xpath解析器
该选择器可以做到一句话完成多步操作,效率很高,使用广泛。
导入xpath所在的模块
from lxml import etree
将待匹配的文本传入etree生成一个对象
html = etree.HTML(doc)
xpath解析器主要功能
# 1 所有节点
a = html.xpath('//*') # 匹配所有的标签
# 2 指定节点(结果为列表)
a = html.xpath('//head') # 匹配所有的head标签
# 3 子节点,子孙节点
a = html.xpath('//div/a') # 匹配div标签内部所有的儿子a标签
a = html.xpath('//body/a') # 没有符合条件的儿子a
a = html.xpath('//body//a') # 匹配div标签内容所有的后代a标签
a = html.xpath('//body//a') # 也可以匹配到
# 4 父节点
a=html.xpath('//body//a[@href="image1.html"]') # 属性查找 获取body内部所有的href=image1.html后代a
a = html.xpath('//body//a[@href="image1.html"]/..') # ..表示查找上一级父标签
a = html.xpath('//title[@id="t1"]/..') # ..表示查找上一级父标签
a = html.xpath('//body//a[1]') # 从1开始取值
'''xpath选择器中中括号内部可以放属性也可以放位置数 从1开始'''
# 5 文本获取
a = html.xpath('//body//a[@href="image1.html"]/text()')
a = html.xpath('//body//a/text()') # 获取body内部所有后代a内部文本(一次性获取不需要循环)
# 6 属性获取
a = html.xpath('//body//a/@href') # 获取body内部所有后代a标签href属性值(一次性获取不需要循环)
a = html.xpath('//title/@id') # 获取title标签id属性值
# # 注意从1 开始取(不是从0)
a = html.xpath('//body//a[2]/@href')
# 7 属性多值匹配
a 标签有多个class类,直接匹配就不可以了,需要用contains
a=html.xpath('//body//a[@class="li"]') # 写等号就表示等于 不是包含
a = html.xpath('//body//a[contains(@class,"li")]/text()') # 包含需要使用关键字contains
# 8 多属性匹配
# '''查找body标签内部所有class含有li或者name=items的a标签'''
a = html.xpath('//body//a[contains(@class,"li") or @name="items"]')
'''查找body标签内部所有class含有li并且name=items的a标签的内部文本'''
a = html.xpath('//body//a[contains(@class,"li") and @name="items"]/text()')
# 9 按序选择
# 取最后一个
a = html.xpath('//a[last()]/@href')
# 位置小于3的
a = html.xpath('//a[position()<3]/@href') # position()关键字 用于定位
# 倒数第三个
a = html.xpath('//a[last()-2]/@href')
了解
# 10 节点轴选择
# ancestor:祖先节点
# 使用了* 获取所有祖先节点
a = html.xpath('//a/ancestor::*')
# # 获取祖先节点中的div
a = html.xpath('//a/ancestor::div')
# attribute:属性值
a = html.xpath('//a[1]/attribute::*') # 查找a标签内部所有的属性值
# child:直接子节点
a = html.xpath('//a[1]/child::*')
# descendant:所有子孙节点
a = html.xpath('//a[6]/descendant::*')
# following:当前节点之后所有节点
a = html.xpath('//a[1]/following::*')
a = html.xpath('//a[1]/following::*[1]/@href')
# following-sibling:当前节点之后同级节点
a = html.xpath('//a[1]/following-sibling::*')
a = html.xpath('//a[1]/following-sibling::a')
a = html.xpath('//a[1]/following-sibling::*[2]/text()')
a = html.xpath('//a[1]/following-sibling::*[2]/@href')
print(a)
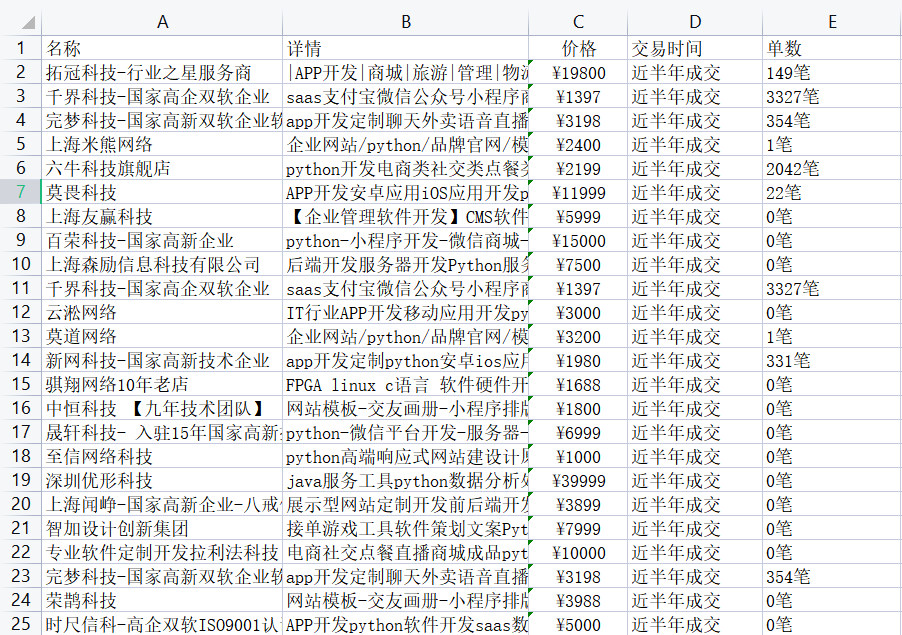
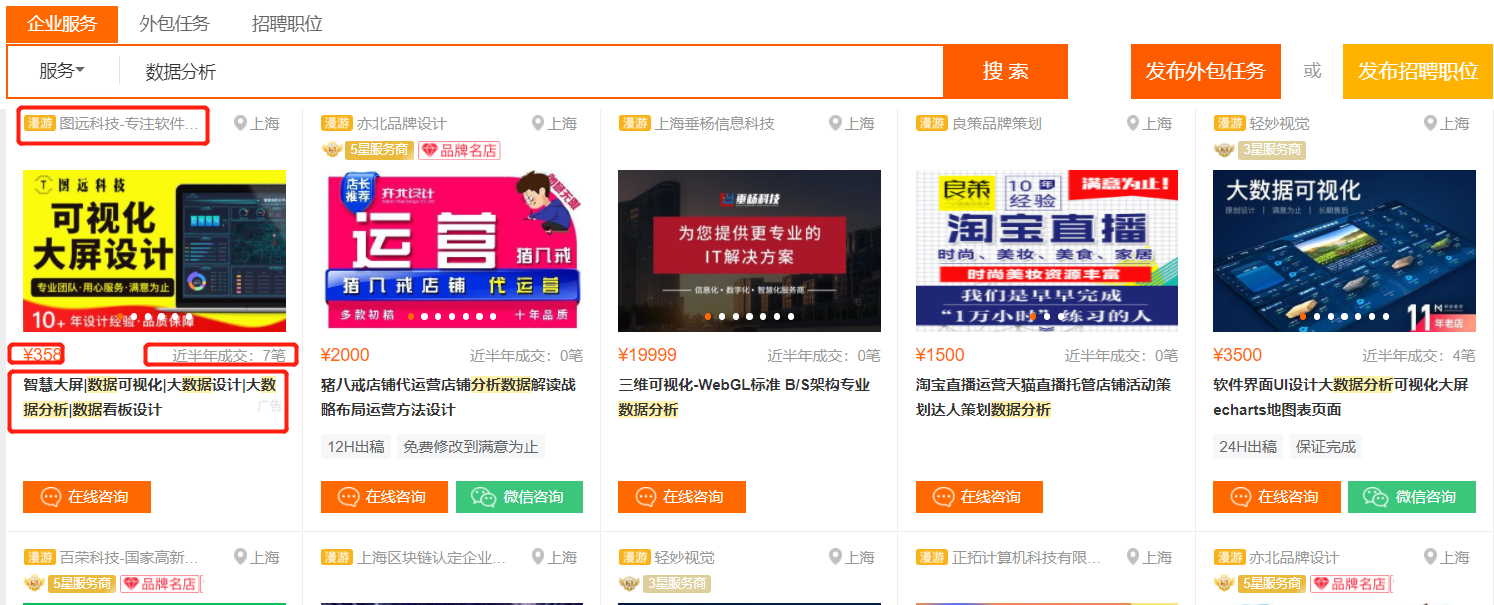
xpath爬取猪八戒数据
代码
import requests
from bs4 import BeautifulSoup
from lxml import etree
res = requests.get('https://shanghai.zbj.com/search/f/',
params={'kw': 'python'}
)
x_html = etree.HTML(res.text)
# 分析标签特征并书写xpath语法筛选
# 1.先查找所有的外部div标签
div_list = x_html.xpath('/html/body/div[6]/div/div/div[2]/div[5]/div[1]/div') # 利用浏览器自动生成
# div_list = x_html.xpath('//div[@class="new-service-wrap"]/div') # 自己写
# 2.循环获取每一个div标签
for div in div_list:
//*[@id="utopia_widget_4"]/div[8]/div/div[4]/div[1]/div[1]/div/div[2]/div[4]/div[1]
price = div.xpath('.//span[@class="price"]/text()')
company_name = div.xpath('./div/div/a[1]/div[1]/p/text()')
order_num = div.xpath('./div/div/a[2]/div[2]/div[1]/span[2]/text()')
info = div.xpath('./div/div/a[2]/div[2]/div[2]/p/text()')
print(info)