

hive 常用函数
一、时间函数
1、date_format:格式化时间
select date_format('2021-05-20','yyyyMMdd') yyyymmdd
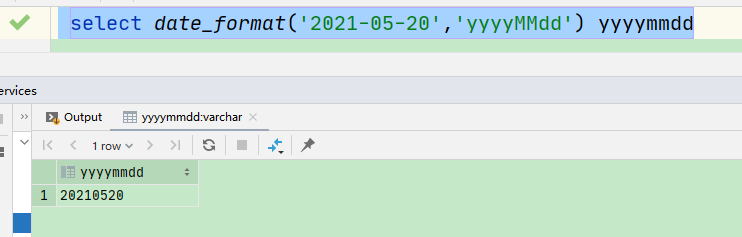
注意写法:date_format('2021-05-20','yyyyMMdd') dd 小写 MM 大写
2、日期加减
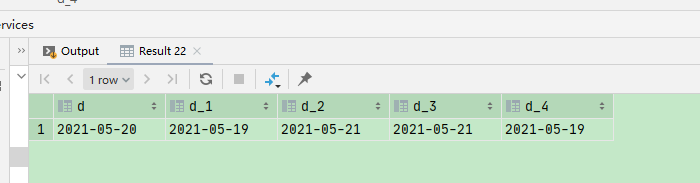
select '2021-05-20' d, date_sub('2021-05-20', 1) d_1, date_sub('2021-05-20', -1) d_2, date_add('2021-05-20', 1) d_3, date_add('2021-05-20', -1) d_4
date_sub 和 date_add 用法一样,注意传参即可;
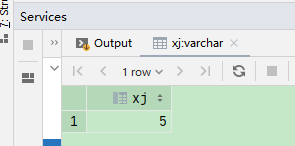
3、datediff:两个时间相减
select datediff('2019-06-29','2019-06-24')
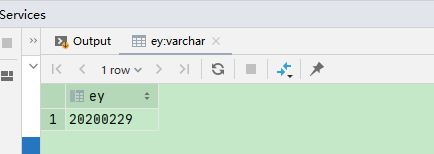
4、last_day 取最后一天
select date_format(last_day(from_unixtime(unix_timestamp('202002', 'yyyyMM'))), 'yyyMMdd');
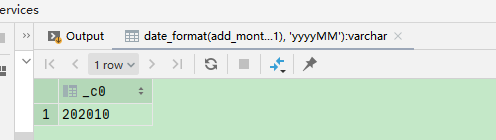
5、add_months 月份
select date_format(add_months(to_date(from_unixtime(unix_timestamp('202009', 'yyyyMM'))), 1), 'yyyyMM');
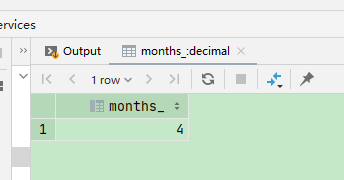
6、months_between 月份差值
select months_between(to_date(from_unixtime(unix_timestamp('202105', 'yyyyMM'))), from_unixtime(unix_timestamp('202101', 'yyyyMM'))) months_
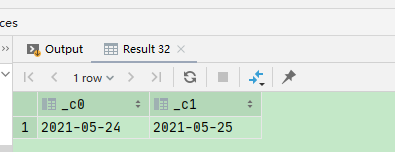
7、next_day函数
select next_day('2021-05-18','MO') ,next_day('2021-05-18','Tuesday');
说明:星期一到星期日的英文(Monday,Tuesday、Wednesday、Thursday、Friday、Saturday、Sunday)
8、返回一个时间的日期,月份和年费
select day('2021-09-21 08:00:00') login_day,month('2021-09-21 08:00:00') login_month, year('2021-09-21 08:00:00') login_year

二、判断函数
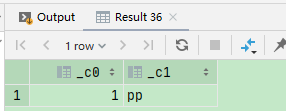
1、nvl(n1,n2)
select nvl(null,1),nvl('pp',1);
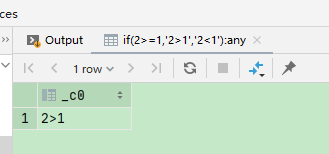
2 if 判断
select if(2 >= 1, '2>1', '2<1');
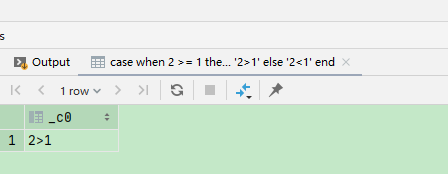
3、case when
select case when 2 >= 1 then '2>1' else '2<1' end;
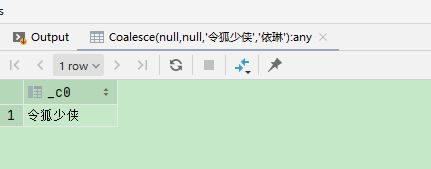
4 Coalesce
Coalesce可以对多个值进行判空校验,只会返回第一个不为空的值,当所有参数都为null时,返回null
select Coalesce(null,null,'令狐少侠','依琳');
三、字符串
select concat('北京', '欢迎', '你') c1, concat('北京', '欢迎', null) c2, concat_ws('-', '欢迎', '你') c3, concat_ws('', '欢迎', '你', null) c4, '欢迎' || null c5
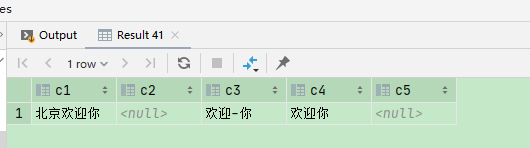
说明 当使用 concat 或 || 拼接字符串,参数为null 时 返回 null ;
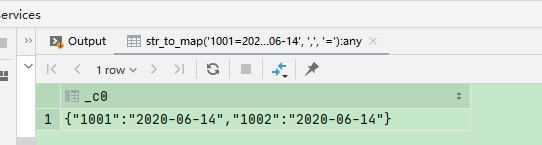
str_to_map
select str_to_map('1001=2020-06-14,1002=2020-06-14', ',', '=')
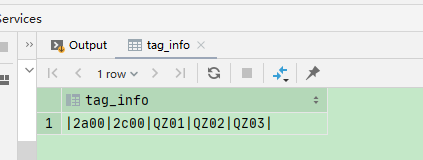
四 列转行
select tag_info from tag_info where province_code='10'
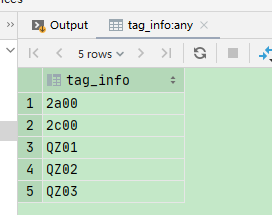
要把数据列式展示
select tag_info from (select substr(substr(regexp_replace(tag_info, '\\|', '\,'), 2), 1, length(substr(regexp_replace(tag_info, '\\|', '\,'), 2)) - 1) tag_info_1 from tag_info where province_code = '10') a lateral view explode(split(tag_info_1, ',')) b as tag_info;

hive> select * from xajh; OK xajh.name xajh.dept xajh.sex 令狐冲 华山 男 任盈盈 日月神 女 风清扬 华山 男 宁中则 华山 女 任我 日月神 男 东方不败 日月神 男 方正 少林 男 方生 少林 男 余沧海 青城 男 依林 衡山 女 依玉 衡山 女 定静 衡山 女 田伯光 衡山 男 余人杰 青城 男 岳灵珊 华山 女
select dept_sex,concat_ws(' - - ',collect_set(name)) from (select concat(dept, ' , ', sex) dept_sex, name from xajh) t1 group by dept_sex;
ept_sex _c1 华山 , 女 宁中则 - - 岳灵珊 华山 , 男 令狐冲 - - 风清扬 少林 , 男 方正 - - 方生 日月神 , 女 任盈盈 日月神 , 男 任我 - - 东方不败 衡山 , 女 依林 - - 依玉 - - 定静 衡山 , 男 田伯光 青城 , 男 余沧海 - - 余人杰
hive> select * from movie_info; OK movie_info.movie movie_info.category 《疑犯追踪》 ["悬疑","动作","科幻","剧情"] 《Lie to me》 ["悬疑","警匪","动作","心理","剧情"] 《战狼 2》 ["战争","动作","灾难"] Time taken: 0.081 seconds, Fetched: 3 row(s) hive> desc movie_info; OK col_name data_type comment movie string category array<string> Time taken: 0.157 seconds, Fetched: 2 row(s)
hive> select explode(category) from movie_info; OK col 悬疑 动作 科幻 剧情 悬疑 警匪 动作 心理 剧情 战争 动作 灾难
hive> select movie, category_name from movie_info lateral view explode(category) table_tmp as category_name; OK movie category_name 《疑犯追踪》 悬疑 《疑犯追踪》 动作 《疑犯追踪》 科幻 《疑犯追踪》 剧情 《Lie to me》 悬疑 《Lie to me》 警匪 《Lie to me》 动作 《Lie to me》 心理 《Lie to me》 剧情 《战狼 2》 战争 《战狼 2》 动作 《战狼 2》 灾难
数字处理
select round(ceiling(751/60) *0.1,2), round(ceiling(30/6) *0.03,2), round(ceiling(161/6) *0.03,2)
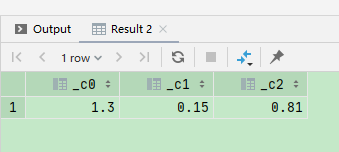
ceiling() 向上取整
round() 小数四舍五入


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 一文读懂知识蒸馏
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下