python计算相似度
代码:
import numpy as np
import pandas as pd
# numpy方式
data = np.loadtxt('1.txt', delimiter=',') # 读取数据文件
X = data[:, 0]
Y = data[:, 1]
corr = np.corrcoef(X, Y)
print(corr.round(4))
# pandas方式
data1 = pd.DataFrame({"x": X, "y": Y})
# print(data1['x'])
print(data1.corr().round(4))
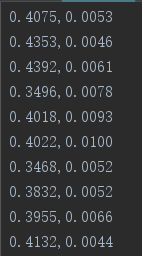
文件1.txt的部分数据:
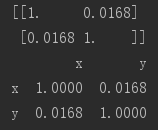
运行结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号