hive 取第二高指标的两种解决思路
需求
平时工作中经常会遇到取某某指标第 n 个的需求,今天介绍下取 这样需求的两种思路
数据准备
select *from temp_shop_info where shop_id = '111'; 111 1 90 111 2 80 111 3 50 111 4 70 111 5 20 111 6 10
最后一个字段是金额,今天就取第二个金额的数据
方案一
首先通过 row_number() 方式实现
select * from (select *, row_number() over ( order by sale) rn from temp_shop_info where shop_id = '111') t where rn = 2;
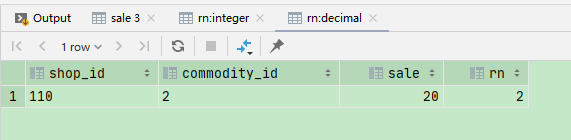
这样的好处是可以获取全列信息,通过 row_number() over ( order by sale) sale 字段排序的结果作为辅助字段,通过辅助字段提取序号为2 的即可。需要说明的是 可以 over() 内部可以增加 partition by clo 来取每笔订单的top n 的金额对需求进行扩展。
注意:当出现金额相同出现并列排名第2的时候只会一条数据,此时需要根据业务侧要求进行修改,如果只取一条数据,那么无需修改,如果需要展示并列的数据需要修改如下
select * from (select *, dense_rank() over ( order by sale) rn from temp_shop_info where shop_id = '110') t where rn = 2;

也许有人会感到奇怪,为什么这里会出来两条数据呢,接下来顺便说下 三个常用的排序函数的区别
select *, rank() over ( order by sale ) rank__, dense_rank() over ( order by sale) dense_rank__, row_number() over ( order by sale) row_number__ from temp_shop_info where shop_id = '110';
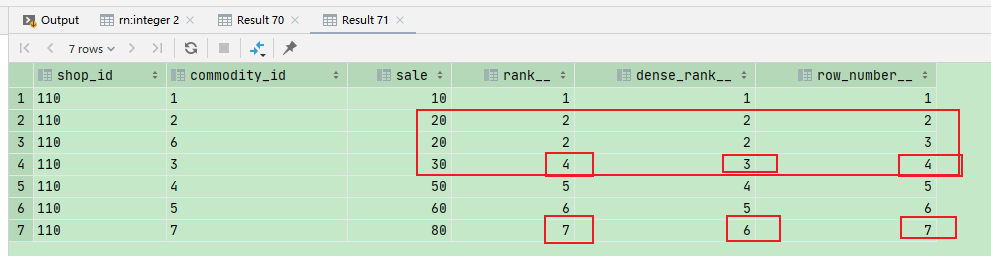
说明:
row_number: 按顺序编号,排序列值相等排序结果不留空位;
rank: 按顺序编号,排序列值相等排序结果同号,留空位;
dense_rank: 按顺序编号,排序列值相等排序结果同号,不留空位;
方案二
select distinct(sale) sale from temp_shop_info where shop_id = '111' order by sale limit 1 offset 2;
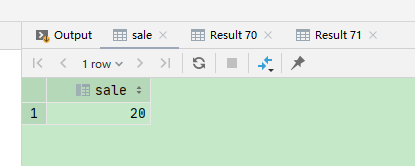
offset 是偏移量,表示从第几条数据读取数据。limit 表示取几条数据
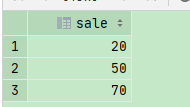
select distinct(sale) sale from temp_shop_info where shop_id = '110' order by sale limit 3 offset 2;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号