

hive 截取不固定位置字符串
需求
日志表中有如下数据
film:[non_marked]qq:[unit]tailpipe:[withabanana?]80sxxxxx call:[F_GET_ROWS()]b1:[ROSEWOOD...SIR]b2:[44400002]77.90xxxxx xxxxxabc[867]xxx[-]xxxx[5309]xxxxx xxxxxtime:[11271978]favnum:[4]id:[Joe]xxxxx
希望获取一下数据
|
non_marked
|
unit
|
withabanana?
|
|
F_GET_ROWS()
|
ROSEWOOD...SIR
|
44400002
|
|
867
|
-
|
5309
|
|
11271978
|
4
|
Joe
|
可以看出,截取每行的字符串位置未固定,但是可以借助【】 来判断截取位置以及长度。
数据准备

reate table temp_log_0213 as select 'xxxxxabc[867]xxx[-]xxxx[5309]xxxxx' msg union all select 'xxxxxtime:[11271978]favnum:[4]id:[Joe]xxxxx' msg union all select 'call:[F_GET_ROWS()]b1:[ROSEWOOD...SIR]b2:[44400002]77.90xxxxx' msg union all select 'film:[non_marked]qq:[unit]tailpipe:[withabanana?]80sxxxxx' msg;
hive 获取字符串位置的函数有一下2个
1、instr(String str, String substr)函数 返回字符串第一次出现的索引
select instr("hello hive",'e'); 2
2、locate(string substr, string str, int index)返回字符串 substr 在 str 中从 index后查找,首次出现的位置
select locate('e', 'hello hive'); 2 select locate('e', 'hello hive', 2); 2 select locate('e', 'hello hive', 3); 10
今天我们使用locate 函数处理这个需求
需求解决
select msg, locate('[', msg, 1) start_id_1, locate(']', msg, 1) end_id_1, locate('[', msg, locate('[', msg, 1) + 1) start_id_2, locate(']', msg, locate(']', msg, 1) + 1) end_id_2, locate('[', msg, locate('[', msg, locate('[', msg, 1) + 1) + 1) startd_id_3, locate(']', msg, locate(']', msg, locate(']', msg, 1) + 1) + 1) end_end_id_3 from temp_log_0213;
|
film:[non_marked]qq:[unit]tailpipe:[withabanana?]80sxxxxx
|
6
|
17
|
21
|
26
|
36
|
49
|
|
call:[F_GET_ROWS()]b1:[ROSEWOOD...SIR]b2:[44400002]77.90xxxxx
|
6
|
19
|
23
|
38
|
42
|
51
|
|
xxxxxabc[867]xxx[-]xxxx[5309]xxxxx
|
9
|
13
|
17
|
19
|
24
|
29
|
|
xxxxxtime:[11271978]favnum:[4]id:[Joe]xxxxx
|
11
|
20
|
28
|
30
|
34
|
38
|
其实位置为方括号"["索引值+1从该处开始截取,截取长度为"]"位置的索引值减去"["位置处的索引值再减1.结果如下
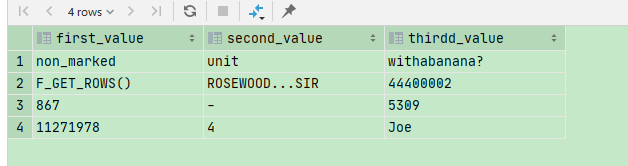
select substr(msg, locate('[', msg, 1) + 1, locate(']', msg, 1) - locate('[', msg, 1) - 1) as first_value, substr(msg, locate('[', msg, locate('[', msg, 1) + 1) + 1, locate(']', msg, locate(']', msg, 1) + 1) - locate('[', msg, locate('[', msg, 1) + 1) - 1) as second_value, substr(msg, locate('[', msg, locate('[', msg, locate('[', msg, 1) + 1) + 1) + 1, locate(']', msg, locate(']', msg, locate(']', msg, 1) + 1) + 1) - locate('[', msg, locate('[', msg, locate('[', msg, 1) + 1) + 1) - 1) as thirdd_value from temp_log_0213;


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 一文读懂知识蒸馏
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下