Hadoop 学习笔记(四)HDFS 简介
一、HDFS 产生的背景
Hadoop 的三大组成为:HDFS、YARN 和 Map Reduce,今天我们主要探讨 HDFS。
随着数据量的越来越大,在一个操作系统无法存放所有的数据,那么就需要将数据分派到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是 Hadoop 分布式文件管理系统,HDFS 是分布式文管理系统的一种。
二、HDFS 的定义
HDFS(Hadoop Distribute File System),是一种文件系统,用户存储文件,通过目录树来定位文件,其次:它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器由各自的角色;
HDFS 使用场景:适合一次写入,多次读取的场景,且不支持文件修改,适合用来做数据分析,并不适合用来做磁盘应用。
三、HDFS 优缺点
1、HDFS 优点

2、HDFS 缺点

个人理解:HDFS 不适合存储大量小文件:每一个文件都有各自的属性信息,路径,快信息,这些数据是存储在 namaenode 上的,如果小文件的数据量非常大,并且数据量还在增加的话,那么 NameNode 的压力是可想而知的;小文件过多,也会影响数据的寻址时间;举个例子:一块豆腐,切成 10 份并标记 0~10 的数字,和同样大小快豆腐切成1W快,并进行标记 1~10000,去找到 指定标号的小快豆腐,后者是必用更多的时间找到的。
四、HDFS 系统架构
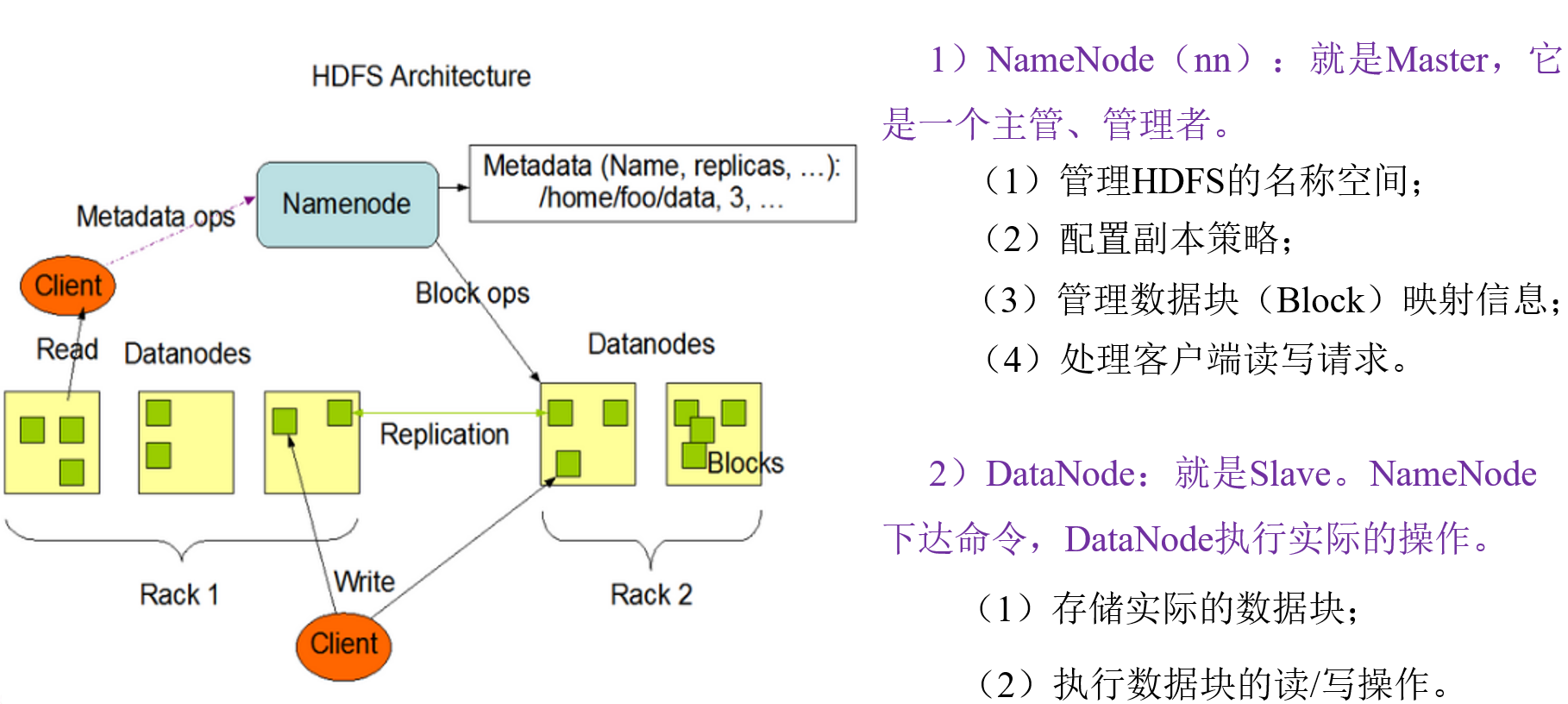

五、HDFS 块文件大小
HDFS 文件在物理上是分块(Block)存储,块的大小可以通过配置参数(dfs.blocksize)来实现个性化修改,Hadoop 2.x 版本默认块大小是 128M,老版本 Hadoop 默认64M,
134217728 字节 134217728/1024/1024=128M
<property> <name>dfs.blocksize</name> <value>134217728</value> <description> The default block size for new files, in bytes. You can use the following suffix (case insensitive): k(kilo), m(mega), g(giga), t(tera), p(peta), e(exa) to specify the size (such as 128k, 512m, 1g, etc.), Or provide complete size in bytes (such as 134217728 for 128 MB). </description> </property>
思考:为什么 HDFS 的块大小不能设置的太大?也不能设置的太小?
若 HDFS 文件设置的太小,相同数据大小的数据的块的数量就会增加,会增加寻址时间,程序会一直在程序的开始位置;
若 HDFS 文件设置的太大,从磁盘传输数据的时间会明显大于磁盘寻址所花费的时间,导致程序在处理块数据时变得非常慢;
HDFS 设置块的大小应主要取决于磁盘传输的效率,其实就是取决于机器的性能;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号