Spark 分布式部署
一、Yarn 部署简介
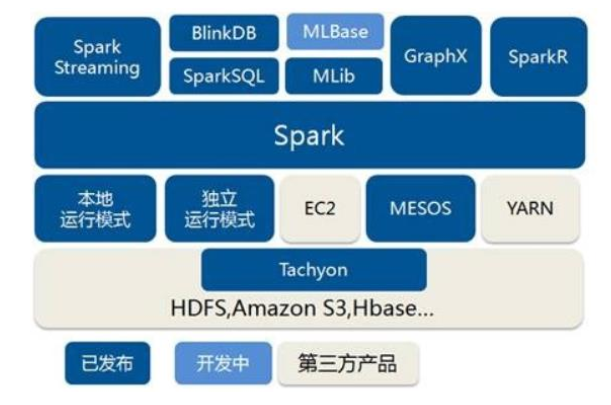
Spark自身提供计算资源,无需其他框架提供资源。But 这种方式降低了和其他第三方资源框架的耦合性,独立性非常强。请注意:Spark主要是计算框架,而不是资源调度框架,所以本身提供的资源调度并不是它的强项,所以还是和其他专业的资源调度框架集成会更靠谱一些。接下来我们看一下在强大的Yarn环境下Spark是如何工作的(其实是因为在国内工作中,Yarn使用的非常多)。
二、配置 yarn 模式
1、环境准备
hui@hadoop302 spark_yarn]$ cp -r spark_bak/ spark_yarn
2、修改配置
修改hadoop配置文件/opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml, 并分发
[hui@hadoop302 hadoop]$ cp yarn-site.xml yarn-site.xml_bak #备份原有配置 [hui@hadoop302 hadoop]$ vim yarn-site.xml <!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true --> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true --> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> [hui@hadoop302 hadoop]$ sxync yarn-site.xml
修改conf/spark-env.sh,添加JAVA_HOME和YARN_CONF_DIR配置
export JAVA_HOME=/opt/module/jdk1.8.0_212
YARN_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop
3、启动hadoop
[hui@hadoop302 conf]$ super.sh start
4、提交测试应用
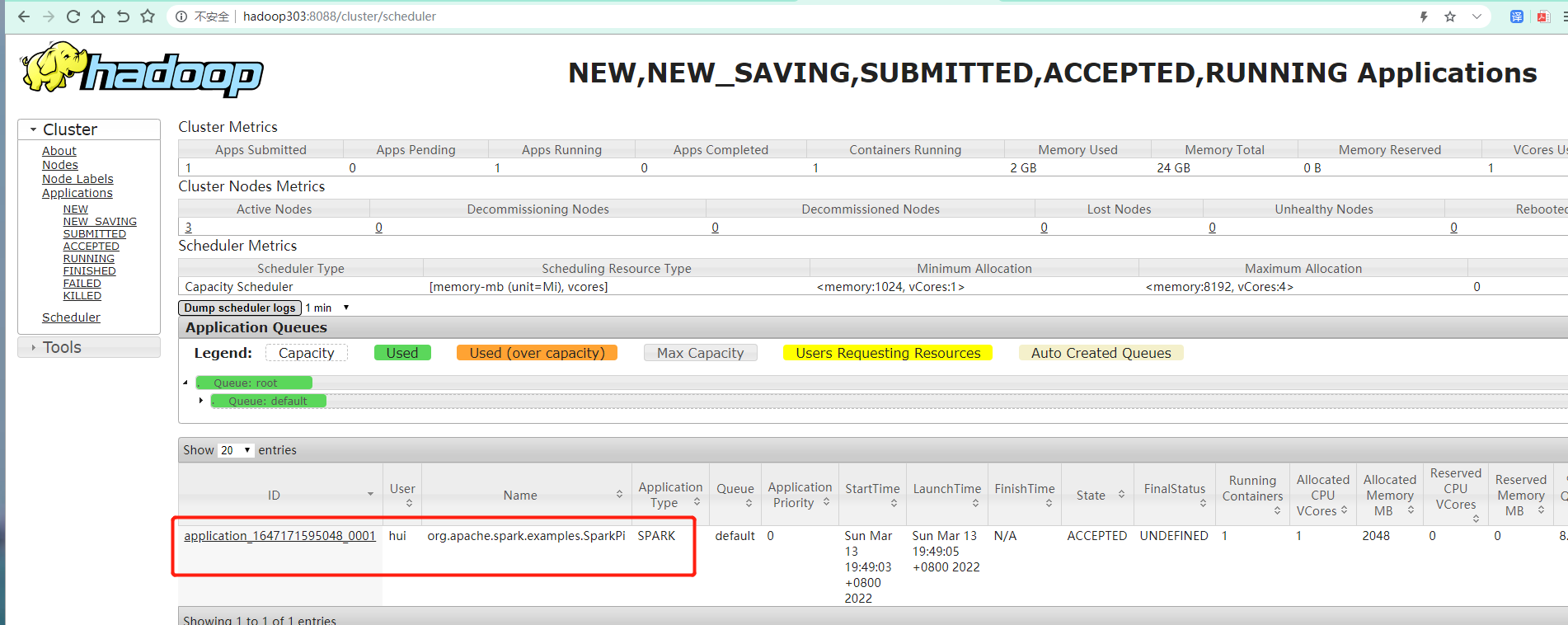
bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master yarn \ --deploy-mode cluster \ ./examples/jars/spark-examples_2.12-3.0.0.jar \ 10
以集群方式提交 --deploy-mode cluster \
注意:yarn \ yarn 后面有个空格否则报错:
Exception in thread "main" org.apache.spark.SparkException: Master must either be yarn or start with spark, mesos, k8s, or local at org.apache.spark.deploy.SparkSubmit.error(SparkSubmit.scala:936) at org.apache.spark.deploy.SparkSubmit.prepareSubmitEnvironment(SparkSubmit.scala:238) at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:871) at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:180) at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:203) at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:90) at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:1007) at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:1016) at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
三、yarn模式配置历史服务器
1、修改spark-default.conf文件,配置日志存储路径
[hui@hadoop302 conf]$ cp spark-defaults.conf.template spark-defaults.conf [hui@hadoop302 conf]$ vim spark-defaults.conf spark.eventLog.enabled true spark.eventLog.dir hdfs://hadoop302:8020/spark_logs spark.yarn.historyServer.address=hadoop302:18080 spark.history.ui.port=18080
注意 日志存储在 hdfs 上,配置路径必须存在
hui@hadoop302 conf]$ hadoop fs -mkdir /spark_logs [hui@hadoop302 conf]$ hadoop fs -ls / Found 8 items drwxr-xr-x - hui supergroup 0 2021-11-24 22:44 /spark_logs
2、编辑spark-env.sh文件, 添加日志配置
#spark_log conf export SPARK_HISTORY_OPTS=" -Dspark.history.ui.port=18080 -Dspark.history.fs.logDirectory=hdfs://hadoop302:8020/spark_logs
参数含义:
- 18080:WEBUI访问的端口号为18080
- hdfs://hadoop302:8020/spark_logs指定历史服务器日志存储路径
- 30:指定保存Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数
分发配置
[hui@hadoop302 conf]$ sxync spark-env.sh
[hui@hadoop302 conf]$ sxync spark-defaults.conf
3、启动历史服务进程
hui@hadoop302 spark_yarn]$ sbin/start-history-server.sh
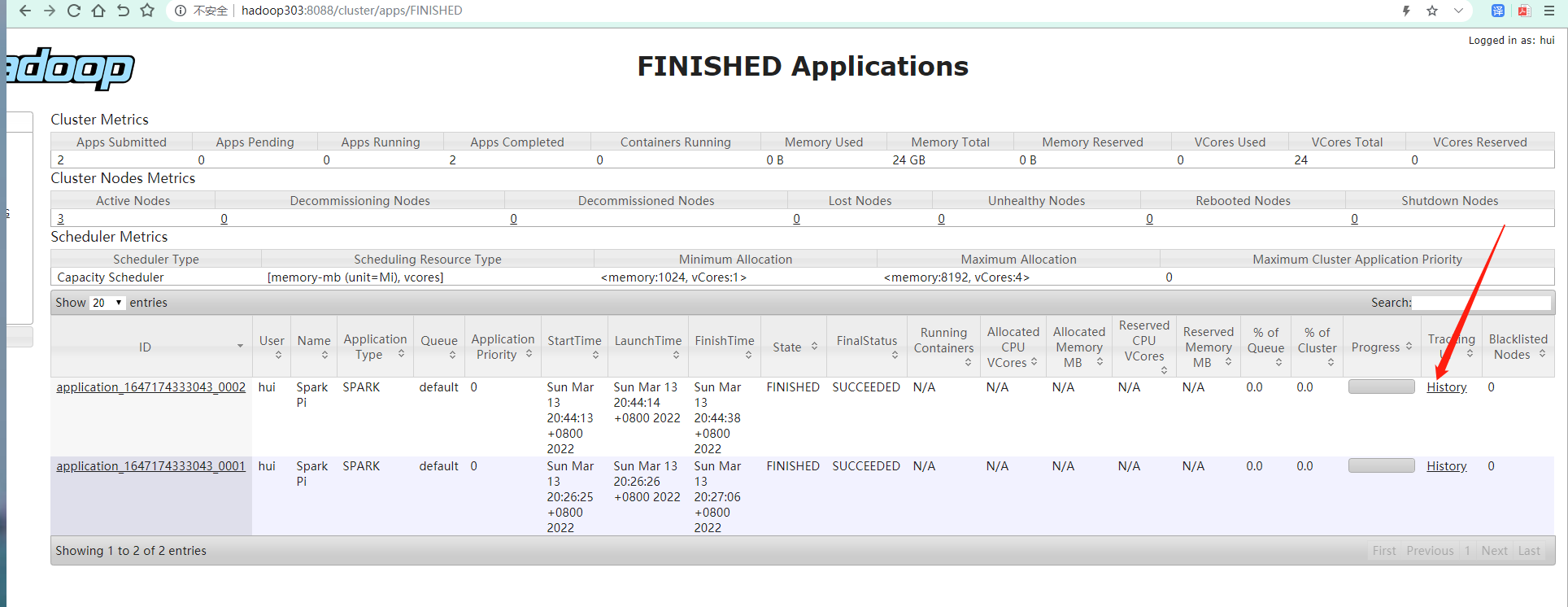
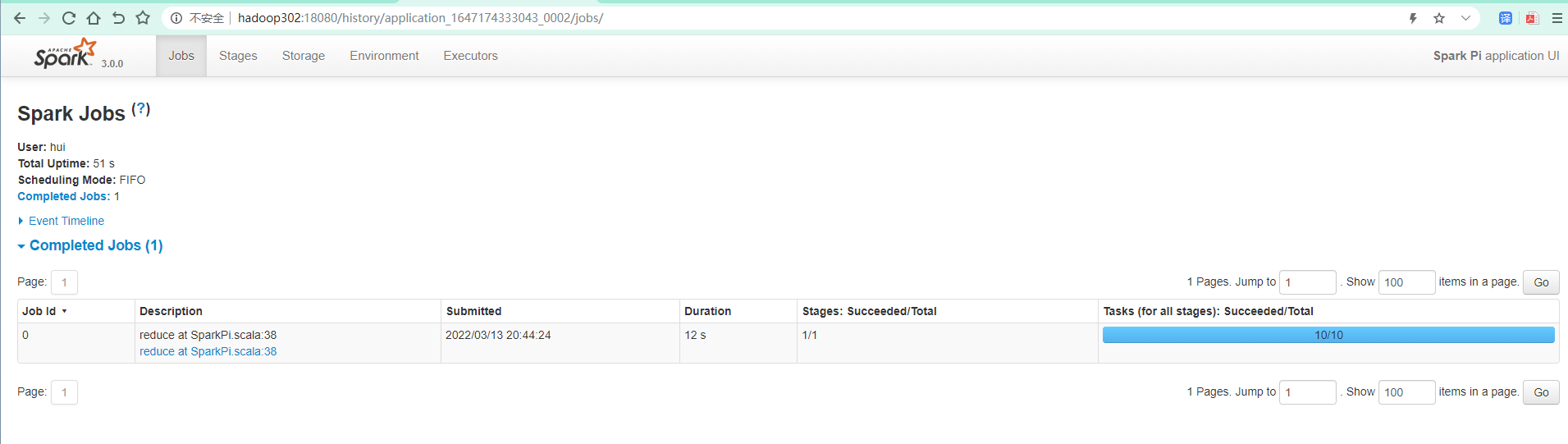
提交应用
bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master yarn \ --deploy-mode client \ ./examples/jars/spark-examples_2.12-3.0.0.jar \ 10

 浙公网安备 33010602011771号
浙公网安备 33010602011771号