

爬虫框架Scrapy和数据库MongoDB
爬虫框架之Scrapy
框架
别人提前搭建好的基本架构,具备了一定的功能。
Scrapy是网络爬虫中使用频率最高、功能最为完善的框架。

下载scrapy框架
pip3 install scrapy -i https://pypi.tuna.tsinghua.edu.cn/simple/
mac本一般直接下载即可,windows电脑可能会出错。
windows电脑如果下载报错并且没有典型的关键字特征那么需要做额外配置
pip3 install wheel
https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted

文件的存放位置
pip3 install 文件名
通过报错信息查看存放位置
pip3 install pywin32
pip3 install scrapy

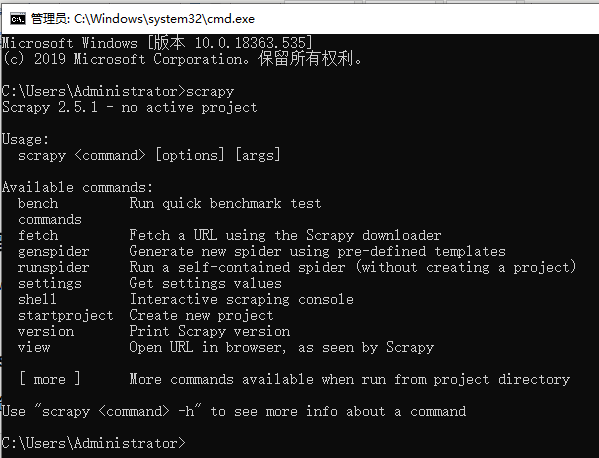
验证scrapy是否下载成功
windows命令行cmd终端内输入scrapy即可
scrapy基本使用
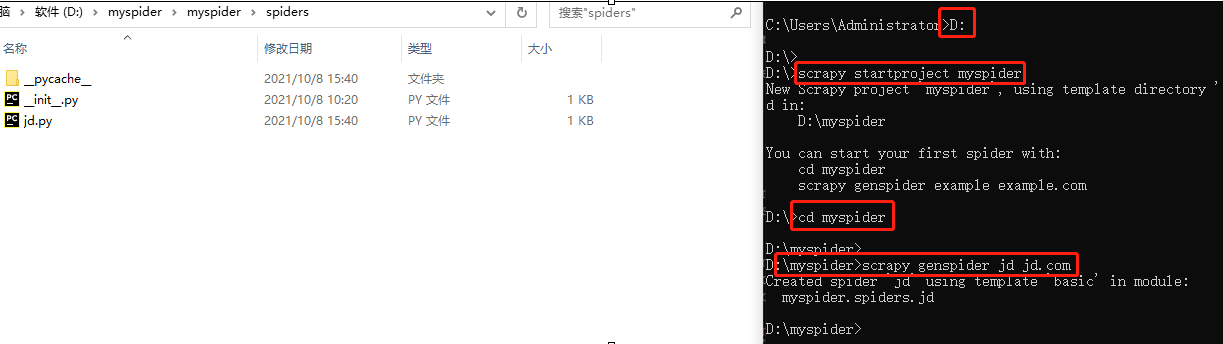
创建项目
scrapy startproject 项目名
自动生成一个内部含有多个py文件及文件夹的文件夹
创建爬虫文件
scrapy genspider jd www.jd.com
自动创建py文件并填写一定的代码,方便统一管理
执行爬虫文件
scrapy runspider jd.com scrapy crawl jd
Scrapy文件介绍
项目名文件夹
项目名同名的文件夹
spiders文件
存放爬虫项目文件
settings.py # 配置文件
"""ROBOTS.TXT爬虫协议"""
items.py # 数据存储相关的文件
middlewares.py # 中间件文件
'''在一个完整的操作流程中可以穿插多个小的操作步骤'''
pipelines.py # 数据存储相关的文件
MongoDB数据库
数据库的分类
关系型数据库
MySQL、Oracle、PostgreSQL、MariaDB、sql server、sqlite
特点:具有固定的表结构,并且可以建立外键关系

非关系型数据库
redis、mongodb、memcache
特点:没有固定的表结构,数据的存储采用的是k:v键值对形式
非关系数据库之MongoDB
该数据库存储数据的量和处理时间较于关系型数据库快很多
该数据库也是大数据生态圈里面常用的一款软件
该数据库是一款最像关系型数据库的非关系型数据库(文本结构)

纵向扩展与横向扩展
以提升计算机性能为例
横向扩展
买来多台计算机组合使用(常用于企业)
纵向扩展
就在一台计算机上面不停的优化(个人)
MongoDB重要概念
为了理解和学习的方便,可以使用MySQL的名词来称呼
database database 库 table collection 集合 row document 文档 column field 字段
MongoDB的下载与安装
下载地址:https://www.mongodb.com/try/download/community
下载msi文件即可
bin文件夹
里面存放一堆启动文件
mongod.exe 服务端 mongo.exe 客户端
data文件夹
里面存放数据相关文件
log文件夹
里面存放日志相关文件
启动步骤
1.双击msi文件安装
2.mongodb文件介绍
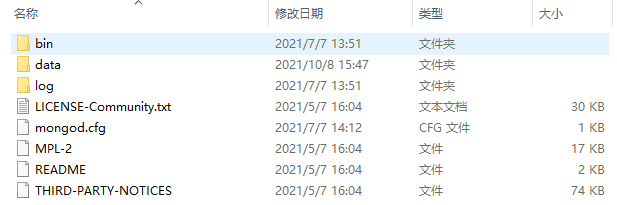
bin文件夹
所有的启动程序一般都是放在该文件夹内
data文件夹
存储数据
log文件夹
存储日志(操作记录)
3.查看mongodb文件夹内是否含有data和log文件夹
如果没有需要你自己手动创建
如果有则直接跳过
4.在data文件内创建db文件夹(目的是为了管理文件资源)
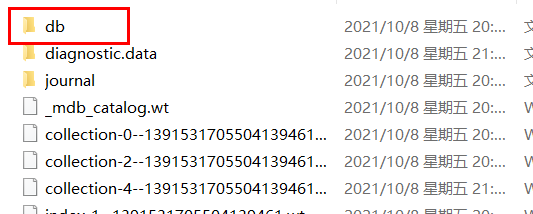
5.将启动文件所在的路径添加到环境变量中

6.在MongoDB文件夹根目录下
创建mongod.cfg文件
在该文件内拷贝以下代码
systemLog: destination: file path: "D:\MongoDB\log\mongod.log" logAppend: true storage: journal: enabled: true dbPath: "D:\MongoDB\data\db" net: bindIp: 0.0.0.0 port: 27017 setParameter: enableLocalhostAuthBypass: false
7.系统服务制作
mongod --bind_ip 0.0.0.0 --port 27017 --logpath D:\MongoDB\log\mongod.log --logappend --dbpath D:\MongoDB\data\db --serviceName"MongoDB" --serviceDisplayName "MongoDB" --install --auth
auth即让服务端以校验用户身份的方式启动 不加则不校验
8.启动\关闭
net start MongoDB
net stop MongoDB
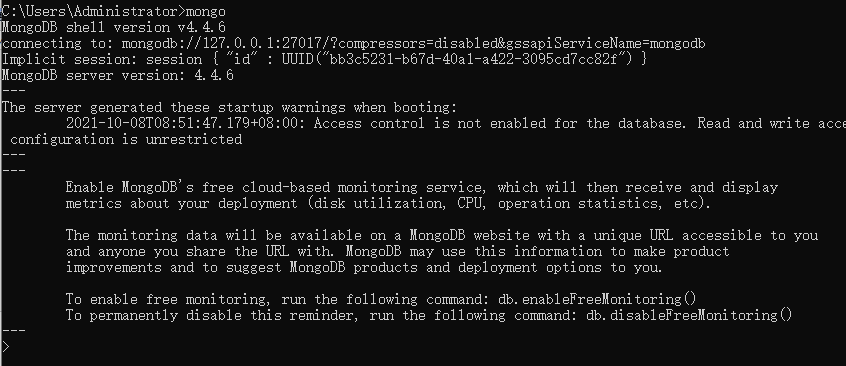
9.登录
在cmd中输入mongo
基础命令
mongodb语句不需要使用分号结束
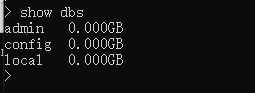
1.查看所有的数据库名词
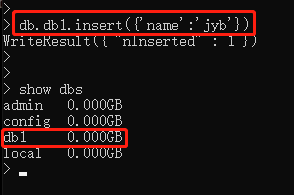
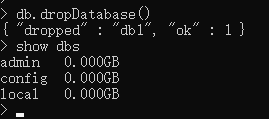
show dbs # show databases; # ongodb默认三个数据库:admin config local
2.退出客户端
exit # exit(); quit() # quit();
补充
MongoDB的特性在于无需可以创建东西,指定即可使用,但是只有在真正用到了该东西之后才会保存到硬盘,在此之前都是在内存中临时创建。
针对库的增删改查
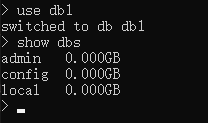
# 查看
show dbs
"""show databases;"""
# 新增
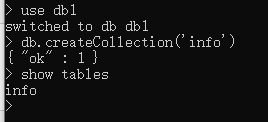
use db1 # 先在内存中自动创建 如果db1内写入了数据那么才会刷到硬盘中
"""create database db1;"""
# 修改
忽略
# 删除
先插入数据 db.db1.insert({'name':'jason'})
db.dropDatabase() # db是关键字 当前在哪个库下执行改命令就是删除哪个库
"""drop database db1;"""
针对集合(表)的增删改查
# 相当于MySQL中的表的概念
要想操作collection必须先有database
# 增
db.createCollection('表名')
db.collection名字 # 如果单纯的创建不插入数据 那么也只是在内存临时创建
# 查
show tables
show collections
# 改
忽略
# 删
db.collection名字.drop()
针对文档(记录)的增删改查
# 增
db.t1.insert({}) # 单条数据
insert也可以插入多条 db.t1.insert([{},{},{}])
db.t1.insertMany([{},{},{}]) # 多条数据
# 查
db.t1.find() # select * from t1;
db.t1.find({'name':'jason'})# select * from t1 where name='jason';
# 改
db.t1.update({'name':'jason'},{$set:{'name':'jasonNB'}}) # 修改
db.t1.update({'name':'jasonNB'},{'name':'jason666'}) # 替换(少用)
# 删
db.t1.remove({}) # delete from t1;
db.t1.remove({'name':'jason'})# delete from t1 where name='jason';



