Hadoop 学习笔记(十六)Combiner 合并和 GroupingComparator辅助排序
1、Combiner 简介
- Combiner是MR程序中Mapper和Reducer之外的一种组件。
- Combiner组件的父类就是Reducer。
- Combiner和Reducer的区别在于运行的位置;
- Combiner是在每一个MapTask所在的节点运行;
- Reducer是接收全局所有Mapper的输出结果;
- Combiner的意义就是对每一个MapTask的输出进行局部汇总,以减小网络传输量。
- Combiner能够应用的前提是不能影响最终的业务逻辑,而且,Combiner的输出kv应该跟Reducer的输入kv类型要对应起来;
2、Combiner 简单实现
以 WordCount 为例,直接在 Driver 程序里输入下面一行代码,即可实现合并
// 指定需要使用Combiner,以及用哪个类作为Combiner的逻辑 job.setCombinerClass(WordcountReducer.class);
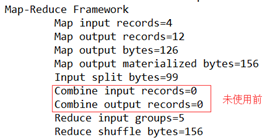
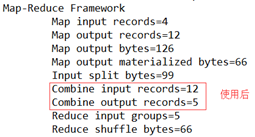
3、GroupingComparator分组(辅助排序)
对Reduce阶段的数据根据某一个或几个字段进行分组。
分组排序步骤:
(1)自定义类继承WritableComparator
(2)重写compare()方法
4、GroupingComparator分组
案例
输入数据
0000001 Pdt_01 222.8 0000002 Pdt_05 722.4 0000001 Pdt_02 33.8 0000003 Pdt_06 232.8 0000003 Pdt_02 33.8 0000002 Pdt_03 522.8 0000002 Pdt_04 122.4
输出每组金额最大值;
OrderBean.java
 View Code
View Code
OrderGrouping.java

public class OrderGrouping extends WritableComparator { protected OrderGrouping() { super(OrderBean.class, true); } @Override public int compare(WritableComparable a, WritableComparable b) { OrderBean aBean = (OrderBean) a; OrderBean bbean = (OrderBean) b; // 只要 ID 相同,就认为是 相同的 Key int r; if (aBean.getOrderId() > bbean.getOrderId()) { r = 1; } else if (aBean.getOrderId() < bbean.getOrderId()) { r = -1; } else { r = 0; } return r; } }
OrderMapper.java
public class OrderMapper extends Mapper<LongWritable, Text, OrderBean, NullWritable> { OrderBean k = new OrderBean(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 1、 获取一行 String line = value.toString(); // 2、切割 String[] fields = line.split("\t"); // 3、获取对象 k.setOrderId(Integer.parseInt(fields[0])); k.setPrice(Double.parseDouble(fields[2])); // 4、写出 context.write(k, NullWritable.get()); } }
OrderReduce.java
public class OrderReduce extends Reducer<OrderBean, NullWritable, OrderBean, NullWritable> { @Override protected void reduce(OrderBean key, Iterable<NullWritable> value, Reducer<OrderBean, NullWritable, OrderBean, NullWritable>.Context context) throws IOException, InterruptedException { // TODO Auto-generated method stub context.write(key, NullWritable.get()); } }
OrderDriver.java
public static void main(String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException { // 输入输出路径需要根据自己电脑上实际的输入输出路径设置 args = new String[] { "E:/input/ord", "E:/output11" }; // 1 获取配置信息 Configuration conf = new Configuration(); Job job = Job.getInstance(conf); // 2 设置jar包加载路径 job.setJarByClass(OrderDriver.class); // 3 加载map/reduce类 job.setMapperClass(OrderMapper.class); job.setReducerClass(OrderReduce.class); // 4 设置map输出数据key和value类型 job.setMapOutputKeyClass(OrderBean.class); job.setMapOutputValueClass(NullWritable.class); // 5 设置最终输出数据的key和value类型 job.setOutputKeyClass(OrderBean.class); job.setOutputValueClass(NullWritable.class); // 6 设置输入数据和输出数据路径 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 设置分组排序 job.setGroupingComparatorClass(OrderGrouping.class); boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号