数据加载方式与实例操作
数据的加载方式
常见的加载方式
朝服务器发送请求,页面数据直接全部返回并加载。
如何验证数据是直接加载还是其他方式
浏览器空白处鼠标右键,点击查看网页源码,在源码界面搜索对应的数据。
如果能收到就表示该数据是直接加载的,可以直接发送相应的请求获取。
内部js代码请求
先加载一个页面的框架,之后再朝各项数据的网址发送请求获取数据。
如何查找关键性的数据来源
需要借助于浏览器的network监测核对内部请求
请求的数据一般都是json格式
实例
爬取天气数据
思路
1.拿到页面之后先分析数据加载方式
2.发现历史数据并不是直接加载的
统一的研究方向>>>:利用network查看
3.查找到可疑的网址并查看请求方式
如果是get请求那么可以直接拷贝网址在浏览器地址栏访问
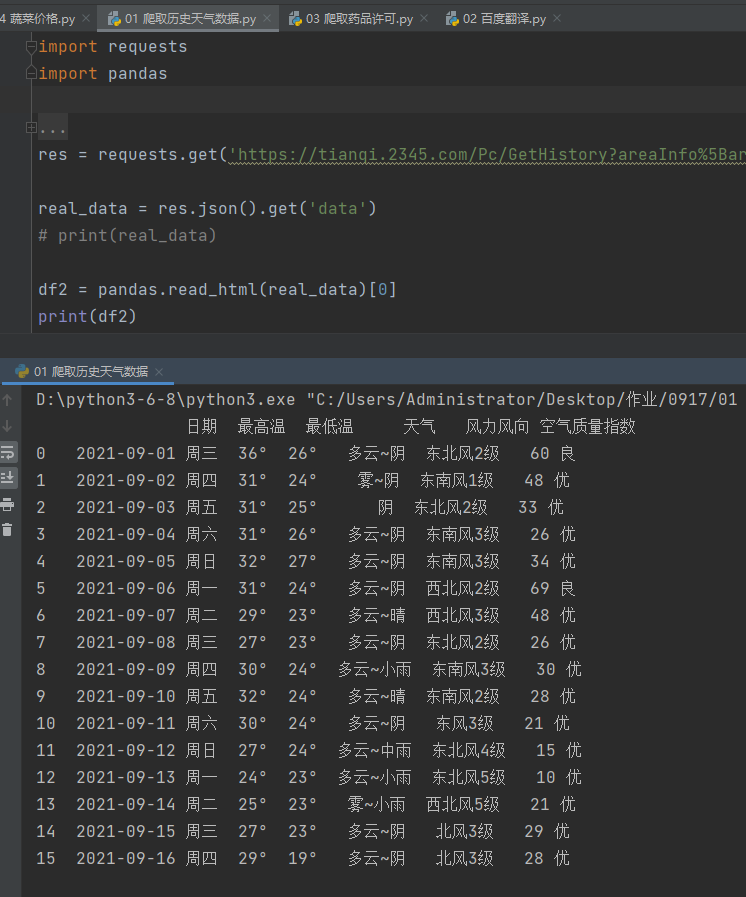
4.将请求获得的数据稍作分析
https://www.bejson.com/
5.利用requests模块朝发现的地址发送get请求获取json数据
6.可以研究历史天气数据的url找规律 即可爬取指定月份的数据
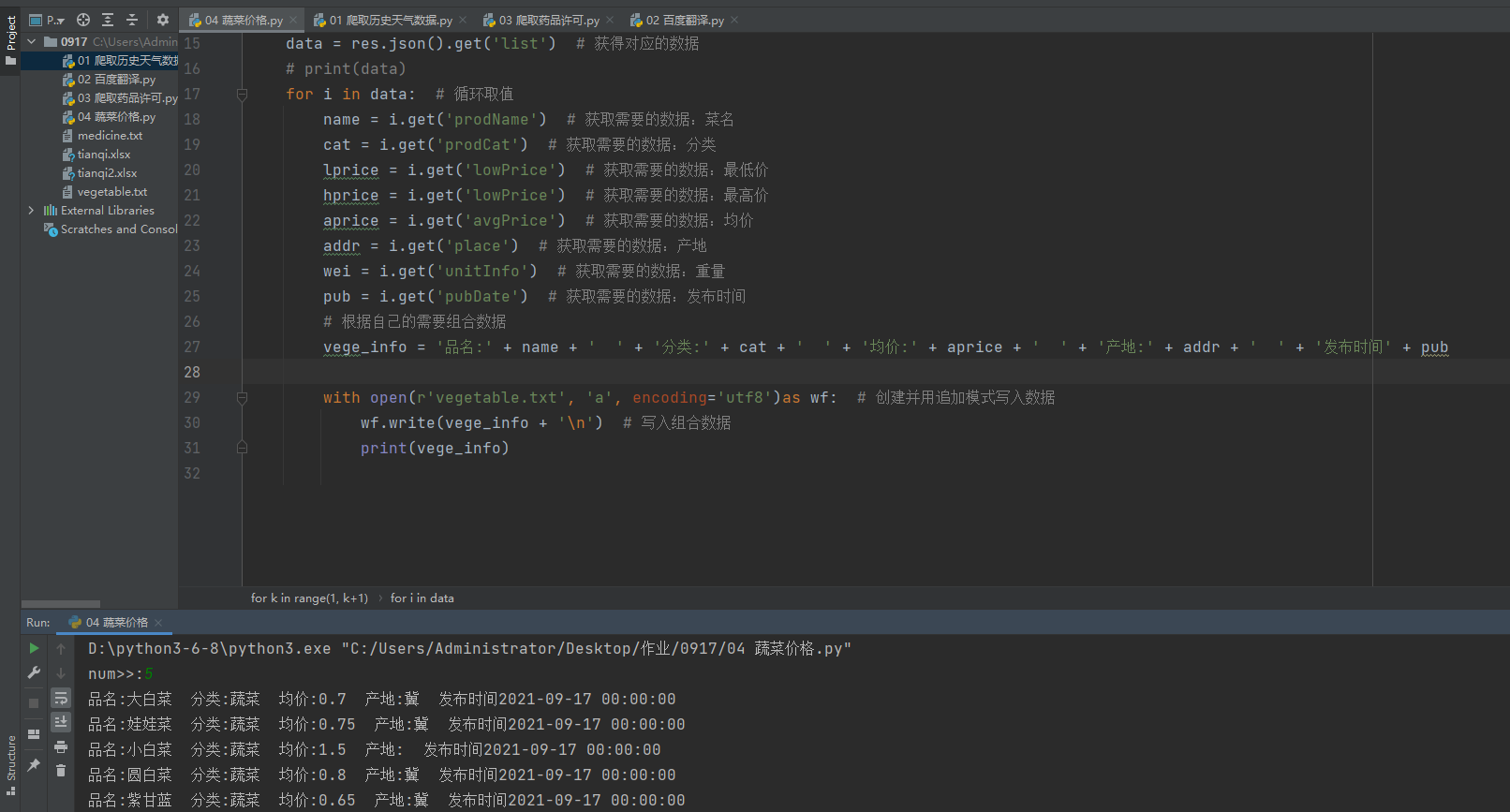
import requests
import pandas
res = requests.get('https://tianqi.2345.com/Pc/GetHistory?areaInfo%5BareaId%5D=60010&areaInfo%5BareaType%5D=2&date%5Byear%5D=2021&date%5Bmonth%5D=9')
real_data = res.json().get('data')
df2 = pandas.read_html(real_data)[0]
print(df2)
百度翻译
思路
1.在查找单词的时候页面是在动态变化的
2.并且针对单词的详细翻译结果数据是动态请求获取的
3.打开network之后输入英文查看内部请求变化
sug请求频率固定且较高
4.研究sug请求发现每次输入的单词都会朝固定的一个网址发送post请求
并且请求体携带了改单词数据

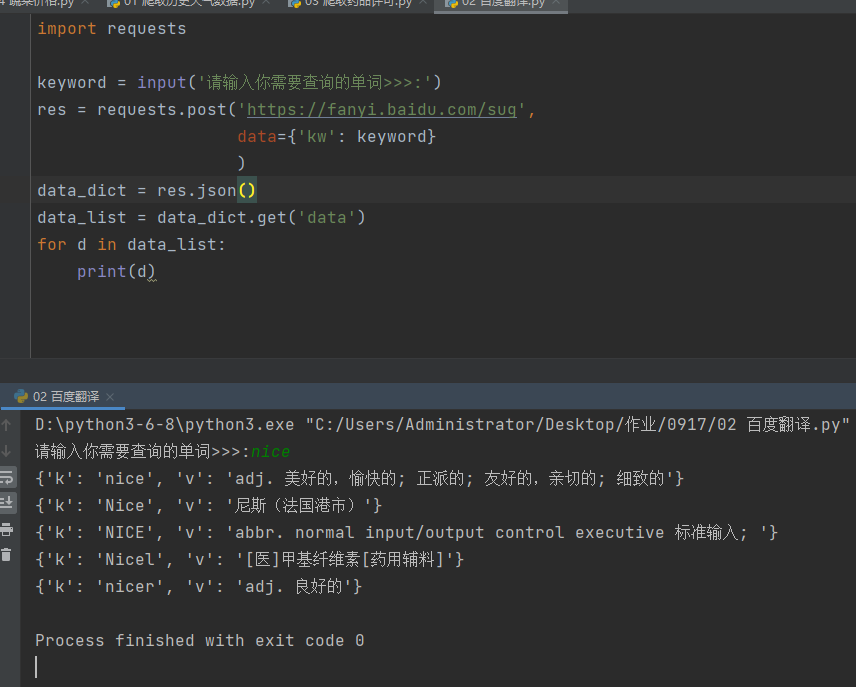
import requests
keyword = input('请输入你需要查询的单词>>>:')
res = requests.post('https://fanyi.baidu.com/sug',
data={'kw': keyword}
)
data_dict = res.json()
data_list = data_dict.get('data')
for d in data_list:
print(d)
爬取药品许可证
思路
1.先明确是否需要爬取页面数据 如果需要则先查看数据的加载方式
2.通过network查看得知数据是动态加载的 网页地址只会加载一个外壳
3.通过network点击fetch/xhr筛选动态获取数据的地址和请求方式
4.利用requests模块发送相应请求获取数据 之后再分析
5.利用浏览器点击详情页查找关键数据
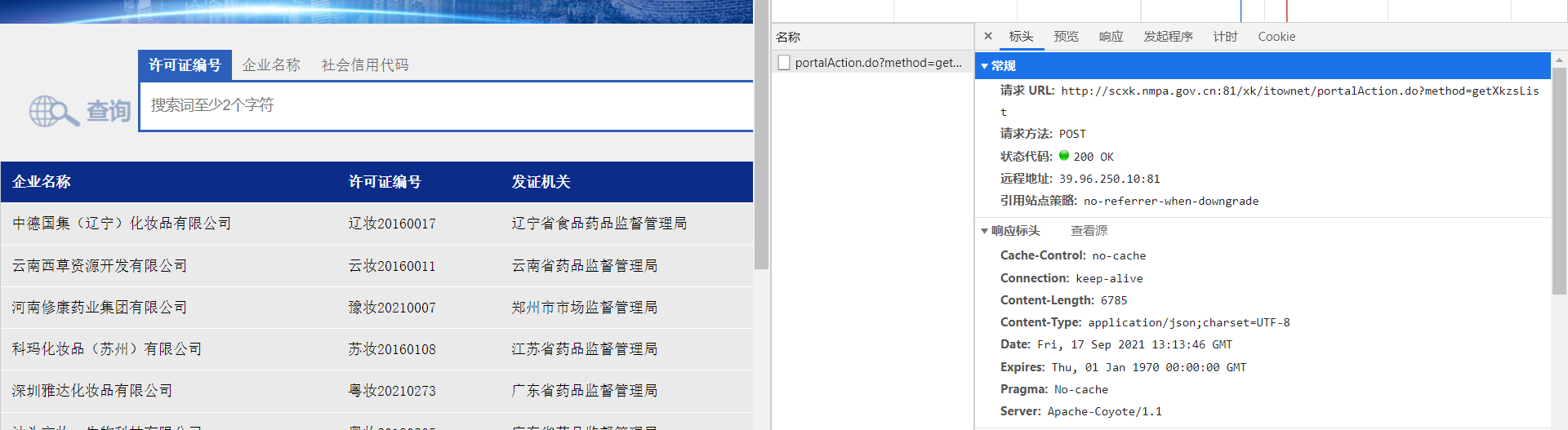
http://scxk.nmpa.gov.cn:81/xk/itownet/portal/dzpz.jsp?id=911d4f256300476abb78012427d38c9d
6.由于我们需要爬取详情页的数据所以要验证数据的加载方式
7.详情页核心数据也是动态加载的 发现是post请求并携带了一个id参数
id: 911d4f256300476abb78012427d38c9d
8.通过比对得知id数据与第一次爬取的公司简介里面的id一致 从而得出结论
循环获取格式简介id 然后发送post请求 获取每个公司的详细数据

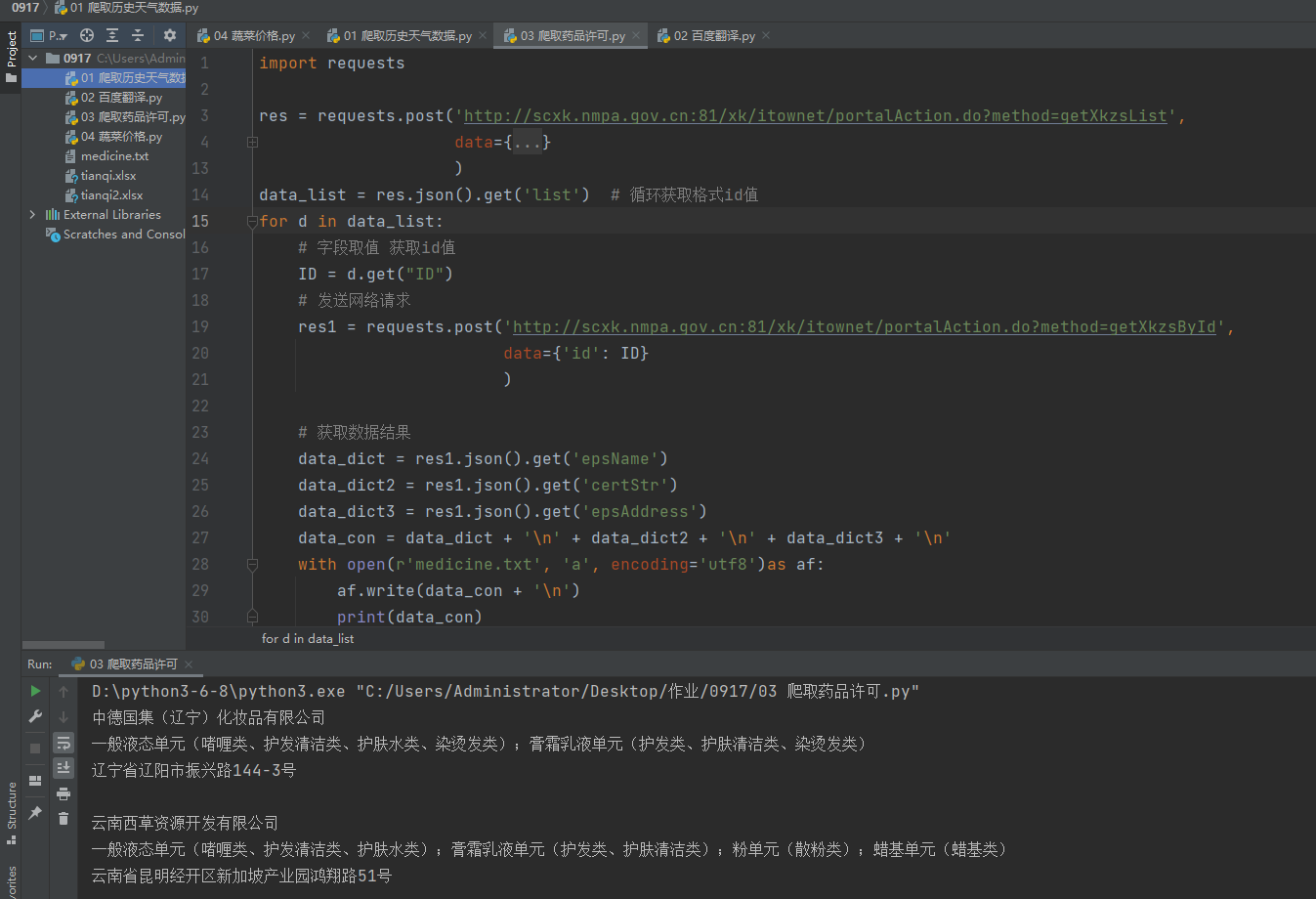
import requests
res = requests.post('http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList',
data={
"on": "true",
"page": 1,
"pageSize": 15,
"productName": '',
"conditionType": 1,
"applyname": '',
"applysn": ''
}
)
data_list = res.json().get('list') # 循环获取格式id值
for d in data_list:
# 字段取值 获取id值
ID = d.get("ID")
# 发送网络请求
res1 = requests.post('http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById',
data={'id': ID}
)
# 获取数据结果
data_dict = res1.json().get('epsName')
data_dict2 = res1.json().get('certStr')
data_dict3 = res1.json().get('epsAddress')
data_con = data_dict + '\n' + data_dict2 + '\n' + data_dict3 + '\n'
with open(r'medicine.txt', 'a', encoding='utf8')as af:
af.write(data_con + '\n')
爬取北京新发地蔬菜价格表
思路:
1.确定需要访问网址:http://www.xinfadi.com.cn/priceDetail.html
2.右键选择‘查看网页源代码’,ctrl+f搜索,观察数据是否是直接放在网页中的
本次数据并未放在网页中
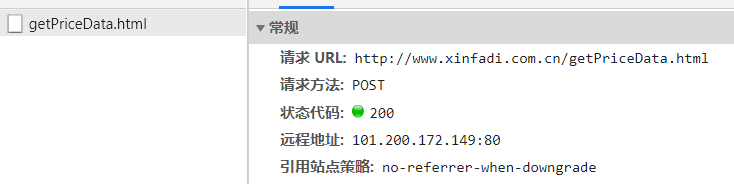
3.右键选择‘检查’,根据network,可以确认数据是动态加载的,选择Fetch/XHR,筛选出对应的文件
4.单击该文件,查看对应的是get还是post方法,以及对应的From Data数据
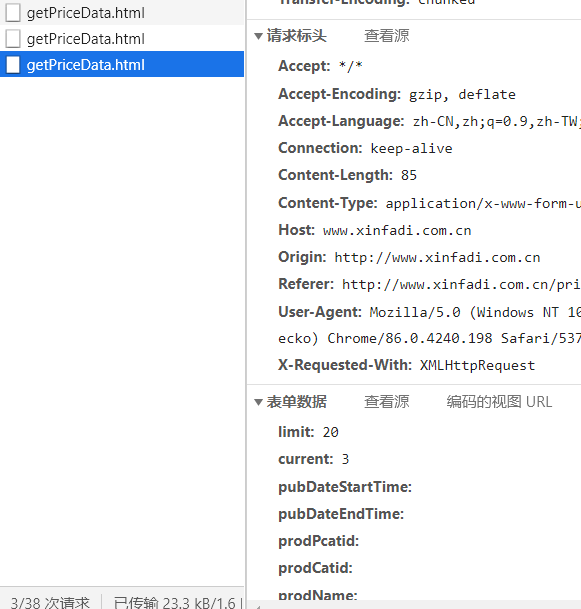
5.选择Response,将内容复制到:https://www.bejson.com/,点击Unicode转中文,查看数据存放的具体位置
本次数据存放在字典中,键名是“list”,数据格式是json格式
6.打开pycharm,新建文件夹及文件,导入requests模块
7.使用post-data方法,反序列化并使用get方法从字典中获取数据
8.循环取值,获得数据
9.根据自身的需要,用键名取得需要的值
10.将获取的数据写入文件
import requests
import time
def get_price_data(n):
res = requests.post('http://www.xinfadi.com.cn/getPriceData.html',
data={
"limit": '',
"current": n,
"pubDateStartTime": '',
"pubDateEndTime": '',
"prodPcatid": '',
"prodCatid": '',
"prodName": '',
}
)
data_list = res.json().get('list')
for d in data_list:
pro_name = d.get('prodName')
low_price = d.get('lowPrice')
high_price = d.get('highPrice')
avg_price = d.get('avgPrice')
pub_date = d.get('pubDate')
source_place = d.get('place')
print("""
蔬菜名称:%s
最低价:%s
最高价:%s
平均价:%s
上市时间:%s
原产地:%s
""" % (pro_name, low_price, high_price, avg_price, pub_date, source_place))
time.sleep(1)
"""涉及到多页数据爬取的时候 最好不要太频繁 可以自己主动设置延迟"""
for i in range(1, 5):
time.sleep(1)
get_price_data(i)