数据清洗
数据清洗的概念
专业定义
数据清洗是从记录表、表格、数据库中检查、纠正或删除损坏或不准确记录的过程。
专业名词
脏数据
没有经过处理自身含有一定问题的数据(缺失、异常、重复......)
干净数据
经过处理的完全符合规范要求的数据

常用方法
1.读取外部数据
read_csv read_excel read_sql read_html
2.数据概览
index、colums、head、tail、shape、describe、info、dtypes
3.简单处理
移除首尾空格,大小写转换......
4.重复值处理
duplicated() # 查看是否含有重复数据 drop_duplicates() # 删除重复数据
5.缺失值处理
删除缺失值、填充缺失值
6.异常值处理
删除异常值、修正异常值(当作缺失值处理)
7.字符串处理
切割、筛选......
8.时间格式处理
Y(年) m(月) d(日) H(时) M(分) S(秒)
步骤3到8没有固定的顺序,只不过前期不熟练的情况下可以如此执行
数据概览
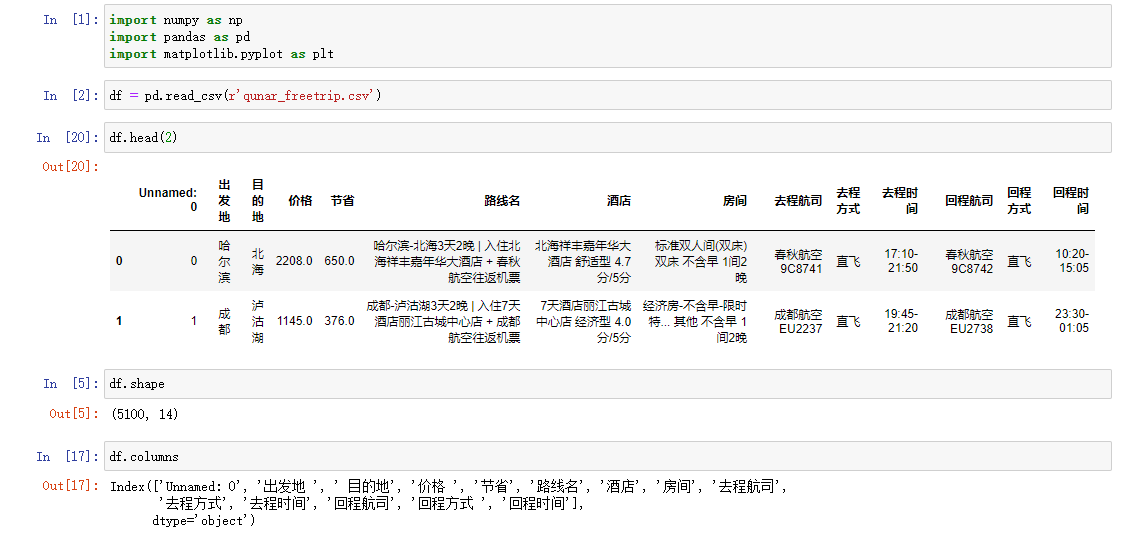
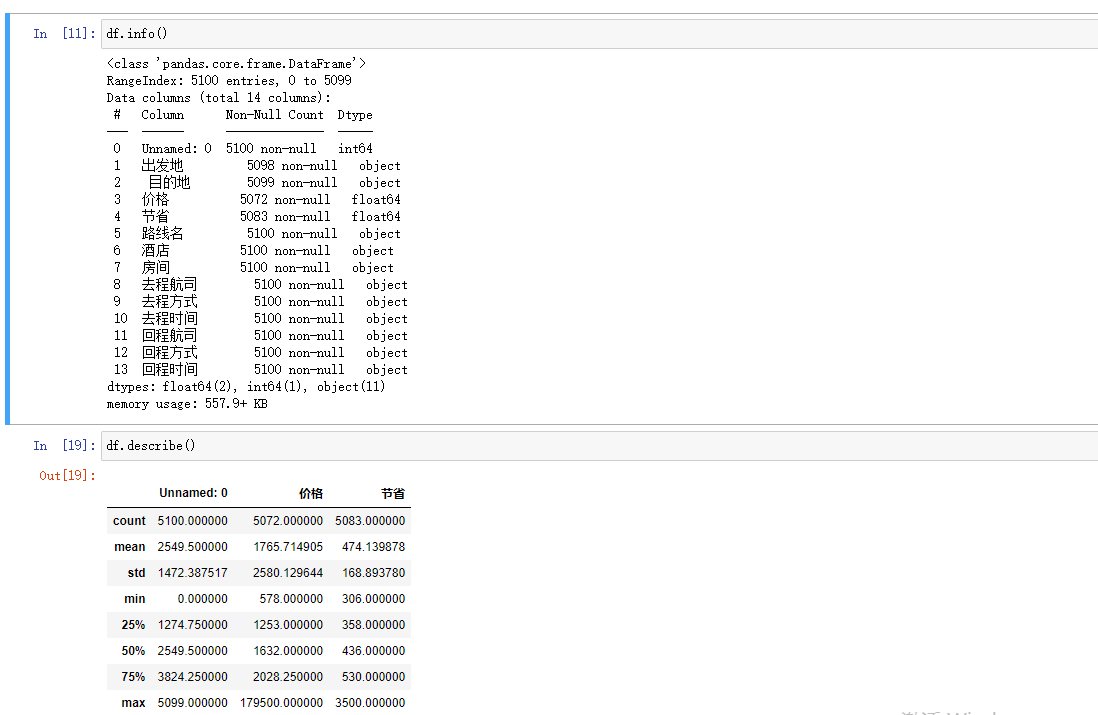
import numpy as np import pandas as pd import matplotlib.pyplot as plt df = pd.read_csv(r'qunar_freetrip.csv') # 1.查看前五条数据 掌握大概 df.head() # 2.查看表的行列总数 df.shape # 3.查看所有的列字段 df.columns # 发现列字段有一些是有空格的 # 4.查看数据整体信息 df.info() # 发现去程时间和回程时间是字符串类型需要做日期类型转换 # 5.快速统计 df.describe() df.columns
列字段处理
删除无用字段
df.drop(columns='Unnamed: 0',axis=1,inplace=True)
获取列字段
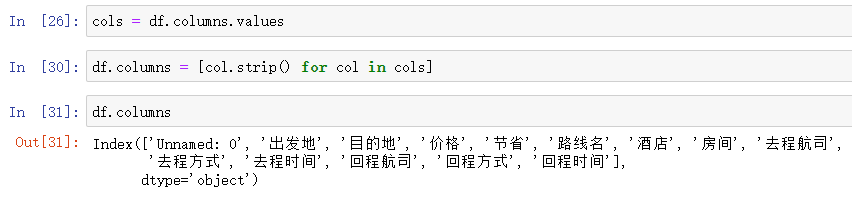
col = df.columns.values

for循环依次取出列字段首位的空格
方式1
ccs = []
for col in cols:
ccs.append(col.strip())
print(ccs)

方式2:列表生成式
df.columns = [col.strip() for col in cols]
重复值处理
重复数据查找
df.dupliacted()
简单看看重复数据的模样(布尔值索引)

针对重复的数据一般都是直接删除的
df.drop_dupliactes(inplace=True)
如何获取表的行索引值
df.index

右侧加上赋值符号就是修改行索引值
df.index = range(0,df.shape[0]) df.tail()
异常值处理
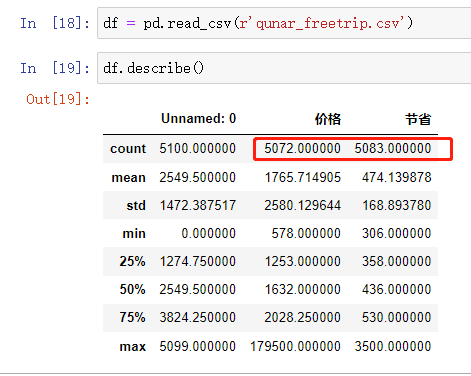
利用快速统计大致筛选出肯有异常数据的字段
df.describe() # 价格小于节省,那么可能是价格有问题或者节省有问题
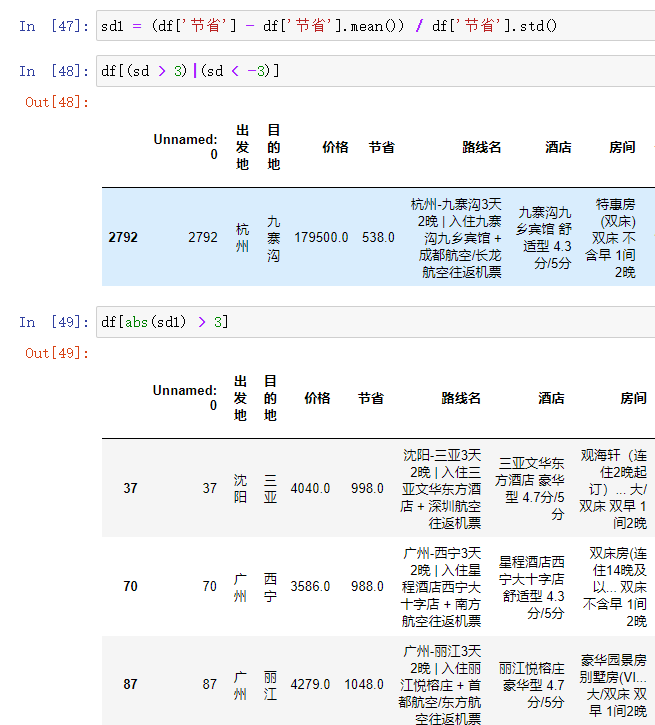
利用公式求证猜想
sd = (df['价格'] - df['价格'].mean()) / df['价格'].std() # 判断的标准 # 利用逻辑索引筛选数据 df[(sd > 3)|(sd < -3)] # 利用绝对值 df[abs(sd) > 3] # abs就是绝对值的意思(移除正负号)

同理验证节省是否有异常
# 同理验证节省是否有异常(不一定要使用) # sd1 = (df['节省'] - df['节省'].mean()) / df['节省'].std() # 判断的标准 # 利用逻辑索引筛选数据 # df[(sd > 3)|(sd < -3)] # 利用绝对值 # df[abs(sd1) > 3] # abs就是绝对值的意思(移除正负号)
直接简单粗暴找节省大于价格的数据
df[df['节省'] > df['价格']]
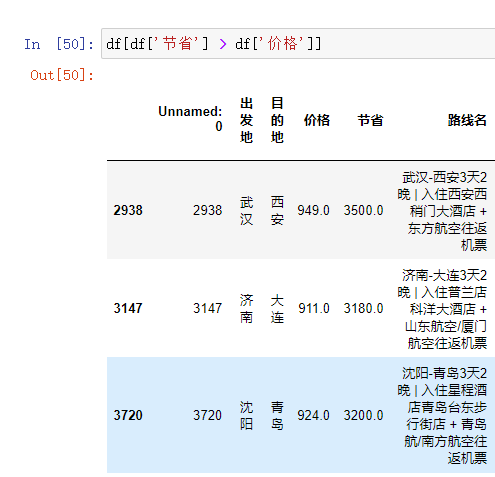
删除价格和节省都有异常的数据
方式1:先拼接,再一次性删除
# 横向合并pd.merge() # 纵向合并pd.concat() # res = pd.concat([df[df['节省'] > df['价格']],df[abs(sd) > 3]]) ## 获取要删除的行数据 索引值 # del_index = res.index # 根据索引删除数据 df.drop(index=del_index,inplace=True) # 再次重置索引 df.index = range(0,df.shape[0])
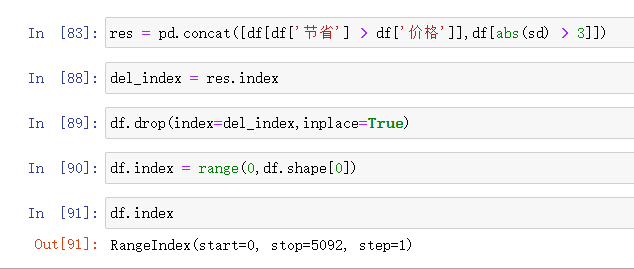
方式2: 得出一个结果就删一个
出发地的缺失值处理
查找具有缺失值的列名称
df.isnull().sum() # 统计每个字段缺失数据条数

利用布尔值索引筛选出出发地有缺失的数据
df[df.出发地.isnull()]

获取出发地缺失的数据的路线数据
df.loc[df.出发地.isnull(),'路线名'].values

利用字符串切割替换出发地缺失数据
df.loc[df.出发地.isnull(),'出发地'] = [i.split('-')[0] for i in df.loc[df.出发地.isnull(),'路线名'].values]

操作数据的列字段需要使用loc方法
针对缺失值的处理
采用数学公式依据其他数据填充
缺失值可能在其他单元格中含有
如果缺失值数量展示很小可删除
目的地的缺失值处理
# 针对目的地操作如下(筛选要比出发地难!!!) # df[df.目的地.isnull()] # 获取目的地缺失的路线数据 # df.loc[df.目的地.isnull(),'路线名'].values # 利用正则筛选出目的地 import re # 案例演示 reg_exp = '-(.*?)\d' # res = re.findall(reg_exp,'深圳-秦皇岛3天2晚 | 入住大连黄金山大酒店 + 南方航空/东海往返机票') df.loc[df.目的地.isnull(),'目的地'] = [re.findall(reg_exp,i) for i in df.loc[df.目的地.isnull(),'路线名'].values]
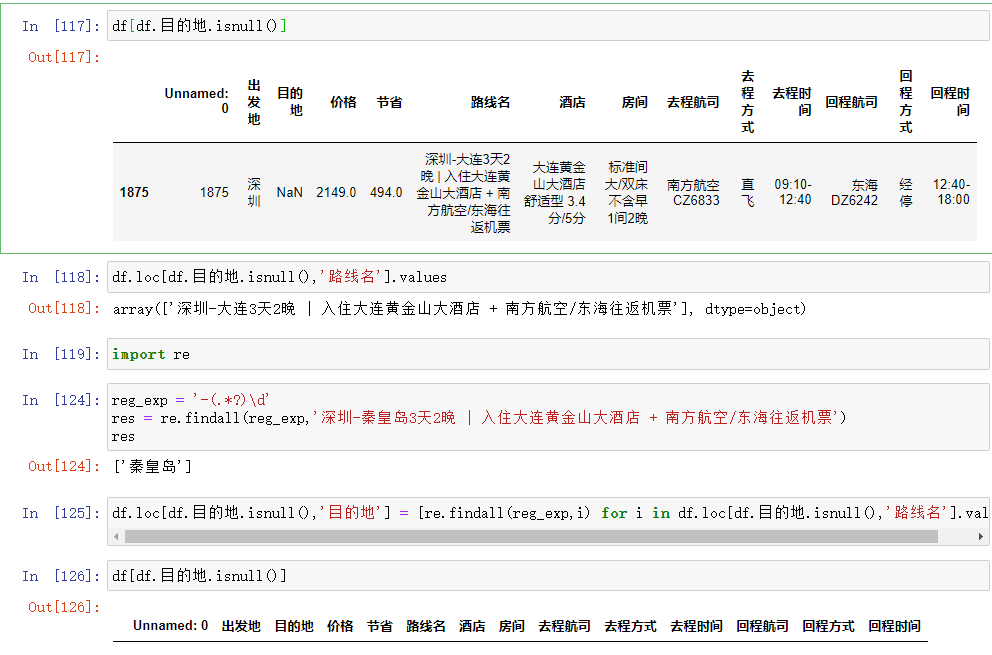
补充
MySQL中如何快速判断某列是否含有重复的数据
思路
统计某个字段下的数据的个数,再利用去重操作,两者结合判断
select count(name) from userinfo; select count(distinct(name)) from userinfo;
如果两者数组相同表示name列没有重复的数据,不同表示含有重复的数据。
小练习
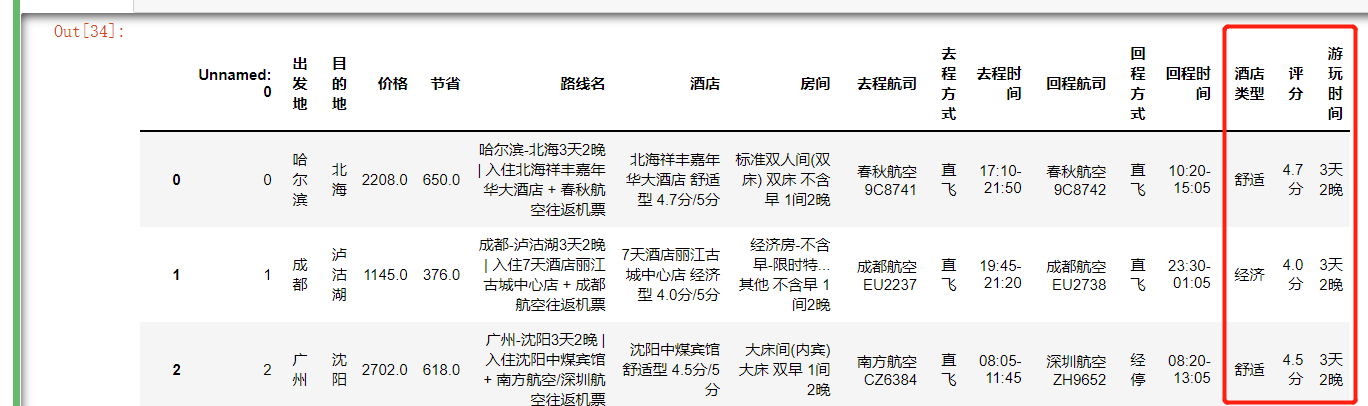
给表多加几列:酒店类型,评分游玩时间
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import re
df = pd.read_csv(r'qunar_freetrip.csv')
cols = df.columns.values
an_list = []
res = df['酒店']
r = '(.*?)型'
for i in res:
k = i.split(' ')[1]
res2 = re.findall(r,k)
if not res2:
an1 = 'none'
else:
an1 = res2[0]
an_list.append(an1)
r2 = '(.*?)分'
an_list2 = []
for i2 in res:
k1 = i2.split('/')[0]
res3 = k1.split(' ')[-1]
an_list2.append(res3)
path_name = df['路线名']
time_cost = []
for i3 in path_name:
k4 = i3.split('|')[0]
k5 = k4.split('-')[1][-5:-1]
time_cost.append(k5)
df['酒店类型'] = an_list
df['评分'] = an_list2
df['游玩时间'] = time_cost
df