

hive 统计用户在同一地点停留时长
需求
- 对同一个用户,在同一个位置,连续的多条记录进行合并
- 合并原则:开始时间取最早的,停留时长加和
字段
userID, locationID, time, duration
样例数据
user_a location_a 2022-02-03 08:00:00 60 user_a location_a 2022-02-03 09:00:00 60 user_a location_a 2022-02-03 11:00:00 60 user_a location_a 2022-02-03 12:00:00 60
结果数据
user_a location_a 2022-02-03 08:00:00 120 user_a location_a 2022-02-03 11:00:00 120
数据准备

create table temp_dura_0303 ( user_id string, --'用户id', location_id string, -- '位置id' time_ string, -- '时间' duration int --'持续时间' ) row format delimited fields terminated by '\t' stored as orc tblproperties ("orc.compress" = "snappy"); insert into temp_dura_0303 values ("user_a", "location_a","2022-02-03 08:00:00",60), ("user_a", "location_a","2022-02-03 09:00:00",60), ("user_a", "location_a","2022-02-03 11:00:00",60), ("user_a", "location_a","2022-02-03 12:00:00",60), ("user_a", "location_b","2022-02-03 10:00:00",60), ("user_a", "location_c","2022-02-03 08:00:00",60), ("user_a", "location_c","2022-02-03 09:00:00",60), ("user_a", "location_c","2022-02-03 10:00:00",60), ("user_b", "location_a","2022-02-03 15:00:00",60), ("user_b", "location_a","2022-02-03 16:00:00",60), ("user_b", "location_a","2022-02-03 18:00:00",60); select * from temp_dura_0303;
解题思路
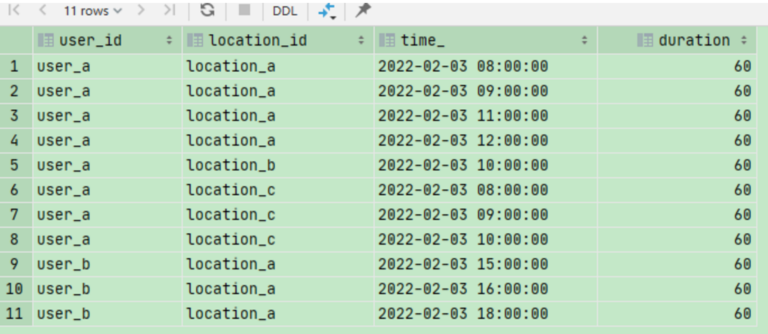
本题主要是将连续数据进行合并,就是将连续的数据分成一个组里面,所有的问题都能解决,因此本题实质上是构造分组条件,如何去分组的问题。根据需求得知本题还是连续性问题,那么问题转换为如何判断连续问题,如果连续则相邻两行的差值相同。我们先求出相邻两行的时间差值观察结果。
select user_id, location_id, time_, duration, int((unix_timestamp(time_) - unix_timestamp(lag(time_, 1, time_) over (partition by user_id,duration order by time_))) / 3600) time_cz from temp_dura_0303;
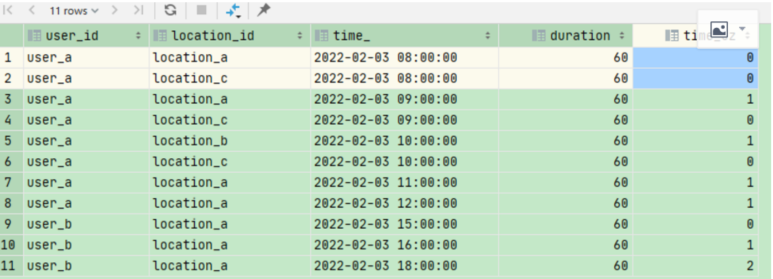
可以看出,同一个用户id及位置id里面连续的差值一定是小于等于1的,而在出现不连续的分界点时,其差值是大于1的,因此我们将出现差值大于1的地方视为一个转折点,一个事件,此时被标记为1,否则标记为0,根据重分组算法,我们进行如下分组。
select user_id, location_id, time_, duration, sum(case when time_cz > 1 then 1 else 0 end) over (partition by user_id,location_id order by time_) grep_flag from (select user_id, location_id, time_, duration, int((unix_timestamp(time_) - unix_timestamp(lag(time_, 1, time_) over (partition by user_id,location_id order by time_))) / 3600) time_cz from temp_dura_0303) t;
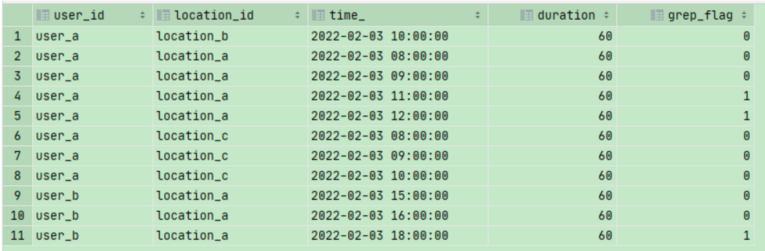
我们可以看到上述新加的列中已经依据我们的想法将数据进行区分。我们将这种大于某参照量的标记为1进行累加的算法称为重分组算法,用SQL表示为sum(if(XXX>YYY,1,0)) over(partition by XXX order by XXX).我们按照user_id,location_id及grp_id进行分组,将需要的数据分到一个组里,然后求取最小时间值及对duration时间进行求和即为最终结果,sql如下:
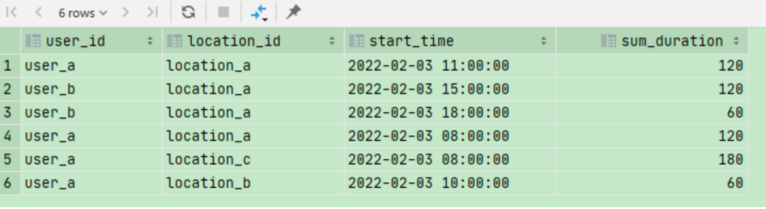
select user_id, location_id, min(time_) start_time, sum(duration) sum_duration from (select user_id, location_id, time_, duration, sum(case when time_cz > 1 then 1 else 0 end) over (partition by user_id,location_id order by time_) grep_flag from (select user_id, location_id, time_, duration, int((unix_timestamp(time_) - unix_timestamp(lag(time_, 1, time_) over (partition by user_id,location_id order by time_))) / 3600) time_cz from temp_dura_0303) t) t group by user_id, location_id, grep_flag;


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 一文读懂知识蒸馏
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下