数据库查询之多表查询与navicat使用
单表查询补充
group_concat()
用于分组之后,获取除了分组之外的其他数据字段,本质可以理解为是拼接操作。
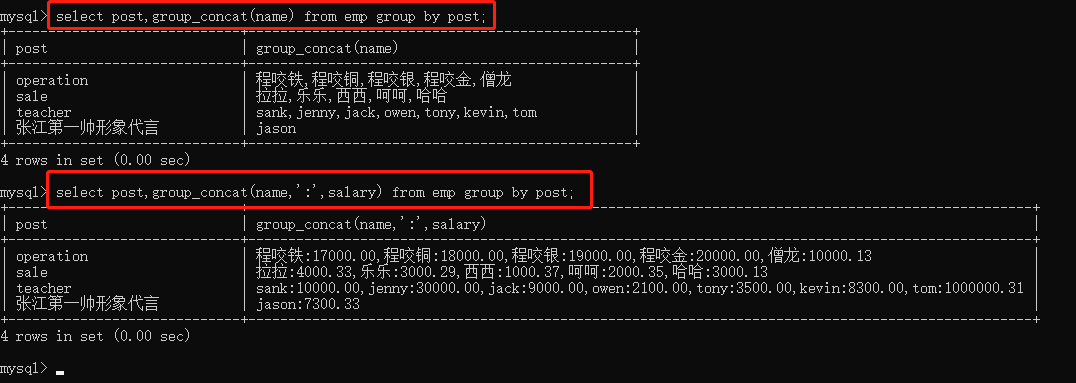
select post,group_concat(name) from emp group by post; select post,group_concat(name,':',salary) from emp group by post;
concat()方法
用于分组之前
select post,group_concat(name,':',salary) from emp group by post;

concat_ws()方法
用于分组之前,多个字符是相同的分隔符的情况
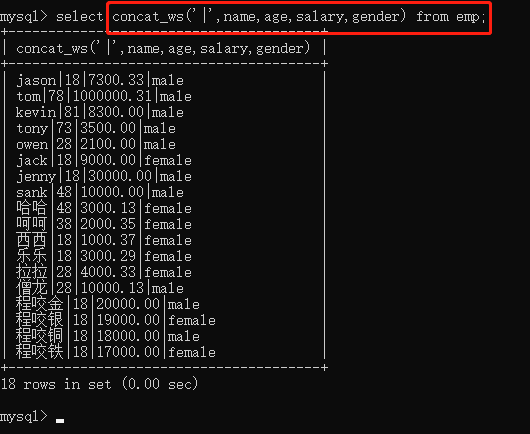
select concat_ws('|',name,age,salary,gender) from emp;
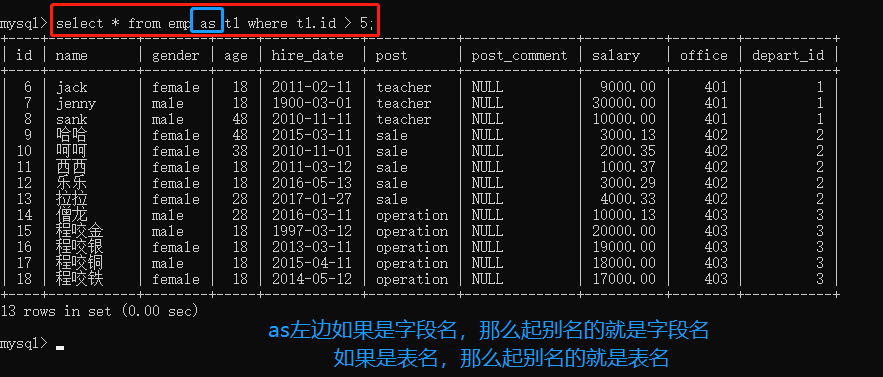
as语法
可以给查询出来的字段名起别名
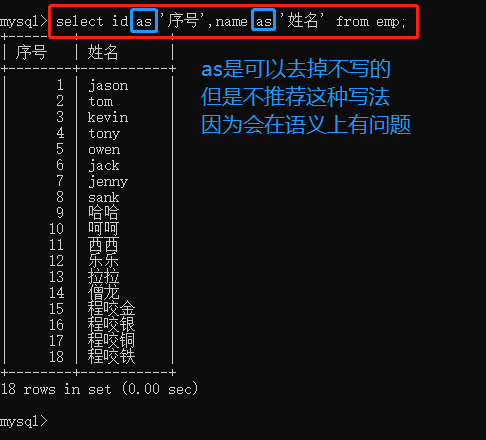
select id as '序号',name as '姓名' from emp;
可以给表名起别名
主要用在多表查询中
# 将emp表名起别名为t1 之后使用t1替代emp
select * from emp as t1 where t1.id > 5;
多表查询理论
多表查询
所需数据来源于多张表数据的组合。
数据准备
#建表 create table dep( id int primary key auto_increment, name varchar(20) ); create table emp( id int primary key auto_increment, name varchar(20), gender enum('male','female') not null default 'male', age int, dep_id int ); #插入数据 insert into dep values (200,'技术'), (201,'人力资源'), (202,'销售'), (203,'运营'); insert into emp(name,gender,age,dep_id) values ('jason','male',18,200), ('egon','female',48,201), ('kevin','male',18,201), ('nick','male',28,202), ('owen','male',18,203), ('jerry','female',18,204);
结论:
SQL语句查询出来的结果其实也可以看成是一张表,涉及到多表可能会出现字段名冲突需要在字段名前面加上表名做限制。
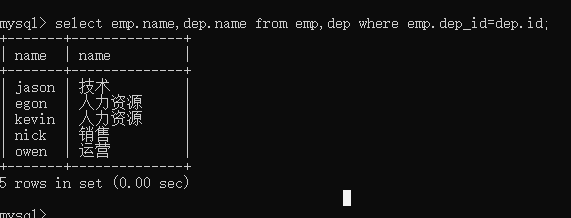
查询各员工姓名以及对应的部门名称
员工姓名在emp表,部门名称在dep表
# 推导过程1 select * from emp,dep; # 笛卡尔积 # 推导过程2 select * from emp,dep where emp.dep_id=dep.id; # 推导过程3 select emp.name,dep.name from emp,dep where emp.dep_id=dep.id;
多表查询之联表
联表
先将多张表拼接成一张大表,然后再基于单表查询完成。
MySQL拼接表的关键字
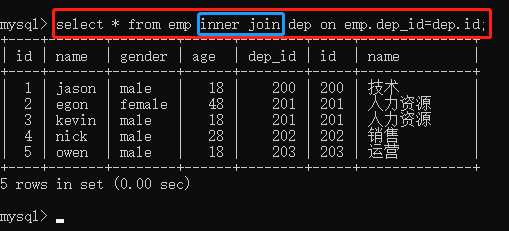
inner join 内链接
内链接只链接两张表中都具有对应数据的部分。
select * from emp inner join dep on emp.dep_id=dep.id;
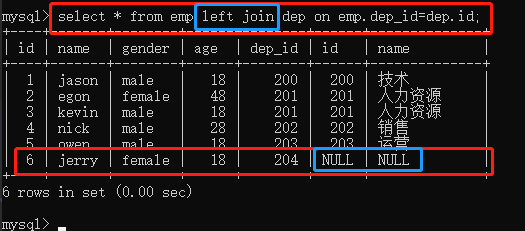
left join 左链接
以关键字左表为基础展示左表所有的数据,没有对应的数据用null填充。
select * from emp left join dep on emp.dep_id=dep.id;
right join 右链接
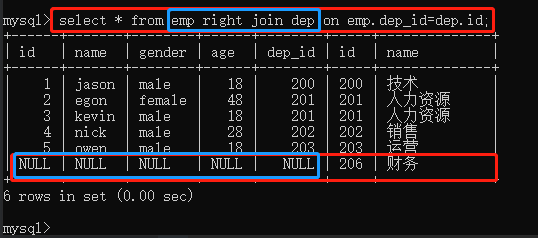
以关键字右表为基础展示右表所有的数据,没有对应的数据以null填充
select * from emp right join dep on emp.dep_id=dep.id;
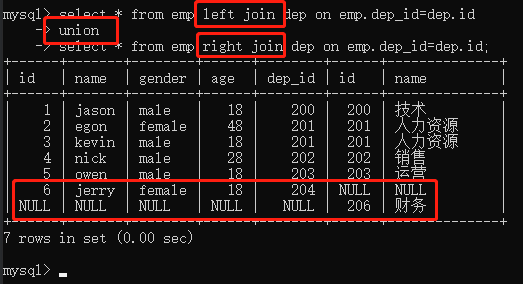
union 全链接
不管有没有对应数据,全部展示,其实就是把左链接和右链接用union连起来。
select * from emp left join dep on emp.dep_id=dep.id union select * from emp right join dep on emp.dep_id=dep.id;
多表查询之子查询
子查询
将一张表的查询结果用括号括起来当成另外一条SQL语句的条件。
子查询一般是分步操作,也即是日常生活中解决问题的思路。
查询部门是技术或者人力资源的员工信息
方法1:联表操作
select emp.name,emp.age,dep.name from emp inner join dep on emp.dep_id=dep.id where dep.name in ('技术','人力资源');

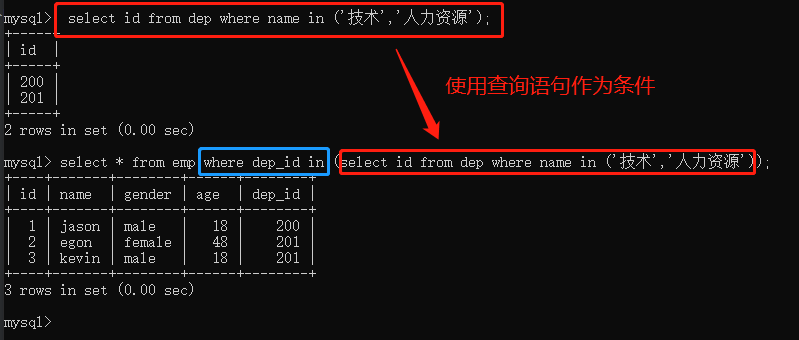
方法2:子查询
# 先查询技术和人力资源id号 select id from dep where name in ('技术','人力资源'); # 再去员工表里面根据部门id号筛选出员工数据 select * from emp where dep_id in (select id from dep where name in ('技术','人力资源'));
总结
涉及到多表查询只有两种方法:
1.联表操作
2.子查询
很多复杂的查询甚至需要两者的结合。
可视化软件之navicat
Navicat是一款可以操作多种数据库的软件,内部其实就是封装了相应的SQL语句。

下载安装
15版本参考地址:https://defcon.cn/214.html
旧版本(11版本)安装参考地址:http://www.ddooo.com/softdown/59996.htm
也可以免费使用14天,但是建议不要反复试用,否则可能失效。
基本使用
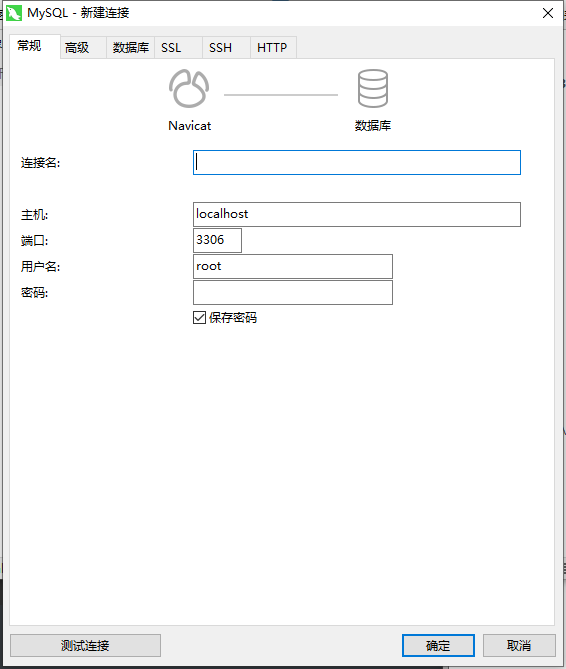
连接
点击左上角‘连接’,选择MySQL,输入密码,即可链接。
创建
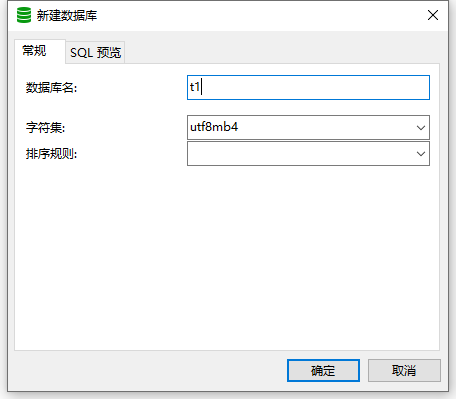
选择连接,右键新建数据库,输入数据库名,选择‘utf8mb4’字符集。
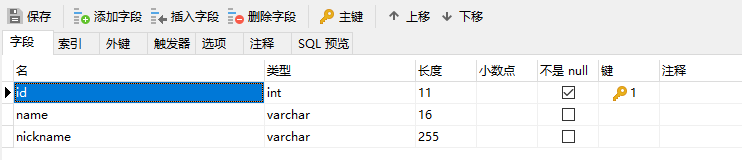
双击数据库,选择表,右键新建表,输入字段名和字段类型,设置主键。
外键
点击外键,设置完之后选择保存即可。

表的连接关系
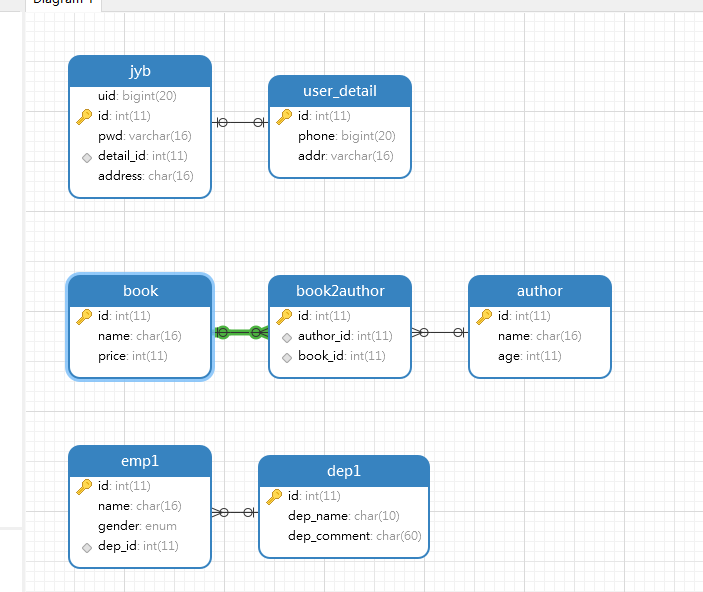
选择数据库,右键选择‘逆向数据库到模型’,可以看到表之间的连接关系。
SQL文件
选择一个数据库,右键选择‘转储SQL文件--结构和数据’,可以生成一个sql文件。
使用sql文件
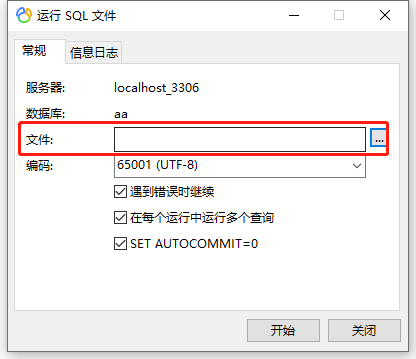
新建一个数据库,右键‘运行SQL文件’,选择文件导入,即可使用。
作业
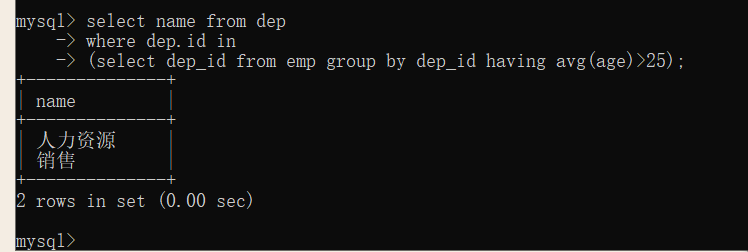
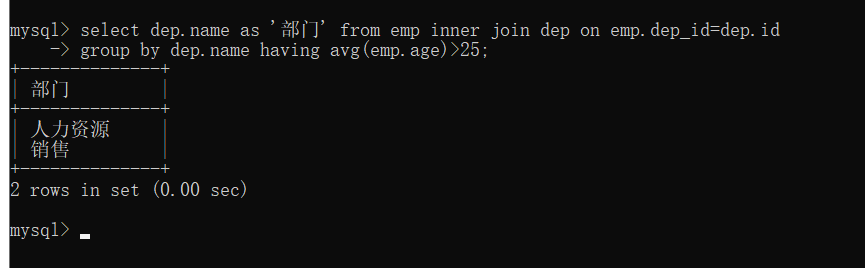
查询平均年龄在25岁以上的部门
连表
select dep.name as '部门' from emp inner join dep on emp.dep_id=dep.id group by dep.name having avg(emp.age)>25;
子查询
select name from dep where dep.id in (select dep_id from emp group by dep_id having avg(age)>25);