

pandas模块与dataframe
增
res['a'] = 123
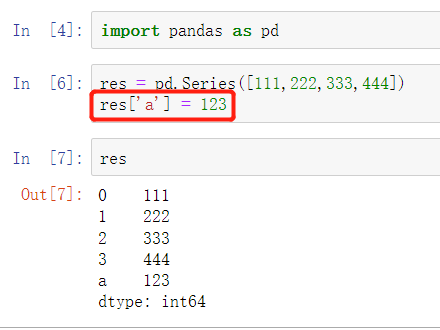
查
res.loc[1]

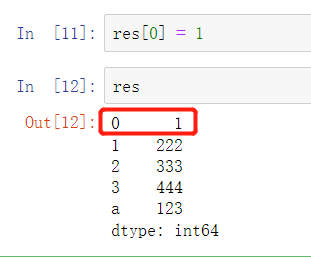
改
res[0] = 1
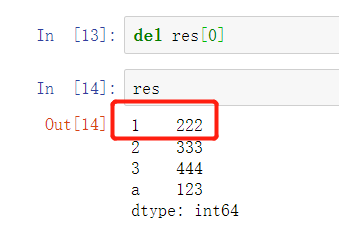
删
del res[0]
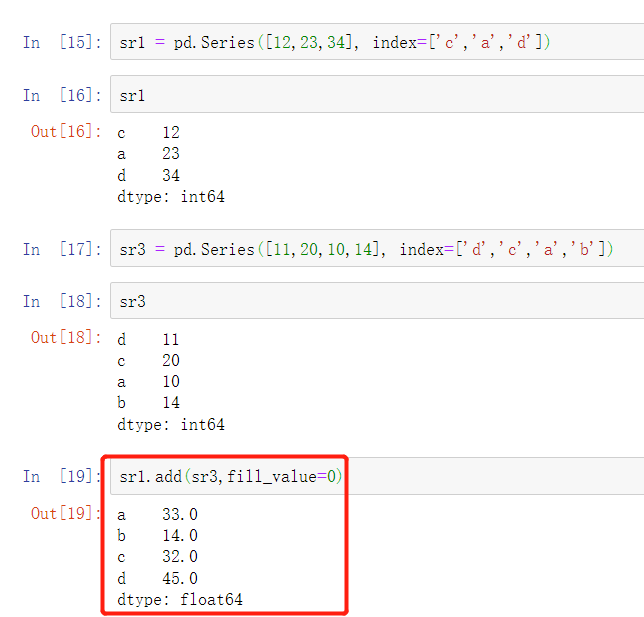
算术运算符
""" add 加(add) sub 减(substract) div 除(divide) mul 乘(multiple) """ sr1 = pd.Series([12,23,34], index=['c','a','d']) sr3 = pd.Series([11,20,10,14], index=['d','c','a','b']) sr1.add(sr3,fill_value=0)
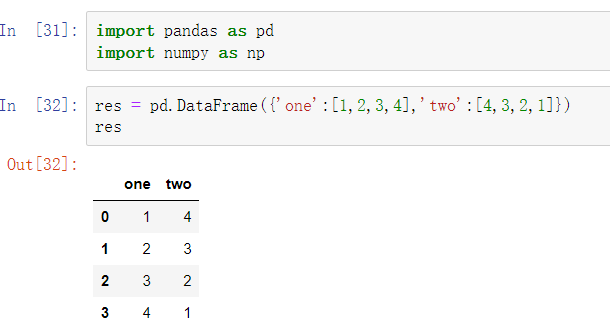
第一种
res = pd.DataFrame({'one':[1,2,3,4],'two':[4,3,2,1]})
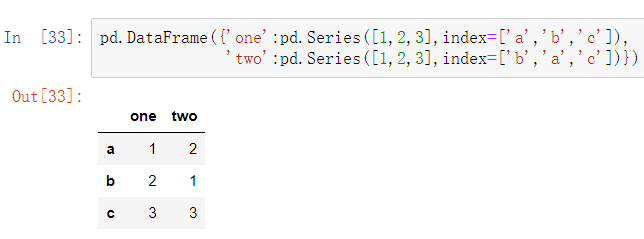
第二种
pd.DataFrame({'one':pd.Series([1,2,3],index=['a','b','c']),
'two':pd.Series([1,2,3],index=['b','a','c'])})
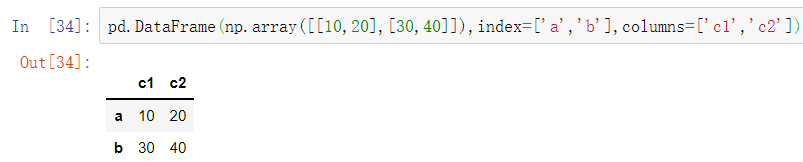
第三种
pd.DataFrame(np.array([[10,20],[30,40]]),index=['a','b'],columns=['c1','c2'])
更多
pd.DataFrame([np.arange(1,8),np.arange(11,18)])
s1 = pd.Series(np.arange(1,9,2))
s2 = pd.Series(np.arange(2,10,2))
s3 = pd.Series(np.arange(5,7),index=[1,2])
df5 = pd.DataFrame({'c1':s1,'c2':s2,'c3':s3})
以上创建方式都仅仅做一个了解即可,因为工作中dataframe的数据一般都是来自于读取外部文件数据,而不是自己手动去创建。
1.index 行索引
2.columns 列索引
3.T 转置
4.values 值索引
5.describe 快速统计
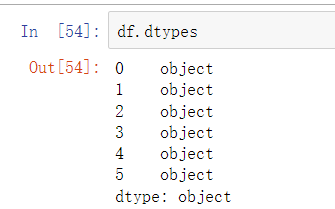
在DataFrame中所有的字符类型数据在查看数据类型的时候都表示成object
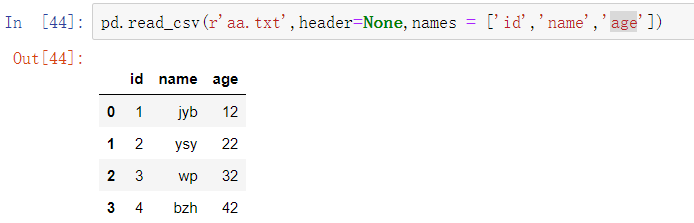
读取文本文件和.csv结尾的文件数据
pd.read_csv()
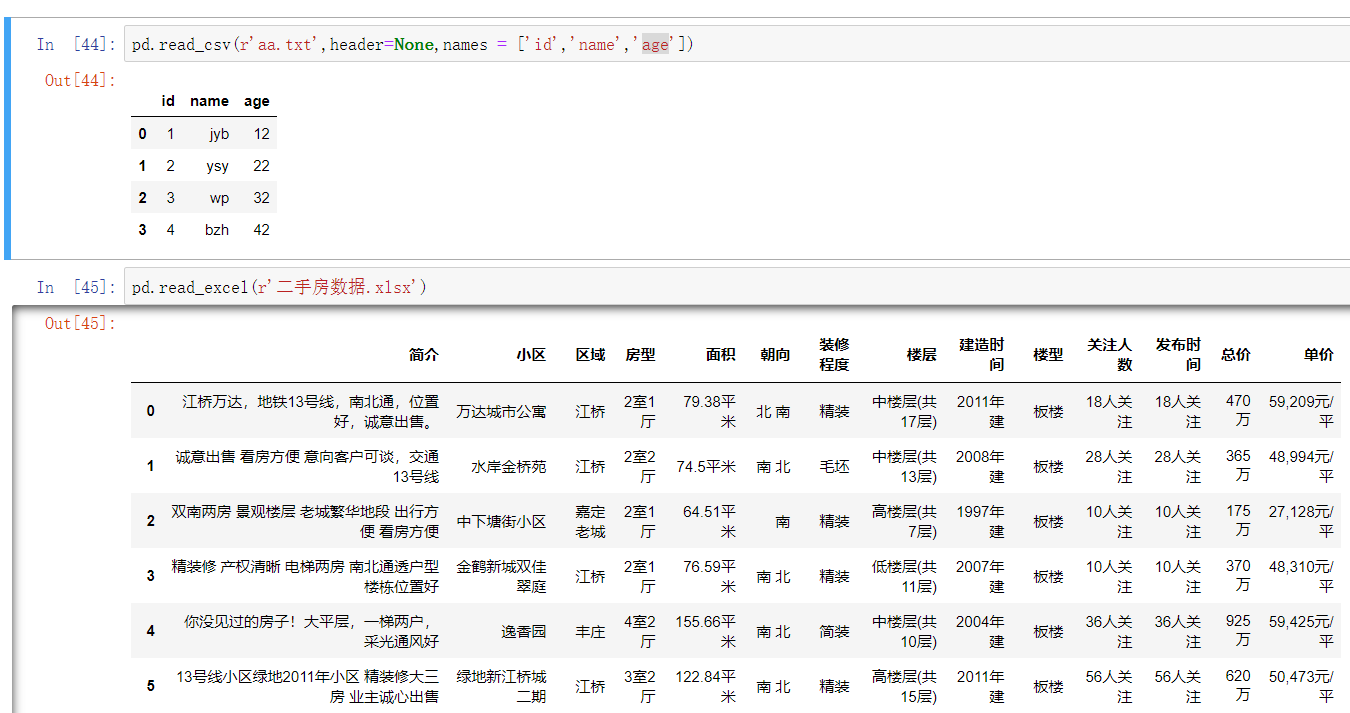
读取excel表格文件数据
pd.read_excel()
读取MySQL表格数据
pd.read_sql()
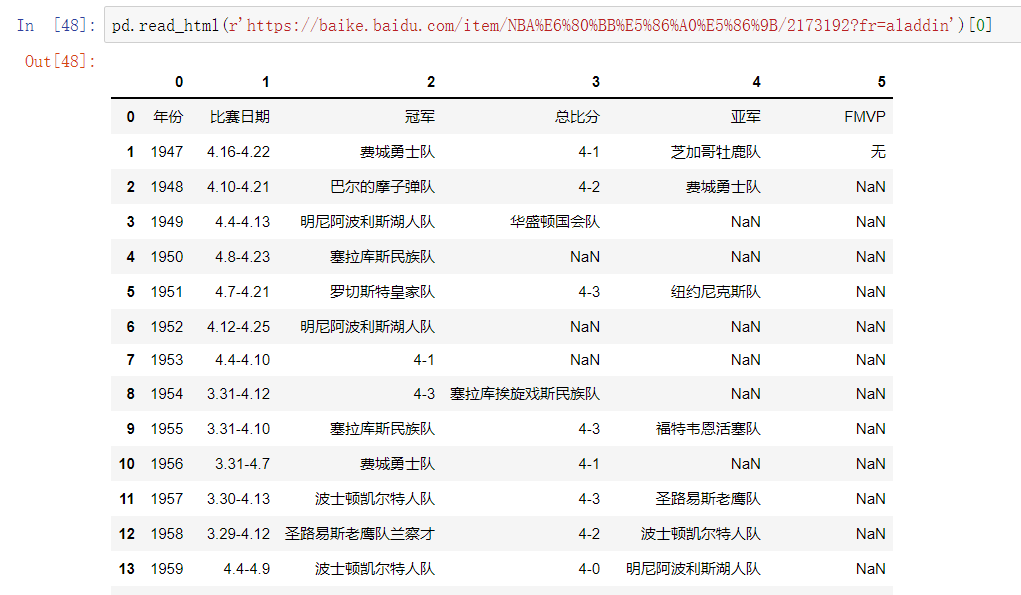
读取页面上table标签内所有的数据
pd.read_html()
文本文件读取
pd.read_csv(filepath_or_buffer, sep=',', header='infer', names=None, usecols=None, skiprows=None, skipfooter=None, converters=None, encoding=None)
filepath_or_buffer
指定txt文件或csv文件所在的具体路径
sep
指定原数据集中各字段之间的分隔符,默认为逗号”,”

header
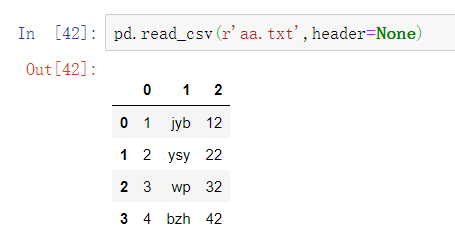
是否需要将原数据集中的第一行作为表头,默认将第一行用作字段名称 ,如果原始数据没有表头需要将该参数设置为None
names
如果原数据集中没有字段,可以通过该参数在数据读取时给数据框添加具体的表头
usecols
指定需要读取原数据集中的哪些变量名
skiprows
数据读取时,指定需要跳过原数据集开头的行数
有一些表格开头是有几行文字说明的,读取的时候应该跳过
skipfooter
数据读取时,指定需要跳过原数据集末尾的行数
converters
用于数据类型的转换(以字典的形式指定)
encoding
如果文件中含有中文,有时需要指定字符编码
pd.read_excel(io, sheetname=0, header=0, skiprows=None, skip_footer=0, index_col=None, names=None, na_values=None, thousands=None, convert_float=True)
pd.read_excel(r'data_test02.xlsx',
header = None,
names = ['ID','Product','Color','Size'],
converters = {'ID':str}
)
io
指定电子表格的具体路径
sheet—name
指定需要读取电子表格中的第几个Sheet,既可以传递整数也可以传递具体的Sheet名称
header
是否需要将数据集的第一行用作表头,默认为是需要的
skiprows
读取数据时,指定跳过的开始行数
skip_footer
读取数据时,指定跳过的末尾行数
index_col
指定哪些列用作数据框的行索引(标签)
na_values
指定原始数据中哪些特殊值代表了缺失值
thousands
指定原始数据集中的千分位符
convert_float
默认将所有的数值型字段转换为浮点型字段
converters
通过字典的形式,指定某些列需要转换的形式
# 在anaconda环境下直接安装
# pymysql模块
import pymysql
conn = pymysql.connect(host,port,user,password, database, charset)
# 利用pymysql创建好链接MySQL的链接之后即可通过该链接操作MySQL
pd.read_sql('select * from user', con = conn)
conn.close() # 关闭链接
host
指定需要访问的MySQL服务器
port
指定访问MySQL数据库的端口号 charset:指定读取MySQL数据库的字符集,如果数据库表中含有中文,一般可以尝试将该参数设置为 “utf8”或“gbk”
user
指定访问MySQL数据库的用户名
password
指定访问MySQL数据库的密码
database
指定访问MySQL数据库的具体库名
pd.read_html(r'https://baike.baidu.com/item/NBA%E6%80%BB%E5%86%A0%E5%86%9B/2173192?fr=aladdin')[0]
查看行
df.columns

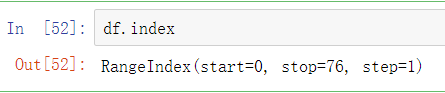
查看列
df.index
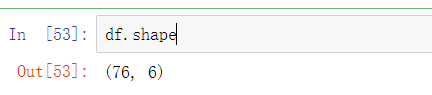
行列
df.shape
数据类型
df.dtypes
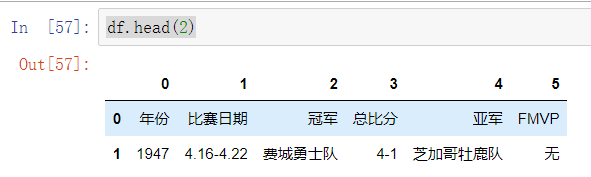
取头部多条数据
df.head(2)
取尾部多条数据
df.tail(3)

获取指定列对应的数据
df['列字段名词']
df.rename(column={'旧列名称':'新列名称'})

创建新的列
df['新列名称']=df.列名称/(df.列名称1+df.列名称2)
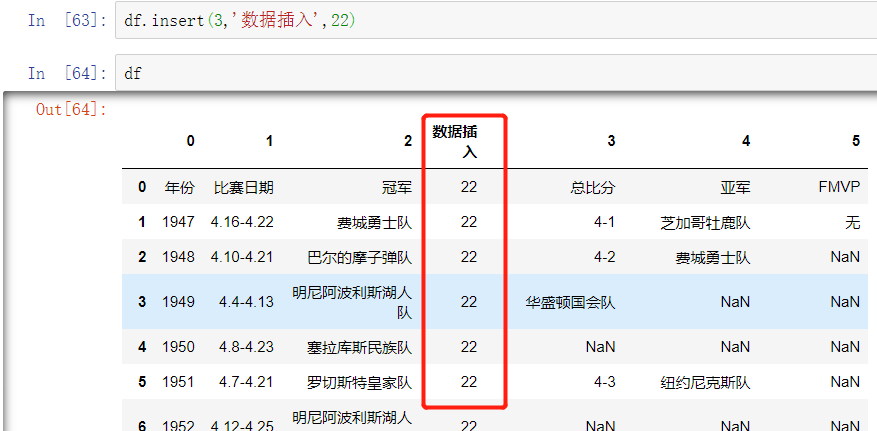
自定义位置
df.insert(3,'新列名称',新数据)
添加行
df3 = df1.append(df2)
获取指定列数据
df['列名'] # 单列数据 df[['列名1','列名2',...]] # 多列数据
获取指定行数据
sec_buildings.loc[sec_buildings["region"] == '浦东'] sec_buildings.loc[(sec_buildings["region"] == '浦东') & (sec_buildings['size'] > 150),] sec_buildings.loc[(sec_buildings["region"] == '浦东') & (sec_buildings['size'] > 150),['name','tot_amt','price_unit']]


sec_car = pd.read_csv(r'sec_cars.csv') sec_car.head() sec_car.dtypes sec_car.Boarding_time = pd.to_datetime(sec_car.Boarding_time, format = '%Y年%m月') sec_car.New_price = sec_car.New_price.str[:-1].astype(float)
