

Zookeeper 学习(二)Zookeeper 原理概述
1、Zookeeper 内部选举机制
- 半数机制:集群中半数以上机器存活,集群可用。所以Zookeeper适合安装奇数台服务器。
- Zookeeper虽然在配置文件中并没有指定Master和Slave。但是,Zookeeper工作时,是有一个节点为Leader,其他则为Follower,Leader是通过内部的选举机制临时产生的。
- 以一个简单的例子来说明整个选举的过程。
假设有五台服务器组成的Zookeeper集群,它们的id从1-5,同时它们都是最新启动的,也就是没有历史数据,在存放数据量这一点上,都是一样的。假设这些服务器依序启动,来看看会发生什么,如下图所示
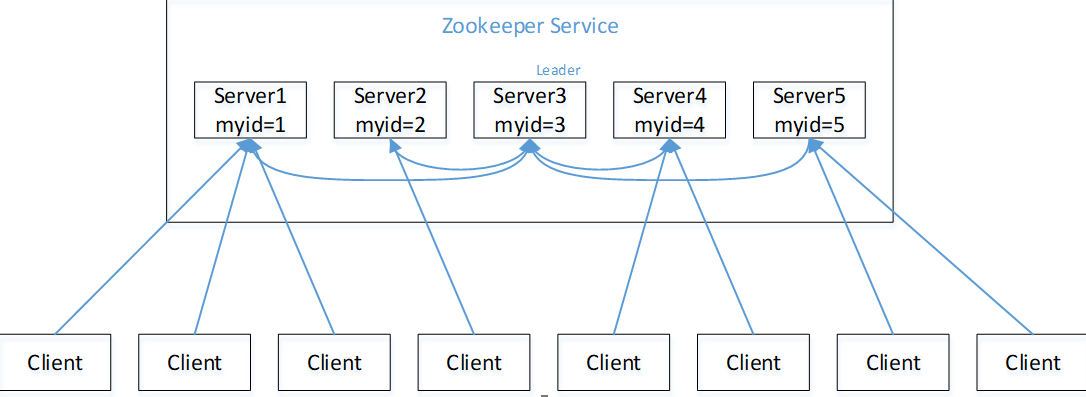
(1)服务器1启动,此时只有它一台服务器启动了,它发出去的报文没有任何响应,所以它的选举状态一直是LOOKING状态。
(2)服务器2启动,它与最开始启动的服务器1进行通信,互相交换自己的选举结果,由于两者都没有历史数据,所以id值较大的服务器2胜出,但是由于没有达到超过半数以上的服务器都同意选举它(这个例子中的半数以上是3),所以服务器1、2还是继续保持LOOKING状态。
(3)服务器3启动,根据前面的理论分析,服务器3成为服务器1、2、3中的老大,而与上面不同的是,此时有三台服务器选举了它,所以它成为了这次选举的Leader。
(4)服务器4启动,根据前面的分析,理论上服务器4应该是服务器1、2、3、4中最大的,但是由于前面已经有半数以上的服务器选举了服务器3,所以它只能接收当小弟的命了。
(5)服务器5启动,同4一样当小弟。
2、节点类型
持久(Persistent):客户端和服务器端断开连接后,创建的节点不删除
短暂(Ephemeral):客户端和服务器端断开连接后,创建的节点自己删除
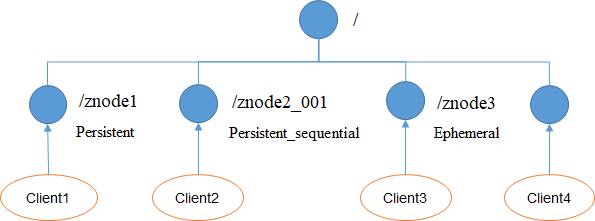
- 持久化目录节点:客户端与Zookeeper断开连接后,该节点依旧存在;
- 持久化顺序编号目录节点:客户端与Zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号;
- 临时目录节点:客户端与Zookeeper断开连接后,该节点被删除;
- 临时顺序编号目录节点:客户端与Zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号;
3、监听原理
监听方法:
- 首先要有一个main()线程;
- 在main线程中创建Zookeeper客户端,这时就会创建两个线程,一个负责网络连接通信(connet),一个负责监听(listener);
- 通过connect线程将注册的监听事件发送给Zookeeper;
- 在Zookeeper的注册监听器列表中将注册的监听事件添加到列表中;
- Zookeeper监听到有数据或路径变化,就会将这个消息发送给listener线程;
- listener线程内部调用了process()方法;
常见监听:
- 监听节点数据的变化 get path [watch]
- 监听子节点增减的变化 ls path [watch]

4、写数据流程
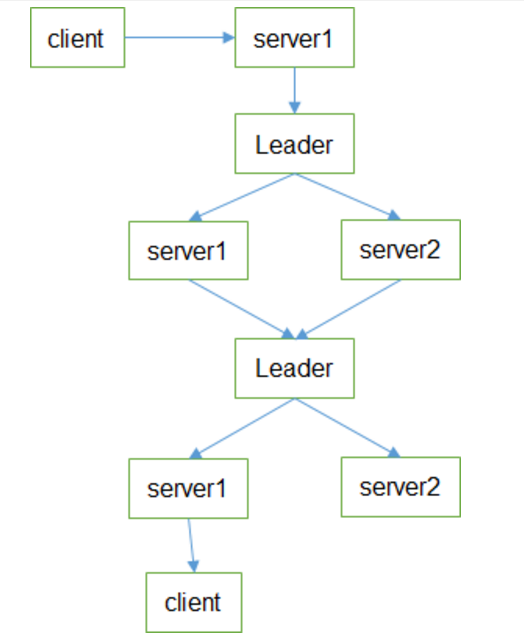
- Client 向 ZooKeeper 的 Server1 上写数据,发送一个写请求。
- 如果Server1不是Leader,那么Server1 会把接受到的请求进一步转发给Leader,因为每个ZooKeeper的Server里面有一个是Leader。这个Leader 会将写请求广播给各个Server,比如Server1和Server2,各个Server写成功后就会通知Leader。
- 当Leader收到大多数 Server 数据写成功了,那么就说明数据写成功了。如果这里三个节点的话,只要有两个节点数据写成功了,那么就认为数据写成功了。写成功之后,Leader会告诉Server1数据写成功了。
- Server1会进一步通知 Client 数据写成功了,这时就认为整个写操作成功。
分类:
Zookeeper


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 一文读懂知识蒸馏
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下