
一周知识总结
0816(周一)内容概要
-
字符编码
理论居多 结论很少 学习简单 -
文件操作
代码操作文件 -
登录注册功能
稍微有一点点难度
0816内容详细
字符编码
"""
计算机是基于电工作的 而电信号只有高低电平两种状态
也就是说计算机只认识两种状态 人为的定义为数字0和1即二进制
人类的字符与数字之间存在对应关系
相当于发电报彼此携带的密码本一样
"""
1.一家独大
计算机是美国人发明的 想让计算机认识英文
ASCII码
内部记录了英文与数字的对应关系
2.群雄割据
中国人
GBK码
内部记录了英文 中文与数字的对应关系
韩国人
Euc_kr码
内部记录了英文 韩文与数字的对应关系
日本人
shift_JIS码
内部记录了英文 日文与数字的对应关系
3.天下一统
unicode码(万国码)
内部记录了各个国家文字与数字的对应关系
utf8(万国码优化版本)
目前默认使用该编码
"""
1.以后文本文件如果出现了乱码肯定是因为字符编码选错了
尝试着切换字符编码即可
"""
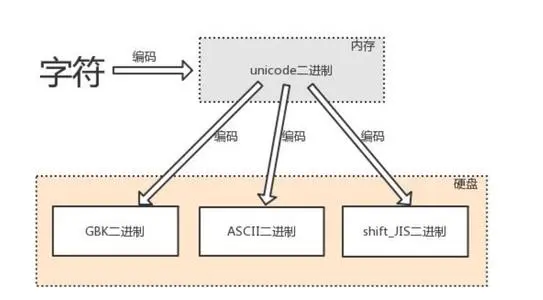
编码与解码
# 编码
按照指定的编码本将人类的字符编程成计算机能够识别的二进制数据
# 解码
按照指定的编码本将计算机的二进制数据解析成人类能够读懂的字符
"""代码如何实现"""
res = '年轻不是挥霍的资本 年轻应该实现更多的成就'
# 编码
res1 = res.encode('gbk')
print(res1)
# 解码
res2 = res1.decode('gbk')
print(res2)
文件操作
# 第一种(推荐使用)
with open(文件路径,读写模式,字符编码) as 变量名:
with子代码
# 第二种(不推荐使用)
变量名 = open(文件路径,读写模式,字符编码)
一系列操作
变量名.colse()
读写模式
r 只读模式
1.文件路径不存在会直接报错
2.文件存在则打开并可读取文件内容
光标在文件开头
with open(r'aaa.txt', 'r', encoding='utf8') as f:
print(f.read()) # 一次性读取文件内容
w 只写模式
1.文件路径不存在会自动创建
2.文件路径存在会先清空该文件内容然后再写入
with open(r'aaa.txt', 'w', encoding='utf8') as f:
f.write('你好你好你好\n')
a 只追加模式
1.文件路径不存在会自动创建
2.文件路径存在光标会移动到文件末尾
with open(r'aaa.txt', 'a', encoding='utf8') as f:
f.write('你追我 如果你追到我 我就让你...')
补充知识
读取优化
with open(r'aaa.txt', 'r', encoding='utf8') as f:
for line in f: # 一行行读取文件内容 能够避免内存溢出
print(line)
操作模式
t模式
文本模式(也是上述三种读写模式默认的模式)
rt
wt
at
1.该模式只能操作文本文件
2.该模式下必须指定encoding参数
3.读写都是以字符串为单位
b模式
二进制模型
rb
wb
ab
1.该模式可以操作任意类型的文件
2.该模式下不需要指定encoding参数
3.读写都是以bytes(二进制)为单位

0817(周二)内容概要
-
文件操作补充
-
函数(重要)
函数的定义 函数的参数

0817内容详细
文件操作补充
# 方法补充
with open(r'userinfo.txt','a',encoding='utf8') as f:
print(f.readable()) # True
print(f.writable()) # False
f.writelines(['jyb','123','555'])
"""
1.flush()
将内存中的数据立刻刷到硬盘 相当于ctrl+s
2.readable() writeable()
判断文件是否可读可写
3.writelines()
括号内放列表 多个元素都会被依次写入
"""
光标移动
# 文件光标移动 及 文件修改
"""
seek方法可以控制光标的移动
seek(offset,whence)
offset用来控制移动的位数
whence是操作模式
0:既可以用在文本模式也可以用在二进制模式
文件开头
1:只可以在二进制模式下使用
当前位置
2:只可以在二进制模式下使用
文件末尾
"""
# with open(r'a.txt', 'r', encoding='utf8') as f:
# data = f.read()
# print(data)
# # 控制光标移动
# f.seek(1, 0) # 移动到文件开头并往后再移动一个字符
# print(f.read())
# with open(r'a.txt', 'rb') as f:
# data = f.read(4)
# print(data.decode('utf8'))
# # 控制光标移动
# f.seek(-3, 2) # 二进制模式下移动的是字节数
# print(f.read().decode('utf8'))
文件修改
# 文件修改
# with open(r'a.txt','r',encoding='utf8') as f:
# data = f.read()
# with open(r'a.txt','w',encoding='utf8') as f:
# f.write(data.replace('jyb','tony'))
# 创建一个新文件 将老文件内容写入新文件 过程中完成修改
# 之后将老文件删除 将新文件命名成老文件 从而达到修改的效果
import os
with open(r'a.txt','r',encoding='utf8') as f,open(r'a.txt.backend','w',encoding='utf8') as f1:
for line in f:
f1.write(line.replace('tony','jyb'))
os.remove(r'a.txt')
os.rename(r'a.txt.backend',r'a.txt')
函数
函数就相当于是工具
提前定义好后续可以反复使用,避免了代码冗余的情况
eg:修理工与工具的案例
函数的语法结构
def 函数名(参数1,参数2):
'''函数的注释'''
函数体代码
return 函数的返回值
"""
1.def
定义函数的关键字
2.函数名
函数名的命名与变量名保持一致 见名知意
3.参数
函数在使用之前还可以接收外部传入的参数
4.函数的注释
类似于产品说明书
5.函数体代码
整个函数主要功能逻辑 是整个函数的核心
6.return
执行完函数之后可以给调用者一个反馈结果
"""
函数的基本使用
# 函数的使用一定要先定义后使用!!!
0818(周三)内容概要
-
函数的返回值
-
函数的类型
-
函数的参数(重要)
-
利用函数对注册登录代码进行封装
-
常见的内置函数
内置函数就是python解释器内部自带的函数 别人已经写好了你直接使用即可

0818内容详细
强调
# 1.定义与调用
定义函数使用关键字def
调用函数需要使用
函数名加括号(如果函数需要参数那么则额外传递参数)
# 2.定义阶段
函数在定义阶段只检测函数体语法不执行函数体代码
# 3.调用阶段
函数名加括号调用函数的时候才会执行函数体代码
函数的返回值
def index():
print('from index')
return 123, 555, 66, 5, 4, 5, 4
print('from index')
index()
# 什么是返回值?
"""返回值即执行完某个方法该方法反馈出来的结果"""
# 如何获取返回值?
"""通过变量名与赋值符号即可
变量名 = 方法/函数()
"""
# 1.当函数体没有return关键字的时候 默认返回None
# res = index()
# print(res) # None即空 表示没有
# 2.return关键字后面写什么函数就返回什么
# res = index()
# print(res) # 123
# 3.return后面跟多个值默认会组织成元组的形式返回
# res = index()
# print(res) # (123, 555, 66, 5, 4, 5, 4)
# 4.函数体代码遇到return立刻结束整个函数的运行
函数的类型
# 1.无参函数:函数在定义阶段没有参数调用阶段也不需要参数
# def index():
# print('from index')
# index()
# 2.有参函数:函数在定义阶段括号内填写了变量名即需要参数
# def index(x):
# print('from index', x)
# index(1)
# 3.空函数(没有具体的函数体代码)
"""一般用于前期的架构搭建"""
def run():
pass # 补全语法结构 本身没有任何含义
def fight():
pass
def talk():
pass
函数的参数
"""
函数在定义阶段括号内书写的变量名称之为函数的形式参数
简称为形参
函数的形参相当于变量名
函数在调用阶段括号内书写的值称之为函数的实际参数
简称为实参
函数的实参相当于变量值
两者在调用函数的时候临时绑定 函数运行结束分开
def index(name): 形参
print(name)
index('jyb') 实参 name = 'jyb'
"""
# 1.位置参数:按照位置一一对应传值 多一个不行少一个也不行
def index(x, y):
print(x, y)
# index() # 不传不可以
# index(1) # 传少了也不行
# index(1,2) # 个数正确可以
# index(1,2,3,4,5,6,7) # 传多了也不行
# 2.关键字参数:指名道姓的给形参传值 可以打破位置限制
# index(y=111, x=222)
# index(111, y=222)
# index(111, x=222) # 报错
# print(y=111,222) # 报错 位置参数一定要在关键字参数的前面
# 3.默认参数:函数在定义阶段就给形参赋值了
# def register(name, age, gender='male'):
# print(name, age, gender)
# '''默认参数不给值的情况下就使用默认的 给了就使用给了的'''
# register('jyb', 18)
# register('tony', 28)
# register('kevin', 38)
# register('huahua', 18, 'female')
# 4.可变长参数(使用频率最高)
'''函数如何做到无论接收多少个位置参数都可以正常运行
*在形参中使用
会接收多余的位置参数组织成元组的形式赋值给*后面的变量名
'''
# def func(a, *b):
# print(a, b)
# func(1,2,3,4,5,6,7,8,9,10)
# func(1)
"""函数如何做到无论接收多少个关键字参数都可以正常运行
**在形参中使用
会接收多余的关键字参数组织成字典的形式赋值给**后面的变量名
"""
# def func(a,**b):
# print(a,b)
# func(a=1,b=2,c=3,d=4,e=5)
# func(a=1)
# 小练习 定义一个函数 该函数无论接收多少个位置参数还是关键字参数都可以正常运行
def func(*a, **b):
print(a, b)
func(1, 2, 3, a=1, b=2, c=3)
func(1, 2, 3, 4, 5, 6, 7)
func(a=1, b=2, c=3)
"""
约定俗成
针对形参中的可变长参数 变量名推荐使用
*args **kwargs
def login(*args, **kwargs):
pass
"""
*与**在实参中的作用
l = [11, 22, 33, 44, 55]
d = {'username': 'jyb', 'pwd': 123, 'hobby': 'read'}
def func(*args, **kwargs):
print(args, kwargs)
"""
*在实参中使用
会将列表/元组内的元素打散成一个个位置参数传递给函数
"""
func(*l) # func(11,22,33,44,55)
"""
**在实参中使用
会将字典内的元素打散成一个个关键字参数传递给函数
"""
func(**d) # func(username='jyb',pwd=123,hobby='read')

利用函数对注册登录代码进行封装
def register():
username = input('username>>>:').strip()
password = input('password>>>:').strip()
# 校验用户名是否存在
with open(r'userinfo.txt', 'r', encoding='utf8') as f:
for line in f:
real_name = line.split('|')[0]
if real_name == username:
print('用户名已存在')
return
# 将用户名和密码写入文件
with open(r'userinfo.txt', 'a', encoding='utf8') as f:
f.write('%s|%s\n' % (username, password))
print('%s注册成功' % username)
def login():
username = input('username>>>:').strip()
password = input('password>>>:').strip()
with open(r'userinfo.txt', 'r', encoding='utf8') as f:
for line in f:
real_name, real_pwd = line.split('|')
if real_name == username and password == real_pwd.strip('\n'):
print('登录成功')
return
print('用户名或密码错误')
func_dict = {'1': register,
'2': login
}
while True:
print("""
1 注册
2 登录
""")
choice = input('请输入执行功能编号>>>:').strip()
if choice in func_dict:
func_name = func_dict.get(choice)
func_name()
else:
print('请输入正确的编号')
封装代码的精髓
"""
将面条版代码封装成函数版
1.先写def和函数名
2.将代码缩进
3.查看内部需要哪些数据
4.在形参中定义出来即可
尽量做到一个函数就是一个具体的功能
"""
def auth_username(username):
# 校验用户名是否存在
with open(r'userinfo.txt', 'r', encoding='utf8') as f:
for line in f:
real_name = line.split('|')[0]
if real_name == username:
print('用户名已存在')
return True
return False
def get_info():
username = input('username>>>:').strip()
password = input('password>>>:').strip()
return username, password
def write_data(username, password):
# 将用户名和密码写入文件
with open(r'userinfo.txt', 'a', encoding='utf8') as f:
f.write('%s|%s\n' % (username, password))
print('%s注册成功' % username)
def register():
username, password = get_info()
# 调用校验用户名是否存在的函数
is_exist = auth_username(username)
if is_exist:
return
write_data(username, password)
def login():
username, password = get_info()
with open(r'userinfo.txt', 'r', encoding='utf8') as f:
for line in f:
real_name, real_pwd = line.split('|')
if real_name == username and password == real_pwd.strip('\n'):
print('登录成功')
return
print('用户名或密码错误')
func_dict = {'1': register,
'2': login
}
while True:
print("""
1 注册
2 登录
""")
choice = input('请输入执行功能编号>>>:').strip()
if choice in func_dict:
func_name = func_dict.get(choice)
func_name()
else:
print('请输入正确的编号')
内置函数
# print(abs(-111))
# print(all([1, 2, 3, 4, 0]))
# print(any([1, 2, 3, 4, 0]))
# print(bin(100))
# print(oct(100))
# print(hex(100))
# name = 'jyb'
# def index():
# pass
# 判断变量是否可以调用
# print(callable(name)) # False
# print(callable(index)) # True
# 返回ASCII码中数字对应的字符
# print(chr(65)) # A 65-90
# print(chr(122)) # z 97-122
# format字符串格式化输出
# print('my name is {} and my age is {}'.format('jyb',18))
# print('my name is {0} {1} {1} and my age is {1} {0}'.format('jyb',18))
# print('my name is {name} {name} {age} and my age is {age}'.format(name='jyb',age=18))
# l = ['jyb', 'kevin', 'tony', 'jerry', 'tom']
# count = 1
# for name in l:
# print(count,name)
# count += 1
# for i, name in enumerate(l, 10):
# print(i, name)
# l = [11, 22, 33, 44, 55, 66, 77, 88, 99]
# print(max(l))
# print(min(l))
# print(sum(l))

0819(周四)内容概要
-
函数名称空间与作用域
-
匿名函数与列表生成式等知识补充
-
模块(重要)
白嫖别人的劳动成功 -
常见内置模块
0819内容详细
函数名称空间与作用域
名称空间
存放变量与值绑定关系的地方
1.内置名称空间
python解释器启动立刻创建结束立刻销毁
2.全局名称空间
伴随python文件的开始执行/执行完毕而产生/回收
3.局部名称空间
函数体代码运行产生结束销毁
# 加载顺序:内置名称空间 > 全局名称空间 > 局部名称空间
'''作用域'''
全局作用域
内置名称空间 全局名称空间
局部作用域
局部名称空间
作用域的查找顺序一定要先明确你当前在哪
如果当前在局部名称空间
局部名称空间 全局名称空间 内置名称空间
如果当前在全局名称空间
全局名称空间 内置名称空间
如果当前在内置名称空间
内置名称空间
# 顺序只能从左往右 不能反向
如果想在局部修改全局名称空间中的名字对应的值可以使用global关键字
count = 1
def index():
global count
count += 1
index()

小练习
name = 'jack'
def func1():
name = 'jyb'
def func2():
name = 'kevin'
def func3():
name = 'tony'
func1()
func2()
func3()
print(name)
x=1
def outer():
x=2
def inner():
x=3
print('inner x:%s' %x)
inner()
print('outer x:%s' %x)
outer()
匿名函数与列表生成式等知识补充
匿名函数
即没有函数名的函数
语法结构
lanbda 形参:返回值
# 匿名函数一般不单独使用 需要结合内置函数/自定义函数等一起使用
l = [1, 2, 3, 4, 5, 6, 7]
res = map(lambda x: x + 10, l)
print(list(res))
def index(x):
return x + 10
res1 = map(index,l)
print(list(res1))
"""匿名函数主要用于一些比较简单的业务逻辑中 减少代码量"""
列表生成式
l1 = [11, 22, 33, 44, 55, 66, 77, 88]
# 将列表中每个元素加一
new_list = []
for i in l1:
new_list.append(i+1)
print(new_list)
# 列表生成式
new_list = [i + 1 for i in l1]
print(new_list)
name_list = ['jyb', 'kevin', 'tony', 'oscar']
# 将列表每个元素后面加上_NB的后缀
new_list = []
for name in name_list:
new_list.append(name + '_NB')
print(new_list)
# 列表生成式
new_list1 = [name+'_NB' for name in name_list]
print(new_list1)
l1 = [11, 22, 33, 44, 55, 66, 77, 88, 99]
# 筛选出加一之后大于60的元素
new_list = []
for i in l1:
if i+1 > 60:
new_list.append(i)
print(new_list)
# 列表生成式
new_list1 = [i for i in l1 if i+1 > 60]
print(new_list1)
三元表达式
"""
小知识补充
name = 'jyb'
if name == 'jyb': print('jyb登录成功')
当if子代码只有一行的情况下可以整体写在一行 但是不推荐
"""
# while True:
# name = input('username>>>:')
# if name == 'jyb':
# print('NB')
# else:
# print('SB')
# 当if判断仅仅是二选一的情况下 可以使用三元表达式
name = input('username>>>:')
res = 'NB' if name == 'jyb' else 'SB'
print(res)
# 语法结构
A if 条件 else B
当if后面的条件为True的时候使用A
为False使用else后面的B
模块的使用
# 什么是模块与包
具有一定功能的代码集合
可以是py文件 也可以是多个py文件的组合即文件夹(包)
# 导入模块的本质
会执行模块内代码并产生一个该模块的名称空间
将代码执行过程中的名字存放该名称空间中
然后给导入模块的语句一个模块名 该模块指向模块的名称空间
'''重复导入相同的模块 只会执行一次'''
b.py
import aaa
aaa.py
name = 'jyb'
def index():
pass
# 导入模块的两种句式
import 模块名
可以通过模块名点出所有的名字
from 模块名 import 子名1,子名2
只能指名道姓的使用import后导入的子名并且还存在冲突的风险
# from句式主要用于模块与当前文件不在同一级目录下使用
# 如果模块名较长或者不符合你的看法 可以起别名
import asjdkjkasdjaskdkasdasdjsjdksadksajdkasjd as ad
from d1.d2 import f1 as fff
内置模块之时间模块
# import time
# print(time.time()) # 1629346116.5301917
"""时间戳:是从1970年1月1日(UTC/GMT的午夜)开始所经过的秒数,不考虑闰秒"""
# print(time.strftime('%Y-%m-%d')) # 2021-08-19
# print(time.strftime('%Y-%m-%d %H:%M:%S')) # 2021-08-19 12:11:32
# print('该睡了')
# time.sleep(3)
# print('睡醒了')
# def index():
# print('123')
# time.sleep(3)
# print('哈哈哈')
# # 统计index函数执行的时间
# start_time = time.time()
# index()
# end_time = time.time()
# print(end_time - start_time)
import datetime
# print(datetime.date.today()) # 2021-08-19
# print(datetime.datetime.today()) # 2021-08-19 12:18:44.564270
# 获得本地日期 年月日
tday = datetime.date.today()
# 定义操作时间 day=7 也就是可以对另一个时间对象加7天或者减少7点
tdelta = datetime.timedelta(days=7)
tdelta1 = datetime.timedelta(days=-7)
print(tday + tdelta1)
0820(周五)内容概要
主体:诸多内置模块
-
os模块
操作系统打交道的模块 -
hashlib模块
加密 -
random模块
随机相关功能 抽奖 掷色子 洗牌 -
logging模块
日志相关模块 类似于监控 记录 -
json模块
不同编程语言之间数据交互的通用格式
0820内容详细
强调
'''在创建py文件的时候文件名一定不能跟模块名冲突'''
os模块
import os
# 创建文件夹
# os.mkdir(r'文件夹01') # 只能创建单级目录
# os.makedirs(r'文件夹02\文件夹03') # 可以创建多级目录
# os.makedirs(r'文件夹03')
# 删除文件夹
# os.rmdir(r'文件夹01')
# os.rmdir(r'文件夹02\文件夹03') # 默认只能删一级空目录
# os.removedirs(r'文件夹02\文件夹03\文件夹04') # 可以删除多级空目录
# 查看
# print(os.listdir()) # 查看指定路径下所有的文件及文件夹
# print(os.listdir('D:\\')) # 查看指定路径下所有的文件及文件夹
# print(os.getcwd()) # 查看当前所在的路径
# os.chdir(r'文件夹03') # 切换当前操作路径
# print(os.getcwd()) # 查看当前所在的路径
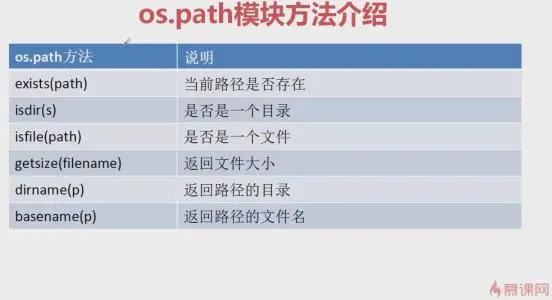
# 判别
# print(os.path.isdir(r'a.txt')) # 判断是否是文件夹
# print(os.path.isdir(r'文件夹03'))
# print(os.path.isfile(r'a.txt')) # 判断是否是文件
# print(os.path.isfile(r'文件夹03'))
# print(os.path.exists(r'a.txt')) # 判断当前路径是否存在
# print(os.path.exists(r'文件夹03'))
# 路径拼接
"""
不同的操作系统路径分隔符是不一样的
windows是 \
mac是 /
"""
# res = os.path.join('D:\\','a.txt') # 该方法可以针对不同的操作系统自动切换分隔符
# 文件大小
print(os.path.getsize(r'a.txt')) # 字节数
hashlib模块
加密模块
将明文数据按照一定的逻辑变成密文数据
一般情况下密文都是由数字字母随机组合而成
加密算法
将明文数据按照一定的逻辑(每个算法内部逻辑都不一样)
加密之后的密文不能反解密出明文
# 常见加密算法:md5 base64 hmac sha系列
"""算法生成的密文越长表示该算法越复杂"""
import hashlib
# 选择加密算法:一般情况下采用md5即可
# md5 = hashlib.md5()
# 将待加密的数据传入算法中
# md5.update(b'hello') # 数据必须是bytes类型(二进制)
# 获取加密之后的密文
# res = md5.hexdigest()
# print(res)
# 加盐处理:在对用户真实数据加密之前再往里添加额外的干扰数据
# 选择加密算法:一般情况下采用md5即可
# md5 = hashlib.md5()
# # 将待加密的数据传入算法中
# # 加盐
# md5.update('自己定制的盐'.encode('utf8'))
# md5.update(b'hello') # 数据必须是bytes类型(二进制)
# # 获取加密之后的密文
# res = md5.hexdigest()
# print(res)
# 动态加盐
# 选择加密算法:一般情况下采用md5即可
md5 = hashlib.md5()
# 将待加密的数据传入算法中
# 加盐
md5.update('不固定 随机改变'.encode('utf8'))
md5.update(b'hello') # 数据必须是bytes类型(二进制)
# 获取加密之后的密文
res = md5.hexdigest()
print(res)
random模块
随机数模块
import random
# 随机返回0-1之间的小数
# print(random.random())
# 随机返回指定区间的整数 包含首尾
# print(random.randint(1,6)) # 掷色子
# 随机抽取一个
# print(random.choices(['一等奖','二等奖','谢谢回顾'])) # 抽奖
# print(random.choice(['一等奖','二等奖','谢谢回顾']))
# 随机抽取指定样本个数
# print(random.sample([111, 222, 333, 444, 555, 666, 777], 2))
# 随机打乱元素
# l = [2, 3, 4, 5, 6, 7, 8, 9, 10, "J", "Q", "K", "A", "小王", "大王"]
# random.shuffle(l) # 洗牌
# print(l)
# 随机验证码
"""
产生一个五位数随机验证码(搜狗笔试题)
每一位都可以是数字\小写字母\大写字母
"""
def get_code(n):
code = ''
for i in range(n): # 循环五次决定是几位验证码
# 每一次循环都应该是三选一
# 随机的数字
random_int = str(random.randint(0, 9))
# 随机的小写字母
random_lower = chr(random.randint(97, 122))
# 随机的大写字母
random_upper = chr(random.randint(65, 90))
# 随机选择一个作为一位验证码
temp = random.choice([random_int, random_lower, random_upper])
code += temp
return code
print(get_code(4))

logging模块
import logging
# 日志级别
# logging.debug('debug message')
# logging.info('info message')
# logging.warning('warning message')
# logging.error('error message')
# logging.critical('critical message')
# import logging
#
# file_handler = logging.FileHandler(filename='x1.log', mode='a', encoding='utf-8',)
# logging.basicConfig(
# format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
# datefmt='%Y-%m-%d %H:%M:%S %p',
# handlers=[file_handler,],
# level=logging.ERROR
# )
#
# logging.error('你好')
# import time
# import logging
# from logging import handlers
#
# sh = logging.StreamHandler()
# rh = handlers.RotatingFileHandler('myapp.log', maxBytes=1024,backupCount=5)
# fh = handlers.TimedRotatingFileHandler(filename='x2.log', when='s', interval=5, encoding='utf-8')
# logging.basicConfig(
# format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
# datefmt='%Y-%m-%d %H:%M:%S %p',
# handlers=[fh,sh,rh],
# level=logging.ERROR
# )
#
# for i in range(1,100000):
# time.sleep(1)
# logging.error('KeyboardInterrupt error %s'%str(i))
import logging
logger = logging.getLogger()
# 创建一个handler,用于写入日志文件
fh = logging.FileHandler('test.log',encoding='utf-8')
# 再创建一个handler,用于输出到控制台
ch = logging.StreamHandler()
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
fh.setLevel(logging.DEBUG)
fh.setFormatter(formatter)
ch.setFormatter(formatter)
logger.addHandler(fh) #logger对象可以添加多个fh和ch对象
logger.addHandler(ch)
logger.debug('logger debug message')
logger.info('logger info message')
logger.warning('logger warning message')
logger.error('logger error message')
logger.critical('logger critical message')

json模块
d = {'username': 'jyb', 'pwd': 123}
import json
# 简单的理解为
# 可以将其他数据类型转换成字符串
# 也可以将字符串转换成其他数据类型
"""序列化:将其他数据类型转换成json格式的字符串"""
# res = json.dumps(d)
# print(res, type(res)) # {"username": "jyb", "pwd": 123} <class 'str'>
# d1 = {"username": "jyb", "pwd": 123}
# print(d1)
# 只有json格式字符串才会是双引号 双引号就是判断json格式字符串的重要依据
"""反序列化:将json格式字符串转换成对应的数据类型"""
# res1 = json.loads(res)
# print(res1, type(res1)) # {'username': 'jyb', 'pwd': 123} <class 'dict'>
# with open(r'a.txt','w',encoding='utf8') as f:
# 文件序列化
# json.dump(d,f)
# with open(r'a.txt','r',encoding='utf8') as f:
# 文件反序列化
# res = json.load(f)
# print(res,type(res))
并不是所有的python数据都可以转json格式字符串
+-------------------+---------------+
| Python | JSON |
+===================+===============+
| dict | object |
+-------------------+---------------+
| list, tuple | array |
+-------------------+---------------+
| str | string |
+-------------------+---------------+
| int, float | number |
+-------------------+---------------+
| True | true |
+-------------------+---------------+
| False | false |
+-------------------+---------------+
| None | null |
+-------------------+---------------+
