数据同步工具 DataX 使用
一、概述
DataX 是阿里巴巴开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
DataX 设计
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
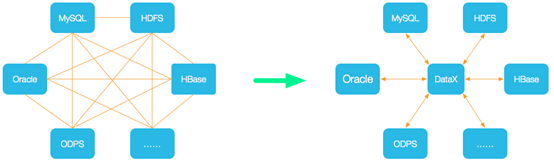
DataX 框架设计

- Reader:数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer:数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:用于连接reader和writer,作为两者的数据传输通道,并处理缓冲, 流控,并发,数据转换等核心技术问题。
DataX 运行原理
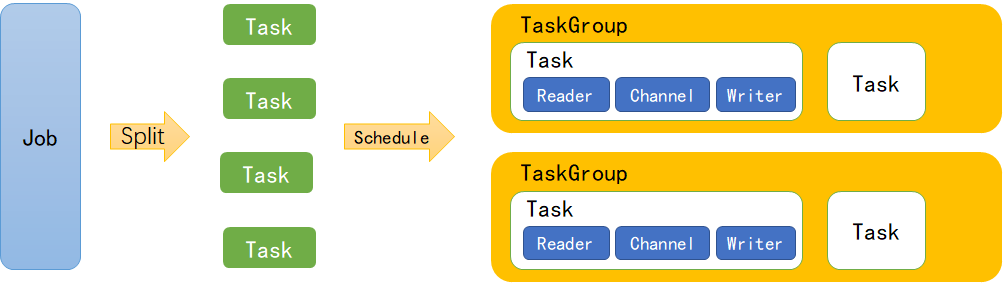
- Job:单个作业的管理节点,负责数据清理、子任务划分、TaskGroup监控管理。
- Task:由Job切分而来,是DataX作业的最小单元,每个Task负责一部分数据的同步工作。
- Schedule:将Task组成TaskGroup,单个TaskGroup的并发数量为5。
- TaskGroup:负责启动Task。
二、DataX 安装
官方文档
环境要求
- Linux
- JDK(1.8以上,推荐1.8)
- Python(推荐Python2.6.X)
安装
1、将下载好的datax.tar.gz上传到hadoop201的/opt/softwarez
[hui@hadoop201 software]$ ll datax.tar.gz
-rw-rw-r--. 1 hui hui 829372407 Jan 20 13:27 datax.tar.gz
2、解压到指定目录
tar -zxvf datax.tar.gz -C /opt/module/
3、运行自检脚本
[hui@hadoop201 software]$ cd /opt/module/datax/bin/
[hui@hadoop201 bin]$ python datax.py /opt/module/datax/job/job.json
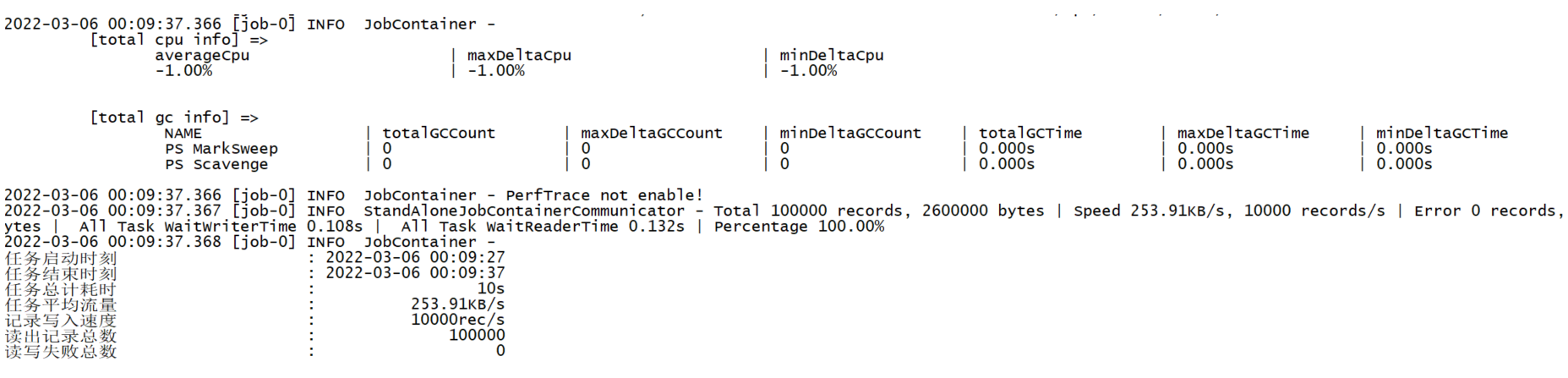
三、应用举例
mysql to hdfs
官方文档
[hui@hadoop201 bin]$ python /opt/module/datax/bin/datax.py -r mysqlreader -w hdfswriter DataX (DATAX-OPENSOURCE-3.0), From Alibaba ! Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved. Please refer to the mysqlreader document: https://github.com/alibaba/DataX/blob/master/mysqlreader/doc/mysqlreader.md Please refer to the hdfswriter document: https://github.com/alibaba/DataX/blob/master/hdfswriter/doc/hdfswriter.md Please save the following configuration as a json file and use python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json to run the job. { "job": { "content": [ { "reader": { "name": "mysqlreader", "parameter": { "column": [], "connection": [ { "jdbcUrl": [], "table": [] } ], "password": "", "username": "", "where": "" } }, "writer": { "name": "hdfswriter", "parameter": { "column": [], "compress": "", "defaultFS": "", "fieldDelimiter": "", "fileName": "", "fileType": "", "path": "", "writeMode": "" } } } ], "setting": { "speed": { "channel": "" } } } }
mysqlreader参数解析
"reader": { "name": "mysqlreader", "parameter": { "column": [], "connection": [ { "jdbcUrl": [], "table": [ ] 【“querySql:[]】 } ], "password": "", "username": "", 【"where": ""】 【"splitPk": ""】 } } 注意:【】中的参数为可选参数
name:reader名 column:需要同步的列名集合,使用JSON数组描述自带信息, *代表所有列 jdbcUrl:对数据库的JDBC连接信息,使用JSON数组描述, 支持多个连接地址 table:需要同步的表,支持多个 querySql:自定义SQL,配置它后,mysqlreader直接忽略table、 column、where password:数据库用户名对应的密码 username:数据库用户名 where:筛选条件 splitPK:数据分片字段,一般是主键,仅支持整型
hdfswriter参数解析
"writer": { "name": "hdfswriter", "parameter": { "column": [], "compress": "", "defaultFS": "", "fieldDelimiter": "", "fileName": "", "fileType": "", "path": "", "writeMode": "" } }
name:writer名 column:写入数据的字段,其中name指定字段名,type指定类型 compress:hdfs文件压缩类型,默认不填写意味着没有压缩。 defaultFS:hdfs文件系统namenode节点地址,格式:hdfs://ip:端口 fieldDelimiter:字段分隔符 fileName:写入文件名 fileType:文件的类型,目前只支持用户配置为"text"或"orc" path:存储到Hadoop hdfs文件系统的路径信息 writeMode:hdfswriter写入前数据清理处理模式: (1)append:写入前不做任何处理,DataX hdfswriter直接使用filename写入, 并保证文件名不冲突。 (2)nonConflict:如果目录下有fileName前缀的文件,直接报错。
数据准备
CREATE DATABASE test; USE test; CREATE TABLE book_info( id INT, NAME VARCHAR(20), author VARCHAR(20) ); SELECT * FROM book_info; INSERT INTO book_info VALUES(1001,'侠客行','金庸'),(1002, '孔雀翎','古龙'),(1003, '萍踪侠影','梁羽生');

myql 到 hdfs 编写配置文件
hui@hadoop201 job]$ pwd /opt/module/datax/job [hui@hadoop201 job]$ cat mysql2hdfs.json { "job": { "content": [ { "reader": { "name": "mysqlreader", "parameter": { "column": [ "id", "name", "author" ], "connection": [ { "jdbcUrl": [ "jdbcUrl": "jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNul" ], "table": [ "book_info" ] } ], "username": "username", "password": "password" } }, "writer": { "name": "hdfswriter", "parameter": { "column": [ { "name": "id", "type": "int" }, { "name": "name", "type": "string" }, { "name": "author", "type": "string" } ], "defaultFS": "hdfs://localhost:8020", "fieldDelimiter": "\t", "fileName": "book_info.txt", "fileType": "text", "path": "/", "writeMode": "append" } } } ], "setting": { "speed": { "channel": "1" } } } }
执行测试
[hui@hadoop201 datax]$ bin/datax.py job/mysql2hdfs.json 2022-03-06 01:09:12.111 [job-0] INFO JobContainer - 任务启动时刻 : 2022-03-06 01:08:57 任务结束时刻 : 2022-03-06 01:09:12 任务总计耗时 : 15s 任务平均流量 : 2B/s 记录写入速度 : 0rec/s 读出记录总数 : 3 读写失败总数 : 0
查看结果
hui@hadoop201 datax]$ hadoop fs -ls / /book_info.txt__cfcd2ce4_a6dd_40c4_b449_4392774af189
说明:HdfsWriter实际执行时会在该文件名后添加随机的后缀作为每个线程写入实际文件名。
根据业务需要可以通过sql 来指定数据列和限制条件抽取数据
[hui@hadoop201 job]$ less base_province.json { "job": { "content": [ { "reader": { "name": "mysqlreader", "parameter": { "connection": [ { "jdbcUrl": [ "jdbcUrl": "jdbc:mysql://hostname:3306/test?useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNul" ], "querySql": [ "select id,name,region_id,area_code,iso_code,iso_3166_2 from base_province where id>=0" ] } ], "password": "password", "username": "username" } }, "writer": { "name": "hdfswriter", "parameter": { "column": [ { "name": "id", "type": "bigint" }, { "name": "name", "type": "string" }, { "name": "region_id", "type": "string" }, { "name": "area_code", "type": "string" }, { "name": "iso_code", "type": "string" }, { "name": "iso_3166_2", "type": "string" } ], "compress": "gzip", "defaultFS": "hdfs://hostname:8020", "fieldDelimiter": "\t", "fileName": "base_province", "fileType": "text", "path": "/base_province", "writeMode": "append" } } } ], "setting": { "speed": { "channel": 1 } } } }
hdfs to mysql
1、将上个案例的文件名重置
[hui@hadoop201 datax]$ hadoop fs -mv /book_info.txt__cfcd2ce4_a6dd_40c4_b449_4392774af189 /book_info.txt
mysql 清空测试数据
TRUNCATE TABLE book_info
2、查看官方文档
[hui@hadoop201 datax]$ python bin/datax.py -r hdfsreader -w mysqlwriter DataX (DATAX-OPENSOURCE-3.0), From Alibaba ! Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved. Please refer to the hdfsreader document: https://github.com/alibaba/DataX/blob/master/hdfsreader/doc/hdfsreader.md Please refer to the mysqlwriter document: https://github.com/alibaba/DataX/blob/master/mysqlwriter/doc/mysqlwriter.md Please save the following configuration as a json file and use python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json to run the job. { "job": { "content": [ { "reader": { "name": "hdfsreader", "parameter": { "column": [], "defaultFS": "", "encoding": "UTF-8", "fieldDelimiter": ",", "fileType": "orc", "path": "" } }, "writer": { "name": "mysqlwriter", "parameter": { "column": [], "connection": [ { "jdbcUrl": "", "table": [] } ], "password": "", "preSql": [], "session": [], "username": "", "writeMode": "" } } } ], "setting": { "speed": { "channel": "" } } } }
3、编写hdfs 到 mysql 配置文件
[hui@hadoop201 datax]$ less job/hdfs2mysql.json { "job": { "content": [ { "reader": { "name": "hdfsreader", "parameter": { "column": ["*"], "defaultFS": "hdfs://hadoop201:8020", "encoding": "UTF-8", "fieldDelimiter": "\t", "fileType": "text", "path": "/book_info.txt" } }, "writer": { "name": "mysqlwriter", "parameter": { "column": [ "id", "name", "author" ], "connection": [ { "jdbcUrl": "jdbc:mysql://hadoop201:3306/test?useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNul", "table": ["book_info"] } ], "password": "password", "username": "username", "writeMode": "insert" } } } ], "setting": { "speed": { "channel": "1" } } } }
4、测试
[hui@hadoop201 datax]$ bin/datax.py job/hdfs2mysql.json 2022-03-06 01:31:57.812 [job-0] INFO JobContainer - 任务启动时刻 : 2022-03-06 01:31:43 任务结束时刻 : 2022-03-06 01:31:57 任务总计耗时 : 14s 任务平均流量 : 2B/s 记录写入速度 : 0rec/s 读出记录总数 : 3 读写失败总数 : 0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号