hive 解析 json 数据方法
json是常见的一种数据格式,一般通过埋点程序获取行为用户行为数据,将多个字段存放在一个json数组中,因此数据平台调用数据时,要对json数据进行解析处理。接下来介绍下Hive中是如何解析json数据的。
hive 解析 json 数据函数
1、get_json_object
- 语法:get_json_object(json_string, '$.key')
- 说明:解析json的字符串json_string,返回path指定的内容。如果输入的json字符串无效,那么返回NULL。这个函数每次只能返回一个数据项。
实例
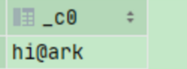
select get_json_object('{"name":"令狐冲","age":29}', '$.name') user_name;
结果

解析二个字段示例:
select get_json_object('{"name":"依琳","age":16}', '$.name') user_name, get_json_object('{"name":"依琳","age":16}', '$.age') user_age;

get_json_object解析json多个字段有很多会太麻烦,可以使用 json_tuple。
2、json_tuple
- 语法: json_tuple(json_string, k1, k2 ...)
- 说明:解析json的字符串json_string,可指定多个json数据中的key,返回对应的value。如果输入的json字符串无效,那么返回NULL。
示例
select b.user_name, b.age from (select * from temp.jc_test_coalesce_nvl where c1 = 1) i lateral view json_tuple('{"name":"依琳","age":18}', 'name', 'age') b as user_name, age;
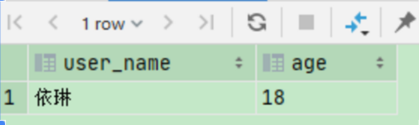
json_tuple 使用细节:与 get_json_object 不同,使用 json_tuple 获取数据不需要使用 $,如果使用 $ 反而获取不到数据。
select b.user_name, b.age from (select * from temp.jc_test_coalesce_nvl where c1 = 1) i lateral view json_tuple('{"name":"依琳","age":18}', '$.name', '$.age') b as user_name, age;
结果:使用json_tuple时需注意这一点
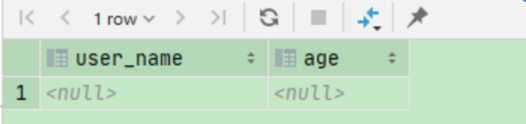
小结:json_tuple相当于get_json_object的优势就是一次可以解析多个json字段。但是这两个函数都无法处理json数组。
hive 解析 json 数组
1、使用嵌套子查询解析json数组
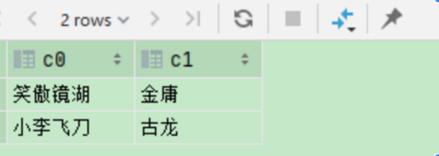
场景:一个hive表有 json_str 字段的内容如下:
|
json_str
|
|
[{"title":"笑傲镜湖","author":"金庸"},{"title":"小李飞刀","author":"古龙"}]
|
希望解析出以下数据:
|
title
|
author
|
|
笑傲镜湖
|
金庸
|
|
小李飞刀
|
古龙
|
实现思路:
explode函数
- 语法:explode(Array OR Map)
- 说明:explode()函数接收一个array或者map类型的数据作为输入,然后将array或map里面的元素按照每行的形式输出,即将hive一列中复杂的array或者map结构拆分成多行显示,也被称为列转行函数。
示例
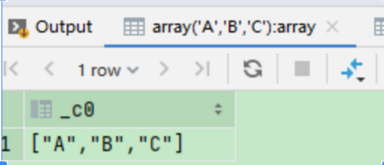
select array('A','B','C') ;
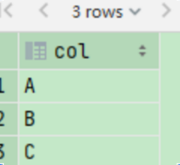
select explode(array('A','B','C'));
regexp_replace函数
- 语法: regexp_replace(string A, string B, string C)
- 说明:将字符串A中的符合java正则表达式B的部分替换为C。注意,在有些情况下要使用转义字符,类似oracle中的regexp_replace函数。
示例:将 ve_sp 替换成 @
select regexp_replace('hive_spark', 've_sp', '@');
下面我们试着解析 json 数组
第一步:先将json数组中的元素解析出来,转化为每行显示
select explode(split(regexp_replace(regexp_replace('[{"title":"笑傲镜湖","author":"金庸"},{"title":"小李飞刀","author":"古龙"}]', '\\[|\\]',''),'\\}\\,\\{','\\}\\;\\{'),'\\;')); 结果: "{""title"":""笑傲镜湖"",""author"":""金庸""}" "{""title"":""小李飞刀"",""author"":""古龙""}"
上面SQL看着很长,但是一步一步看也很 esay
select explode(split( regexp_replace( regexp_replace( '[ {"title":"笑傲镜湖","author":"金庸"}, {"title":"小李飞刀","author":"古龙"} ]', '\\[|\\]' , ''), --将json数组两边的中括号去掉 '\\}\\,\\{' , '\\}\\;\\{'),--将json数组元素之间的逗号换成分号 '\\;') --以分号作为分隔符(split函数以分号作为分隔) );
说明:为什么要将json数组元素之间的逗号换成分号?
因为元素内的分隔也是逗号,如果不将元素之间的逗号换掉的话,后面用split函数分隔时也会把元素内的数据给分隔,这不是我们想要的结果。
第二步、上步已经把一个json数组转化为多个json字符串了,接下来使用json_tuple函数来解析json里面的字段:
select json_tuple(explode(split(regexp_replace(regexp_replace('[{"title":"笑傲镜湖","author":"金庸"},{"title":"小李飞刀","author":"古龙"}]', '\\[|\\]', ''),'\\}\\,\\{', '\\}\\;\\{'), '\\;')) , 'title', 'author') ;
执行上述语句,结果报错了:
UDTF's are not supported outside the select clause, nor nested in expressions:17:16,
explode函数不能写在别的json_tuple里面,更正使用子查询方式
select json_tuple(json, 'title', 'author') from ( select explode(split(regexp_replace(regexp_replace('[{"title":"笑傲镜湖","author":"金庸"},{"title":"小李飞刀","author":"古龙"}]', '\\[|\\]', ''),'\\}\\,\\{', '\\}\\;\\{'), '\\;')) as json) o
2、使用 lateral view 解析json数组
样例数据如下
|
goods_id
|
json_str
|
|
1,2,3
|
[{"source":"7fresh","monthSales":4900,"userCount":1900,"score":"9.9"},{"source":"jd","monthSales":2090,"userCount":78981,"score":"9.8"},{"source":"jdmart","monthSales":6987,"userCount":1600,"score":"9.0"}]
|
期望结果:把 goods_id 字段和 json_str 字段中的monthSales解析出来。
首先:拆分goods_id字段及将json数组转化成多个json字符串
select explode(split(goods_id,',')) as good_id, explode(split(regexp_replace(regexp_replace(json_str , '\\[|\\]',''),'\\}\\,\\{','\\}\\;\\{'),'\\;')) as sale_info from tableName;
执行上述语句,结果报错:
FAILED: SemanticException 3:0 Only a single expression in the SELECT clause is supported with UDTF's. Error encountered near token 'sale_info'
用UDTF的时候,SELECT 只支持一个字段。而上述语句select中有两个字段,所以报错了。
那怎么办呢,要解决这个问题,还得再介绍一个hive语法:
lateral view
lateral view用于和split、explode等UDTF一起使用的,能将一行数据拆分成多行数据,在此基础上可以对拆分的数据进行聚合,lateral view首先为原始表的每行调用UDTF,UDTF会把一行拆分成一行或者多行,lateral view在把结果组合,产生一个支持别名表的虚拟表。
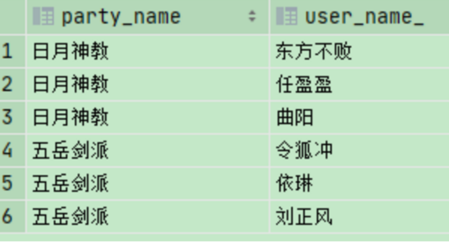
示例:一张用户大侠门派 user_table,它有两列数据,第一列是party_name,第二列是门派成员user_name,是一个数组,存储大侠的姓名:
|
party_name
|
user_name
|
|
日月神教
|
[东方不败,任盈盈,曲阳]
|
|
五岳剑派
|
[令狐冲,依琳,刘正风]
|
数据准备
create table temp.jc_t_test_json ( party_name string, user_name array<string> ) row format delimited fields terminated by ',' -- 字段之间用','分隔 collection items terminated by '_' -- 集合中的元素用'_'分隔 map keys terminated by ':' -- map中键值对之间用':'分隔 lines terminated by '\n';-- 行之间用'\n'分隔 insert into temp.jc_t_test_json select "日月神教", array("东方不败", "任盈盈", "曲阳"); insert into temp.jc_t_test_json select "五岳剑派", array ("令狐冲", "依琳","刘正风" ); select * from temp.jc_t_test_json;

select party_name, user_name_ from temp.jc_t_test_json lateral view explode(user_name) tmp_table as user_name_;
按照 user_name_ 进行分组聚合即可:
select user_name_ ,count(party_name) name_cnt from temp.jc_t_test_json lateral view explode(user_name) tmp_table as user_name_ group by user_name_;

下面看下刚才遇到的用UDTF的时候,SELECT 只支持一个字段的问题
select good_id,get_json_object(sale_json,'$.monthsales') as monthsales from tablename lateral view explode(split(goods_id,','))goods as good_id lateral view explode(split(regexp_replace(regexp_replace(json_str , '\\[|\\]',''),'\\}\\,\\{','\\}\\;\\{'),'\\;')) sales as sale_json;
|
goods_id
|
monthSales
|
|
1
|
4900
|
|
1
|
2090
|
|
1
|
6987
|
|
2
|
4900
|
|
2
|
2090
|
|
2
|
6987
|
|
3
|
4900
|
|
3
|
2090
|
|
3
|
6987
|

 浙公网安备 33010602011771号
浙公网安备 33010602011771号