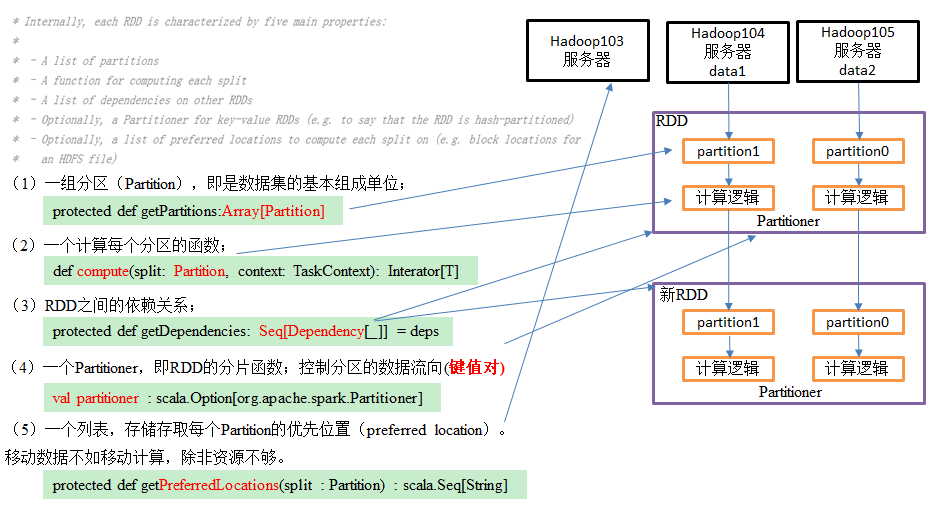
* Internally, each RDD is characterized by five main properties: * * - A list of partitions * - A function for computing each split * - A list of dependencies on other RDDs * - Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned) * - Optionally, a list of preferred locations to compute each split on (e.g. block locations for * an HDFS file)
1、分区列表 RDD 数据结构存放在分区列表中,用于实现并行计算,是分布式计算的基础属性;
/** * Implemented by subclasses to return the set of partitions in this RDD. This method will only * be called once, so it is safe to implement a time-consuming computation in it. * * The partitions in this array must satisfy the following property: * `rdd.partitions.zipWithIndex.forall { case (partition, index) => partition.index == index }` */ protected def getPartitions: Array[Partition]
2、分区计算函数,spark 在计算时,使用分区计算函数对每一个分区进行计算
/** * :: DeveloperApi :: * Implemented by subclasses to compute a given partition. */ @DeveloperApi def compute(split: Partition, context: TaskContext): Iterator[T]
/** * Implemented by subclasses to return how this RDD depends on parent RDDs. This method will only * be called once, so it is safe to implement a time-consuming computation in it. */ protected def getDependencies: Seq[Dependency[_]] = deps
/** * Optionally overridden by subclasses to specify placement preferences. */ protected def getPreferredLocations(split: Partition): Seq[String] = Nil /** Optionally overridden by subclasses to specify how they are partitioned. */ @transient val partitioner: Option[Partitioner] = None
/** * Optionally overridden by subclasses to specify placement preferences. */ protected def getPreferredLocations(split: Partition): Seq[String] = Nil
2、RDD 执行原理
1、启动 Yarn
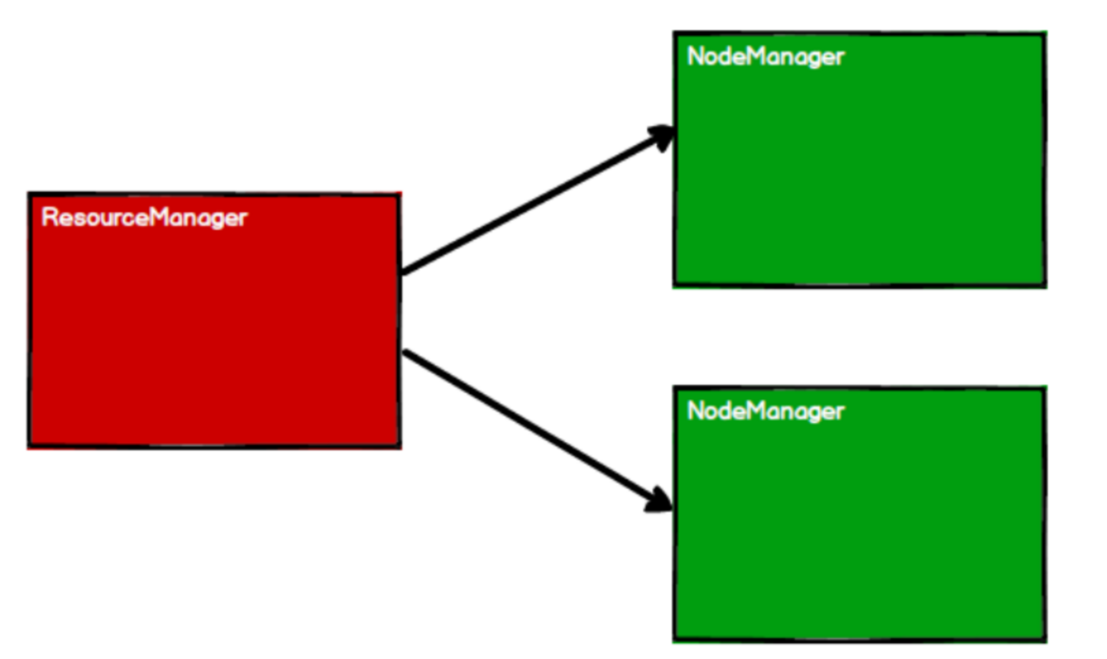
2、Spark 通过申请资源创建调度节点和计算节点
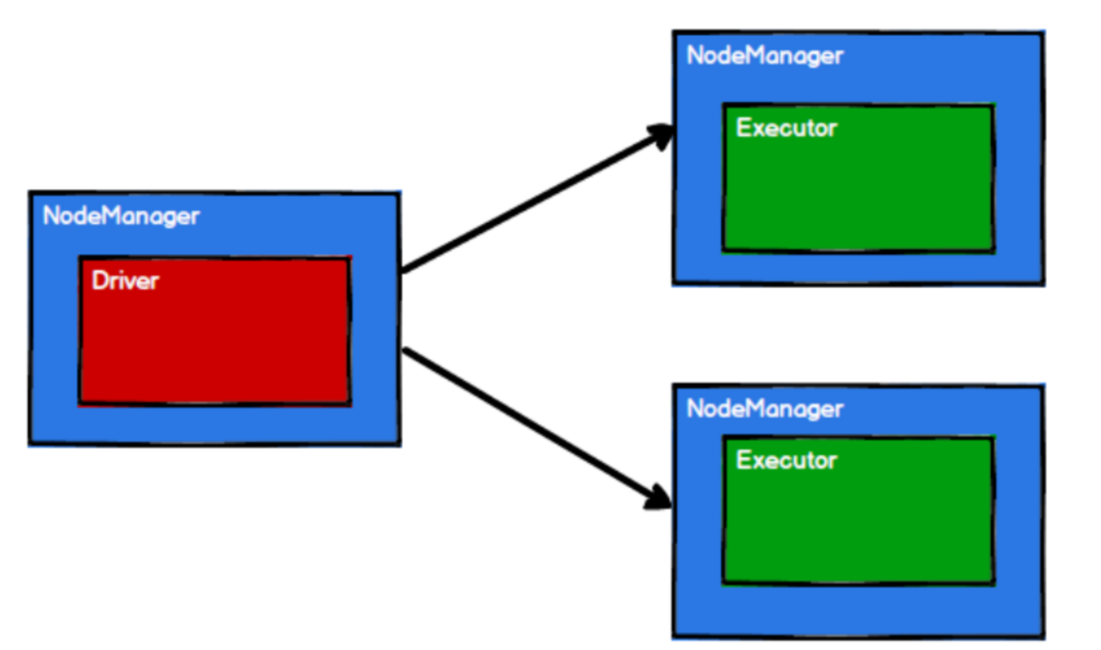
3、spark 框架根据将计算逻辑根据计算需求分区划分成不同的任务;
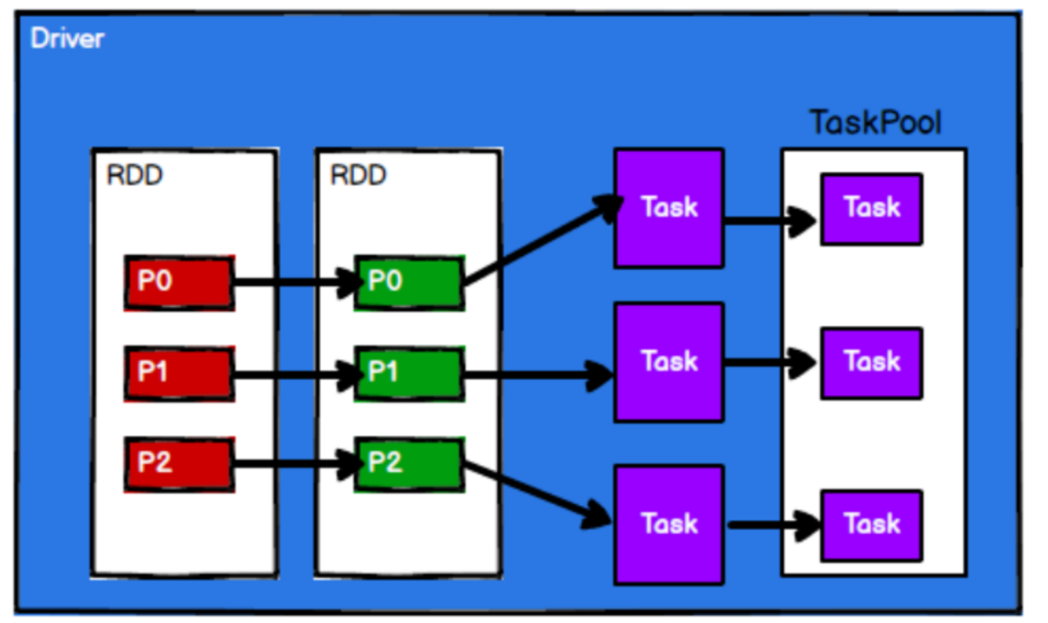
4、调度节点将任务根据计算节点状态发送到对应的计算节点进行计算
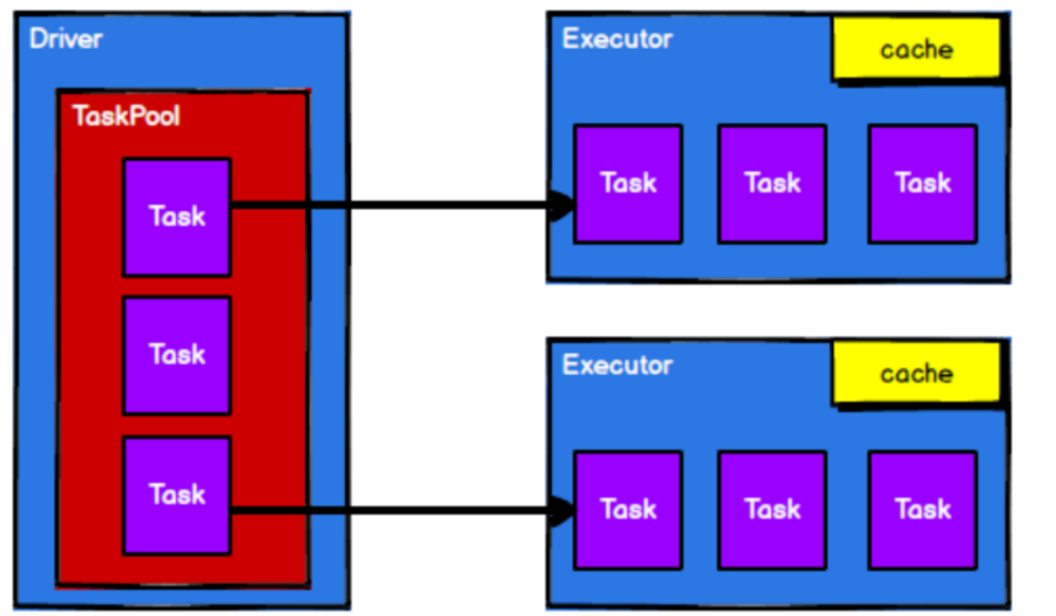
从以上流程可以看出RDD在整个流程中主要用于将逻辑进行封装,并生成Task发送给Executor节点执行计算,接下来我们就一起看看Spark框架中RDD是具体是如何进行数据处理的。
3、RDD的创建
1、读取外部文件创建RDD
启动 spark-shell
cd /opt/module/spark_local
[hui@hadoop103 spark_local]$ bin/spark-shell
读取外部文件创建RDD
scala> val line=sc.textFile("README.md");
line: org.apache.spark.rdd.RDD[String] = README.md MapPartitionsRDD[1] at textFile at <console>:24
scala> line.first();
res0: String = # Apache Spark
scala> line.count();
res1: Long = 108
这里读取了自带的 一个 README.md 文档, lines.count() 返回了 文档里的行数,lines.first() 返回了第一行
我们看下 sc 是什么
scala> sc res3: org.apache.spark.SparkContext = org.apache.spark.SparkContext@2dcbf825 scala> lines res4: org.apache.spark.rdd.RDD[String] = README.md MapPartitionsRDD[1] at textFile at <console>:24
这里的 sc 就是 spark-shell 启动时创建的上下文环境对象。lines 是我们读取文件创建的RDD对象。
IDEA 中读取外部文件创建RDD
object Spark01_RDD_file { def main(args: Array[String]): Unit = { //todo 准备环境 val spekConf = new SparkConf().setMaster("local[*]").setAppName("RDD") //[*] 表示当前系统最大可用CPU核数 val sc = new SparkContext(spekConf) //todo 创建RDD //文件中创建RDD,经文件数据作为spark处理数据的源头 // path 路径默认以当前环境的根路径为基准,可用写绝对路径,也可以写相对路径 // //val rdd: RDD[String] = sc.textFile("dates/1.txt") // path 可用是具体路径,直接读取路径下的所有文件 //val rdd = sc.textFile("dates") // path 可用是具体路径,+ 通配符 val rdd = sc.textFile("dates/1*.txt") rdd.collect().foreach(println) sc.stop() } }
2、读取集合数据创建RDD
scala> val input = sc.parallelize(List(1,2,3,4,4)) input: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24 scala> val mapRDD = input.map(x=>x*2) mapRDD: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[1] at map at <console>:26 scala> println(mapRDD.collect().mkString(",")) 2,4,6,8,8
这里我们通过一个简单的list 来创建RDD,并调用了 map 方法对集合做了一个操作。
IDEA 读取集合数据创建RDD
object Spark01_RDD_Memory { def main(args: Array[String]): Unit = { //todo 准备环境 val spekConf = new SparkConf().setMaster("local[*]").setAppName("RDD") //[*] 表示当前系统最大可用CPU核数 val sc = new SparkContext(spekConf) //todo 创建RDD //内存中创建RDD,经内存数据作为spark处理数据的源头 val seq = Seq[Int](1, 2, 3, 4) //parallelize 并行 // val rdd = sc.parallelize(seq) // makeRDD 底层调用了 parallelize 方法 val rd = sc.makeRDD(seq) /* def makeRDD[T: ClassTag]( seq: Seq[T], numSlices: Int = defaultParallelism): RDD[T] = withScope { parallelize(seq, numSlices) */ rd.foreach(println) /* def collect(): Array[T] = withScope { val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray) Array.concat(results: _*) } */ sc.stop()//todo 关闭环境 } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号