pandas模块
pandas模块简介
基于Numpy构建
pandas的出现,让python语言成为使用最广泛而且最强道德数据分析语言。
pandas针对表格文件的操作有非常大的优势,尤其是数据量超过10万的。

pandas的主要功能
具备诸多功能的两大数据结构
Serise,DataFrame都是基于Numpy构建出来的,公司中使用频繁的是DataFrame,而Series是构成DataFrame的基础,即一个DataFrame可能由N个Serises构成
集成时间序列功能
提供丰富的数学运算和操作
灵活处理缺失数据
安装与导入
python纯开发环境下安装
pip3 install pandas
anaconda环境下安装
conda install pandas
导入
import pandas import pandas as pd # 更加习惯给它起一个别名pd

补充
数据分析三剑客由于使用频率很高,所以在很多ipynb文件的开头都会提前导入
import numpy as np import pandas as pd ...
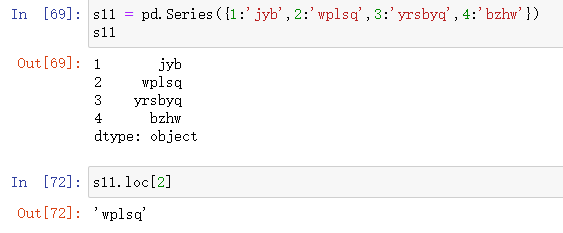
数据类型之Series
是一种类似于一维数组对象,由数据和相关的标签(索引)组成
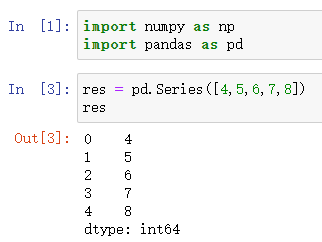
第一种
pd.Series([4,5,6,7,8])
第二种
pd.Series([4,5,6,7,8],index=['a','b','c','d','e'])

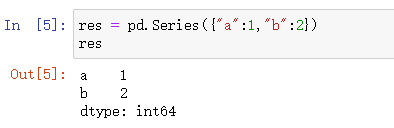
第三种
pd.Series({"a":1,"b":2})
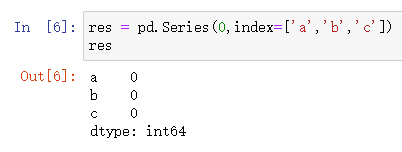
第四种
pd.Series(0,index=['a','b','c'])
缺失数据概念
在数据处理中如果遇到NaN关键字,那么意思就是缺失数据,并且NaN属于浮点型。
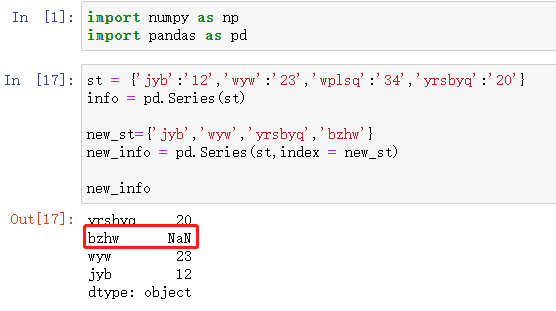
dropna()
过滤掉值为NaN的行
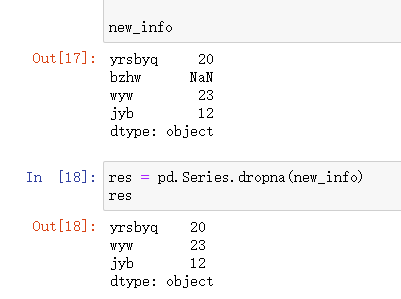
fillna()
填充缺失数据
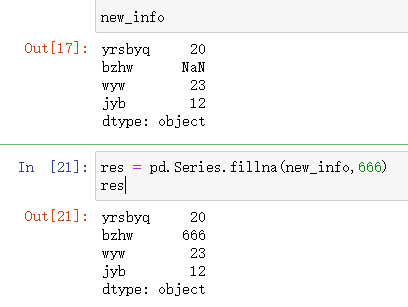
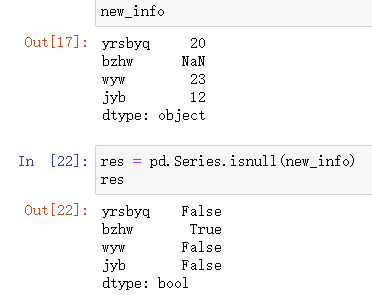
isnull()
返回布尔类型
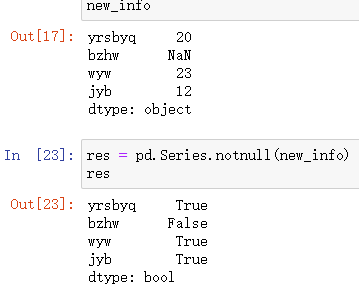
notnull()
返回布尔数组
数据修改规则
如果执行操作之后有结果说明原数据没有变
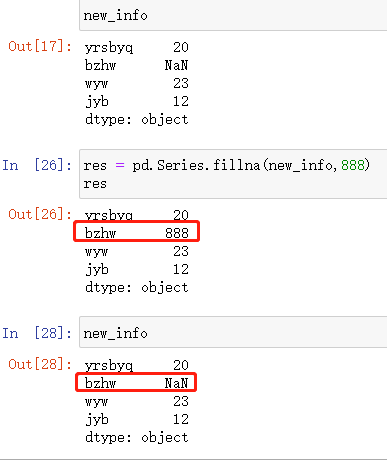
如果执行操作之后没有结果说明原数据改变
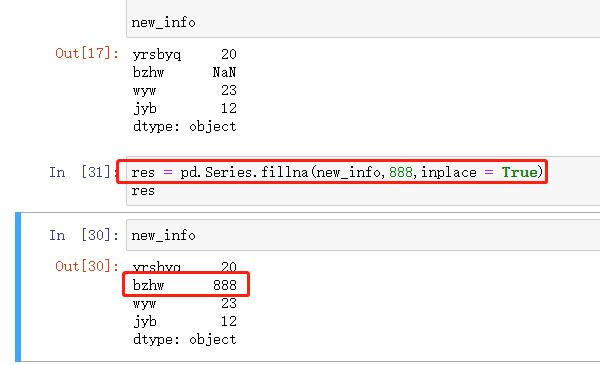
inplace = True,意思就是直接改变原数据
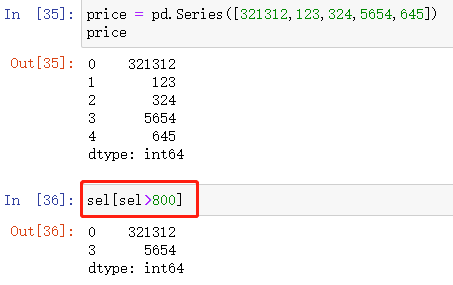
布尔值索引
本质是按照对应关系筛选出True对应的数据
逻辑索引
mask = pd.Series([True,False,False,True,False]) price = pd.Series([321312,123,324,5654,645]) price[mask] price|mask (price>200) & (price<900) price[(price>200) & (price<900)]
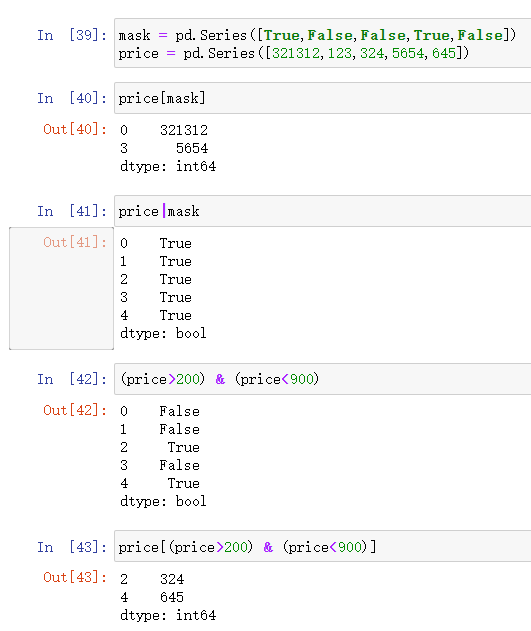
PS:针对&符号链接的条件都必须要加括号
行索引/行标签
既可以用行索引也可以使用行标签取值
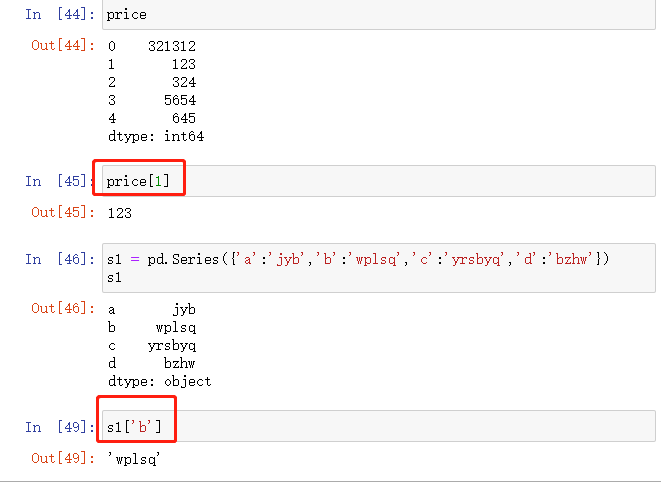
以索引下标解释
res.iloc[1]
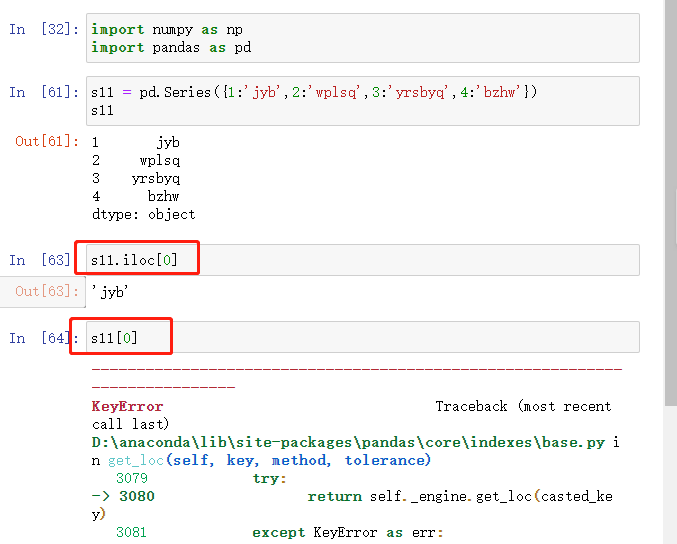
以行标签取值
res.loc['a']