

爬取实例和selenium模块
爬取城市名称
热门城市名称
hot_city_names = tree.xpath('//div[@class="hot"]/div[2]/ul/li/a/text()')
一般城市名称
other_city_names = tree.xpath('//div[@class="all"]/div[2]/ul/div[2]/li/a/text()')

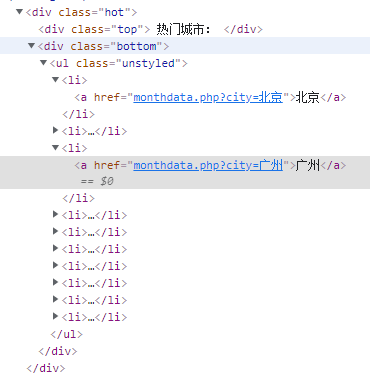
所有城市名称
all_city_names = tree.xpath(
'//div[@class="hot"]/div[2]/ul/li/a/text() | //div[@class="all"]/div[2]/ul/div[2]/li/a/text()')
代码
import requests
from lxml import etree
res = requests.get("https://www.aqistudy.cn/historydata/",
headers={
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36"
}
)
tree = etree.HTML(res.text)
hot_city_names = tree.xpath('//div[@class="hot"]/div[2]/ul/li/a/text()')
other_city_names = tree.xpath('//div[@class="all"]/div[2]/ul/div[2]/li/a/text()')
all_city_names = tree.xpath(
'//div[@class="hot"]/div[2]/ul/li/a/text() | //div[@class="all"]/div[2]/ul/div[2]/li/a/text()')
print(all_city_names)

爬取猪八戒数据
所有含有数据的div
div_list = tree.xpath('//div[@class="new-service-wrap"]/div')
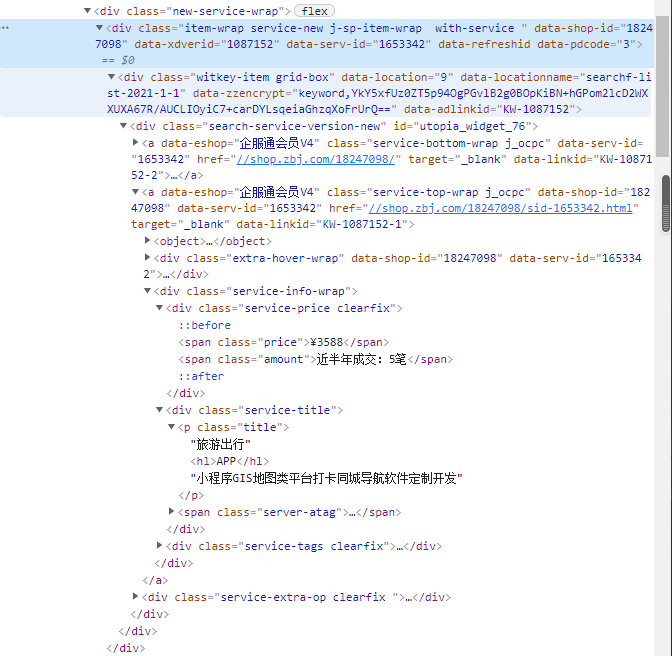
公司名称
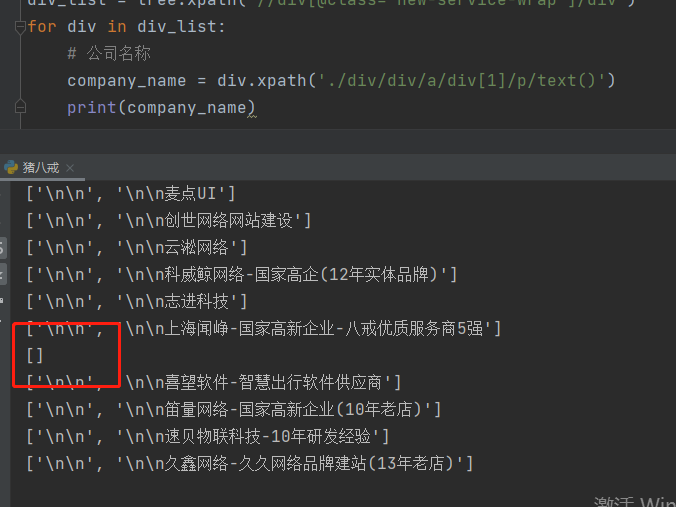
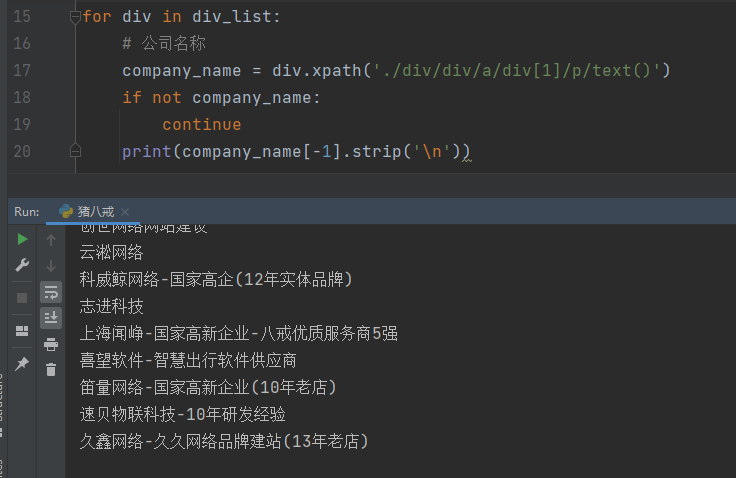
因为有空数据,所以要进行判断
if not company_name:
continue
订单价格
order_price = div.xpath('./div/div/a[2]/div[2]/div[1]/span[1]/text()')
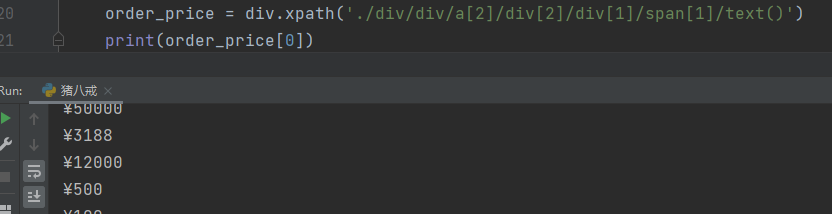
历史成交
order_num = div.xpath('./div/div/a[2]/div[2]/div[1]/span[2]/text()')
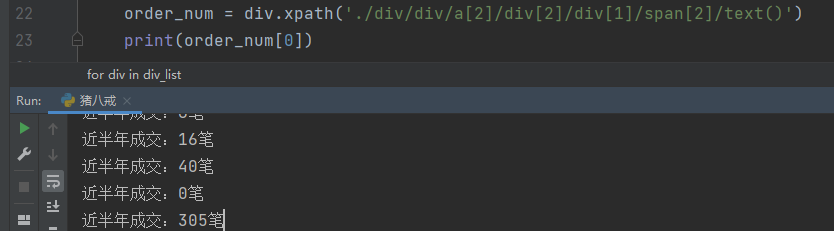
订单描述
order_desc = div.xpath('./div/div/a[2]/div[2]/div[2]/p/text()')
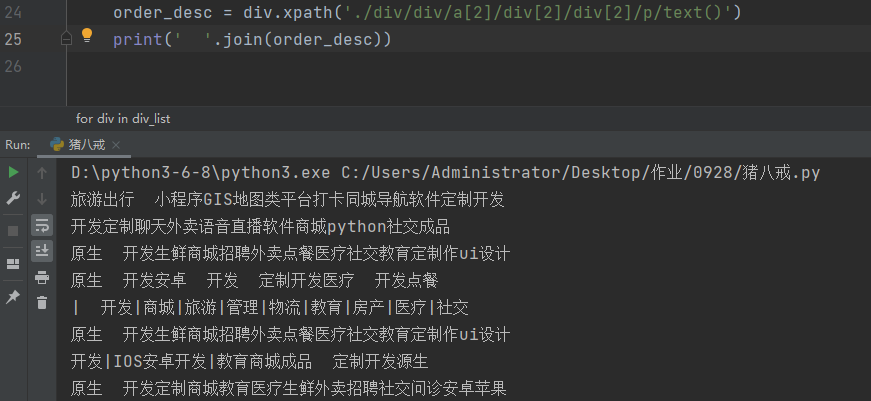
代码
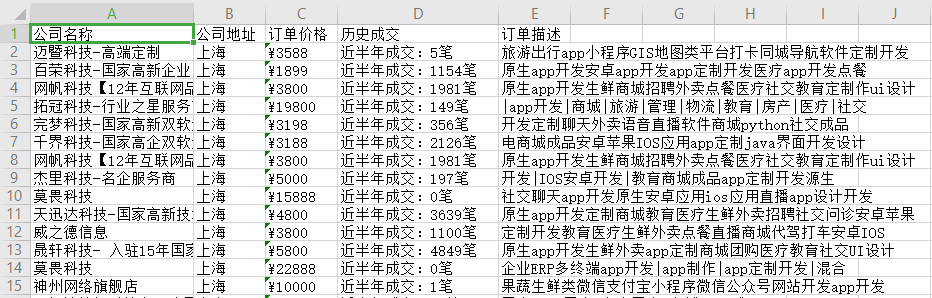
# 需求:公司名称 地址 价格 成交量 描述信息
import requests
from lxml import etree
from openpyxl import Workbook
wb = Workbook()
wb1 = wb.create_sheet('订单数据', 0)
wb1.append(['公司名称', '公司地址', '订单价格', '历史成交', '订单描述'])
# 1.发送请求获取页面数据
res = requests.get('https://shanghai.zbj.com/search/f/',
params={'kw': 'app'}
)
# 2.生成xpath对象
tree = etree.HTML(res.text)
# 3.研究标签规律 书写xpath
# 直接查找
'''直接查找很多时候是无法使用的 因为会出现数据混乱的现象'''
# company_name = tree.xpath('//div[@class="new-service-wrap"]/div/div/div/a/div[1]/p/text()')
# print(company_name)
# 先查找所有含有数据的div 之后依次循环
div_list = tree.xpath('//div[@class="new-service-wrap"]/div')
for div in div_list:
# 公司名称
company_name = div.xpath('./div/div/a/div[1]/p/text()')
# 如果获取不到公司名称 在该网站上是广告位
if not company_name:
continue
# print(company_name[-1].strip('\n'))
# 公司地址
address_info = div.xpath('./div/div/a/div[1]/div/span/text()')
# print(address_info[0])
# 订单价格
order_price = div.xpath('./div/div/a[2]/div[2]/div[1]/span[1]/text()')
# print(order_price[0])
# 历史成交
order_num = div.xpath('./div/div/a[2]/div[2]/div[1]/span[2]/text()')
# print(order_num[0])
# 订单描述
order_desc = div.xpath('./div/div/a[2]/div[2]/div[2]/p/text()')
# print('app'.join(order_desc))
wb1.append([company_name[-1].strip('\n'), address_info[0], order_price[0], order_num[0], 'app'.join(order_desc)])
wb.save(r'订单数据.xlsx')
# 扩展:针对多页数据此处使用后续模块会更加方便
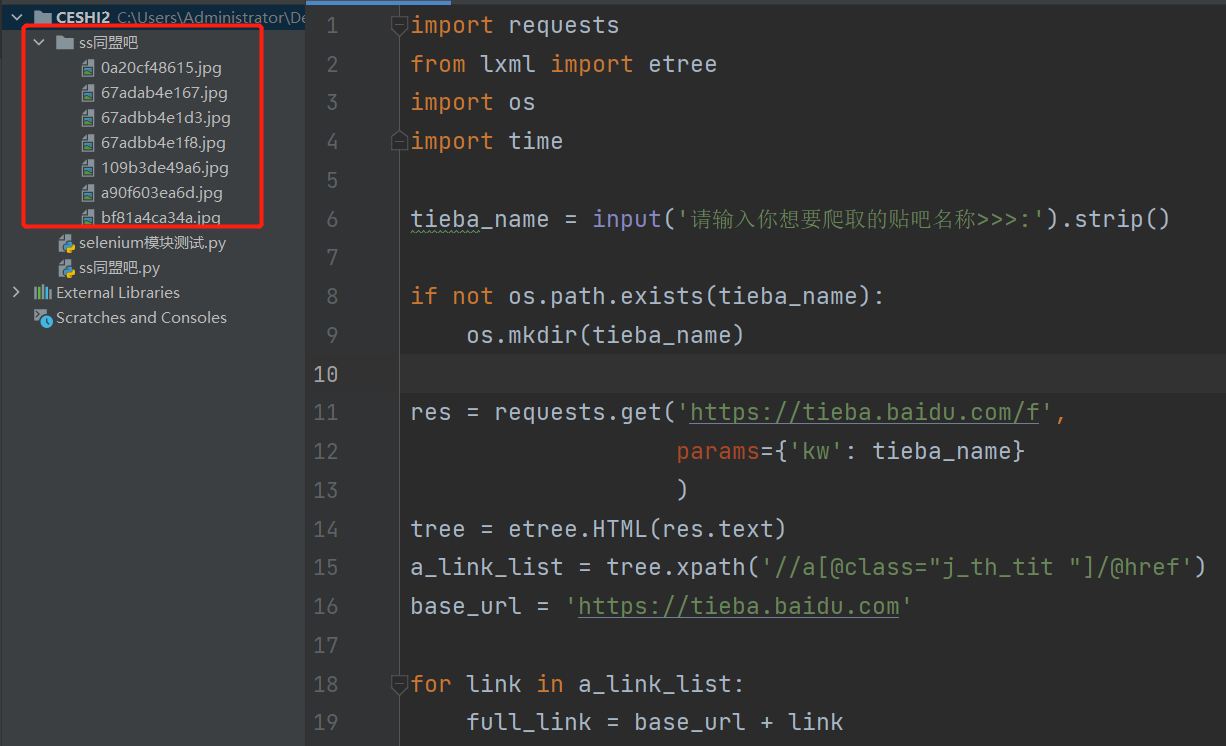
爬取贴吧图片数据
注意:尽量停顿时间多一点,1秒是不够的,建议三秒,否则会有验证码要求。
代码
import requests
from lxml import etree
import os
import time
# 获取用户想要爬取的贴吧名称
tieba_name = input('请输入你想要爬取的贴吧名称>>>:').strip()
# 判断当前贴吧名称是否存在对应的文件夹
if not os.path.exists(tieba_name):
os.mkdir(tieba_name)
# 1.发送请求
# TODO:多页数据 只需要再加一个pn参数即可
res = requests.get('https://tieba.baidu.com/f',
params={'kw': tieba_name}
)
# 2.生成一个xpath对象
tree = etree.HTML(res.text)
# 3.查找所有帖子的链接地址
a_link_list = tree.xpath('//a[@class="j_th_tit "]/@href')
base_url = 'https://tieba.baidu.com'
# 4.循环获取每一个帖子链接 拼接成完整的地址 再发送请求
for link in a_link_list:
full_link = base_url + link
print(full_link)
# 5.发送详情页请求获取页面数据
res1 = requests.get(full_link)
tree1 = etree.HTML(res1.text)
# 6.筛选图片链接地址
img_src_list = tree1.xpath('//img[@class="BDE_Image"]/@src')
# 7.循环请求每个图片地址 并保存图片
for img_src in img_src_list:
res2 = requests.get(img_src)
file_path = os.path.join(tieba_name, img_src[-15:])
with open(file_path, 'wb') as f:
f.write(res2.content)
time.sleep(3)
selenium模块
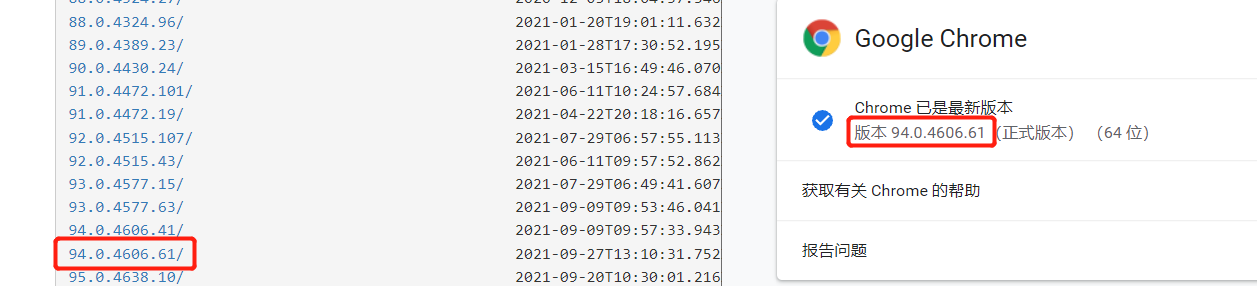
驱动下载
该模块是用来操作浏览器的,需要相应的驱动软件(必备)。
下载地址:https://npm.taobao.org/mirrors/chromedriver,需要根据自己的chrome版本下载对应版本。
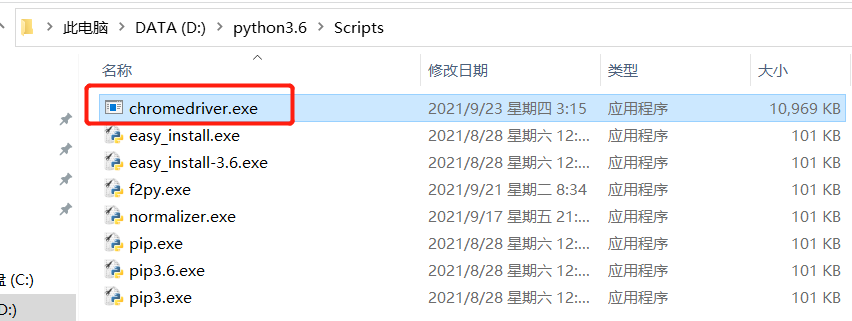
存放路径
下载好的文件解压到python解释器的scripts目录下,该路径需要配置到环境变量中。
验证
from selenium import webdriver
import time
# 指定操作的浏览器驱动
bro = webdriver.Chrome()
# 控制浏览器访问网站数据
bro.get("http://www.baidu.com")
# 关闭浏览器窗口
time.sleep(3)
bro.close()

基本操作
# 1、find_element_by_id 根据id找
# div_tag = bro.find_element_by_id('s-top-left')
# 2、find_element_by_link_text 根据链接名字找到控件(a标签的文字)
# a_tag = bro.find_element_by_link_text("新闻")
# 3、find_element_by_partial_link_text 根据链接名字找到控件(a标签的文字)模糊查询
# 4、find_element_by_tag_name 根据标签名
# 5、find_element_by_class_name 根据类名
# 6、find_element_by_name 根据属性名
# 7、find_element_by_css_selector 根据css选择器
# 8、find_element_by_xpath 根据xpath选择
find_element与find_elements的区别就在于前者只会找到符合条件的第一个,后者是所有。
两者的关系相当于bs4模块里面的find与find_all。

