hive 取中位数的两种方式
需求描述
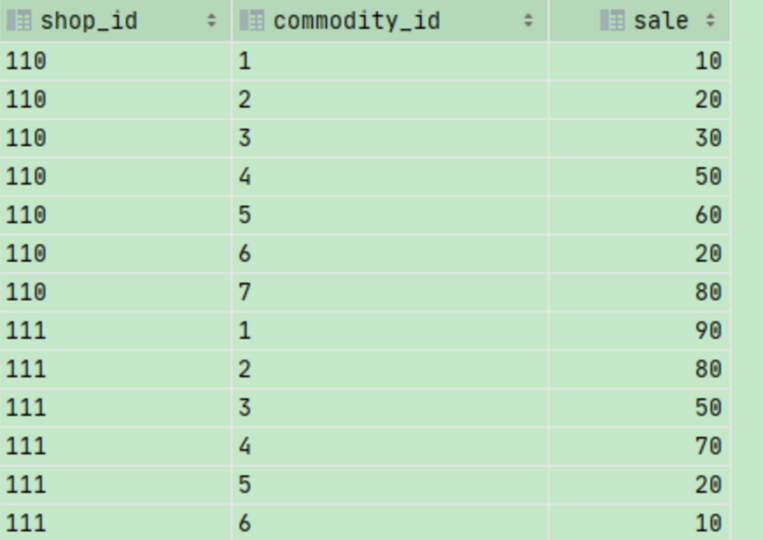
字段:店铺(shop_id),销量(sale),商品id(commodity_id),求每个店铺商品销量排名的中位数
数据准备
use default; create table temp_shop_info ( shop_id string, commodity_id string, sale int ) row format delimited fields terminated by '\t'; insert into temp_shop_info values ('110', '1', 10), ('110', '2', 20), ('110', '3', 30), ('110', '4', 50), ('110', '5', 60), ('110', '6', 20), ('110', '7', 80), ('111', '1', 90), ('111', '2', 80), ('111', '3', 50), ('111', '4', 70), ('111', '5', 20), ('111', '6', 10); select * from temp_shop_info;
样例数据
方案一:公式法
abs(rn - (cnt+1)/2) < 1
rn是给定长度为cnt的数列的序号排序,cnt为整个序列的个数
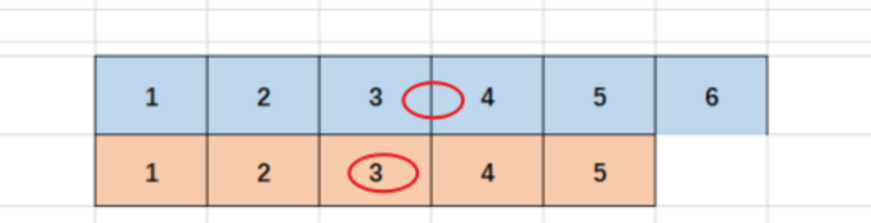
如下图所示:
第一行当cnt为偶数时:如序列长度为6,则中位数就在序号为3和4的位置上。即在(6+1)/ 2=3.5左右的即可
当cnt为奇数:如下图序列长度为,则中位数就在序号为6的位置上。即:(5+1)/ 2=3
因此得出结论:中位数的值所在的索引位置,要么在(cnt +1)/ 2左右,要么就为(cnt +1)/ 2所在的位置,这种完全由序列长度奇偶性决定,如果为奇数(cnt +1)/ 2计算结果为X.5,那么中位数就是abs(rn-(cnt +1)/ 2) = 0.5的位置,如果为偶数,则有abs(rn-(cnt +1)/ 2) =0的位置,也就是说差值的绝对值要么为0.5要么为0,由于是连续的序列,所以统一后,即为:
abs(rn - (cnt+1)/2) < 1 或abs(rn - (cnt+1)/2) < =1/2
第一步
select shop_id, sale, row_number() over (partition by shop_id order by sale) rn,-按shop_id 分组并按 sale 配许 count(*) over (partition by shop_id) cnt --按shop_id 分组 求 个数 from temp_shop_info;

第二步
select shop_id, avg(sale) as median --奇数保留,偶数取均值 from (select shop_id, sale, row_number() over (partition by shop_id order by sale) as rn, -- 生成每个商铺各个商品按销售量排序后的连续序列rn count(1) over (partition by shop_id) as cnt -- 计算序列长度cnt from temp_shop_info) t where abs(rn - (cnt + 1) / 2) <= 0.5 -- 利用公式 group by shop_id;
111 60
110 30
方案二 使用函数
hive 自带了 求中位数的函数,下面我们用更简单的方法来实现上面的需求
percentil
select shop_id, percentile(sale, 0.5) from temp_shop_info group by shop_id;
结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号