【redis】redis深入了解
狂神老师的视频地址:https://space.bilibili.com/95256449
1、Redis持久化
为什么需要持久化,因为redis的数据在内存中,所以需要把数据保存到内存当中。
1.1、RDB
在指定的时间间隔里将内存中的数据集快照写入磁盘,也就是行话里的Snapshot快照,它恢复时是将快照文件直接读到内存里。
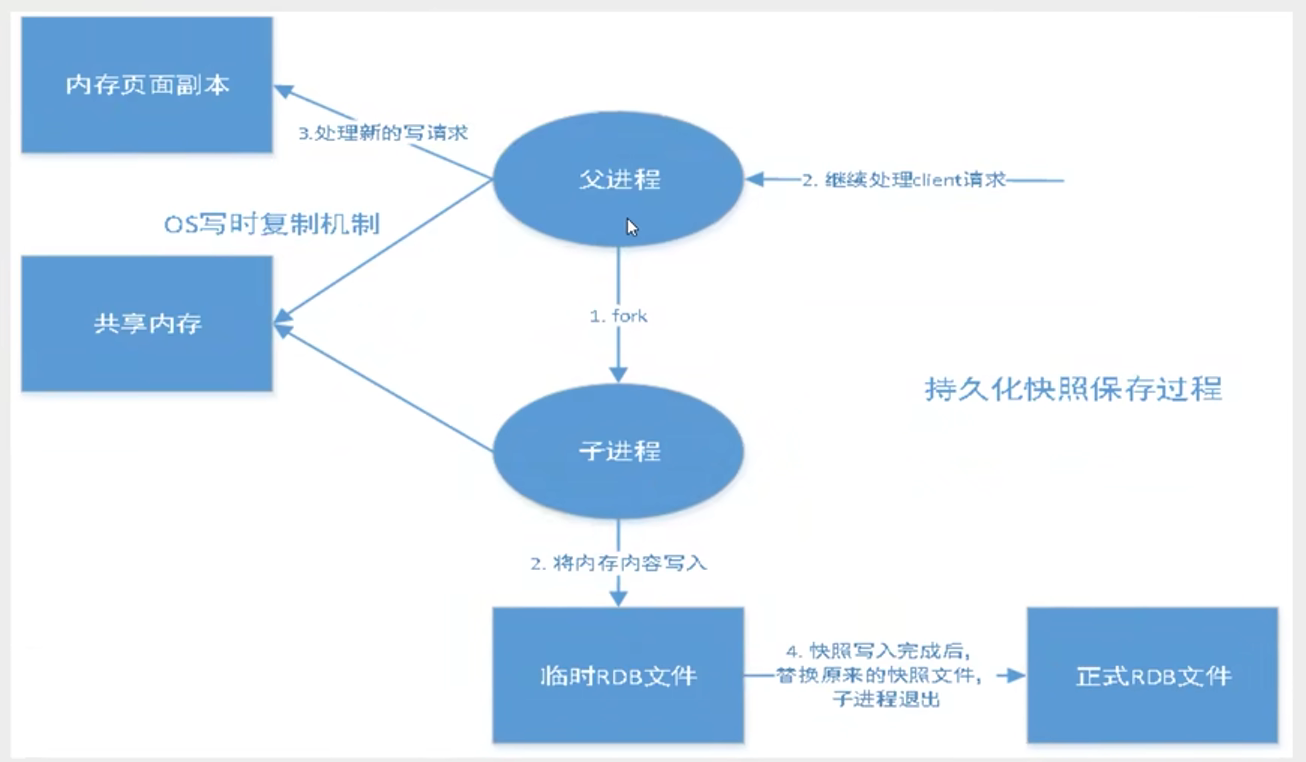
Redis会单独创建一个子线程来进行持久化,会先将数据写入到一个临时文件中.
待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中主线程不进行任何的IO操作
这就确保了极高的性能,如果需要大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。
RDB的缺点是最后一次持久化后的数据可能会丢。我们默认就是RDB,一般不需要修改这个配置
rdb保存的文件dump.rdb
- 触发机制
1、save的规则满足的情况下,会自动触发rdb规则
save 900 1 # 900s 1次改动
save 300 10 # 300s 10次改动
save 60 10000 # 60s 10000次改动
#当然也可以自定义
2、执行flushall命令也会触发
3、退出redis,也会产生
- 如何恢复
1、只需要把rdb文件放到启动目录下面就好了,启动会自动恢复数据
2、下面是查看启动目录的方式
127.0.0.1:6379> config get dir
1) "dir"
2) "D:\\Enviroment\\Redis-x64-5.0.14.1"
- 优缺点
优点:
- 适合大规模数据恢复,因为用的子线程
- 对数据完整性要求不高的时候,性能很快
缺点:
- 需要一定的时间间隔进行操作,如果redis意外宕机,最后一次的修改数据就没了
- fork进程的时候会占用一定的内存空间
1.2、AOF(Append Only File)
以日志的形式记录每个写操作,将redis所有的指令记录下来,只需追加文件不可以改写文件。redis启动之后会读取这个文件重新构建数据
Aof保存的是appendonly.aof文件
AOF参数配置
打开参数文件,其中有AOF的相关配置,默认是关闭的
############################## APPEND ONLY MODE ###############################
# By default Redis asynchronously dumps the dataset on disk. This mode is
# good enough in many applications, but an issue with the Redis process or
# a power outage may result into a few minutes of writes lost (depending on
# the configured save points).
#
# The Append Only File is an alternative persistence mode that provides
# much better durability. For instance using the default data fsync policy
# (see later in the config file) Redis can lose just one second of writes in a
# dramatic event like a server power outage, or a single write if something
# wrong with the Redis process itself happens, but the operating system is
# still running correctly.
#
# AOF and RDB persistence can be enabled at the same time without problems.
# If the AOF is enabled on startup Redis will load the AOF, that is the file
# with the better durability guarantees.
#
# Please check http://redis.io/topics/persistence for more information.
appendonly no
只需要把no改成yes。
重启redis就生效了,会生成一个appendonly.aof文件
修复文件和数据恢复
如果appendonly.aof文件有误,会导致redis启动失败
这个时候redis提供了一个修复工具 redis-check-aof --fix 来修复appendonly.aof文件,
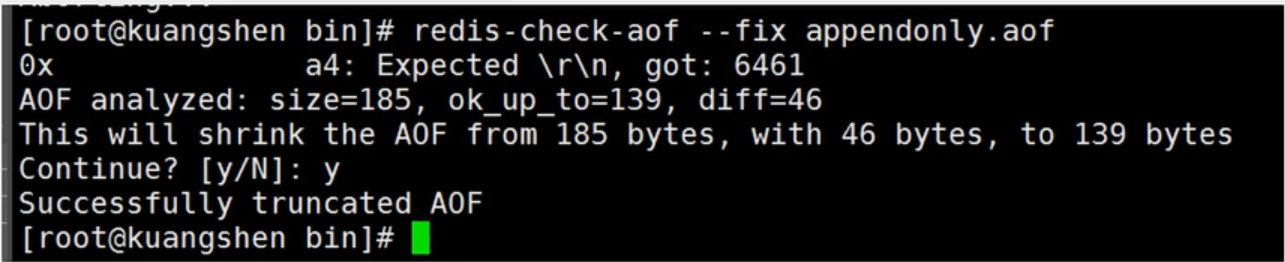
如果appendonly.aof文件正常,重启redis就是恢复数据了。
优缺点:
优点:有三个配置,分别优点如下:
appendonly no #默认不开启 aof,默认使用rdb,一般够用
appendfilename "appendonly.aof" #持久化文件的名字
# appendfsync always #每次修改都会同步
appendfsync everysec #每秒执行一次同步,可能会丢失这1s的数据
# appendfsync no #不同步
1、每一次修改都同步,文件完整性更好
2、每秒同步一次,可能丢失一秒的数据
3、从不同步的效率最高
缺点:
1、从数据文件来看,aof文件远大于rdb,修复速度也更慢
2、Aof运行效率也比rdb慢,所以默认就是rdb来恢复数据
拓展


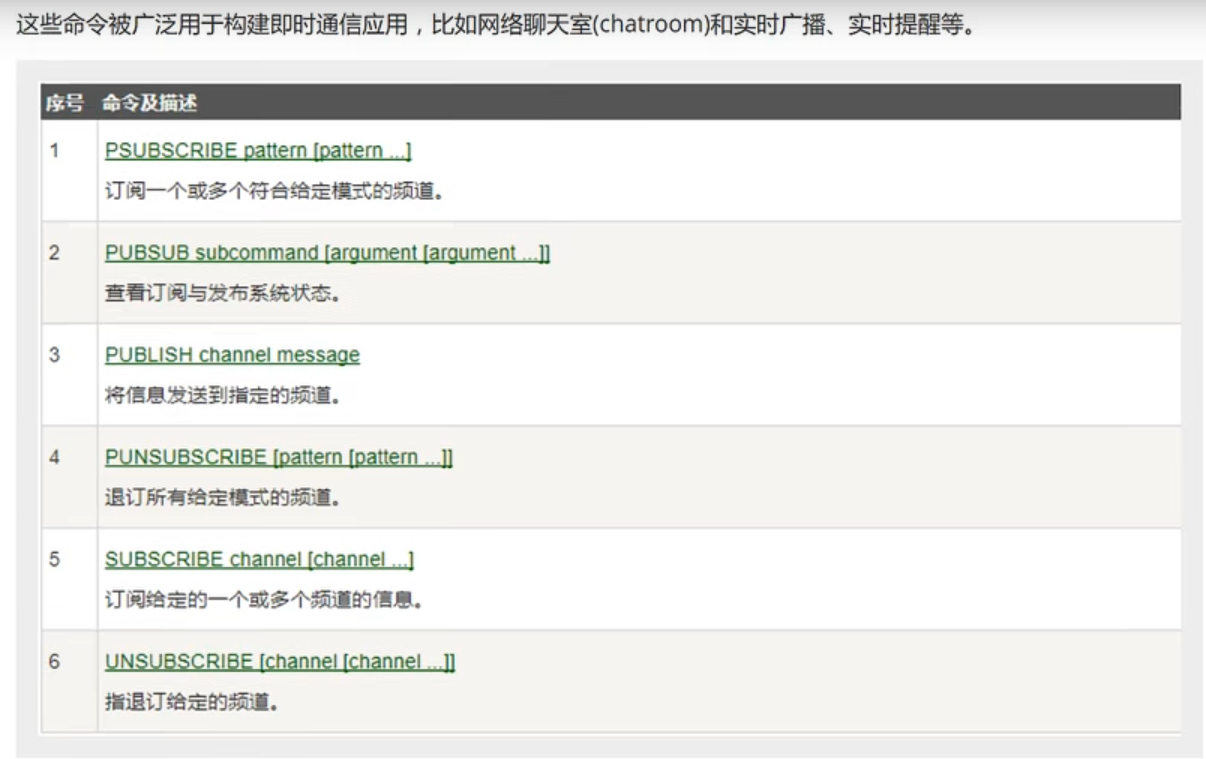
2、订阅发布
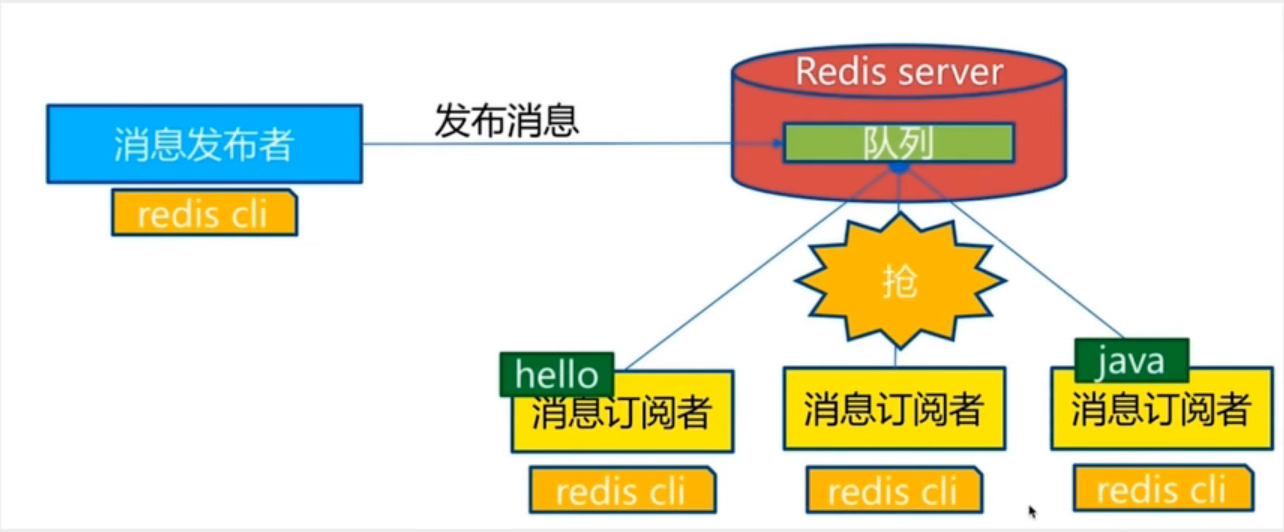
Redis发布订阅(pub/sub)是一种消息通信模式:发送者发布消息,订阅在接收消息,微信微博的关注系统就是这样的
Redis客户端可以订阅任意数量的频道。
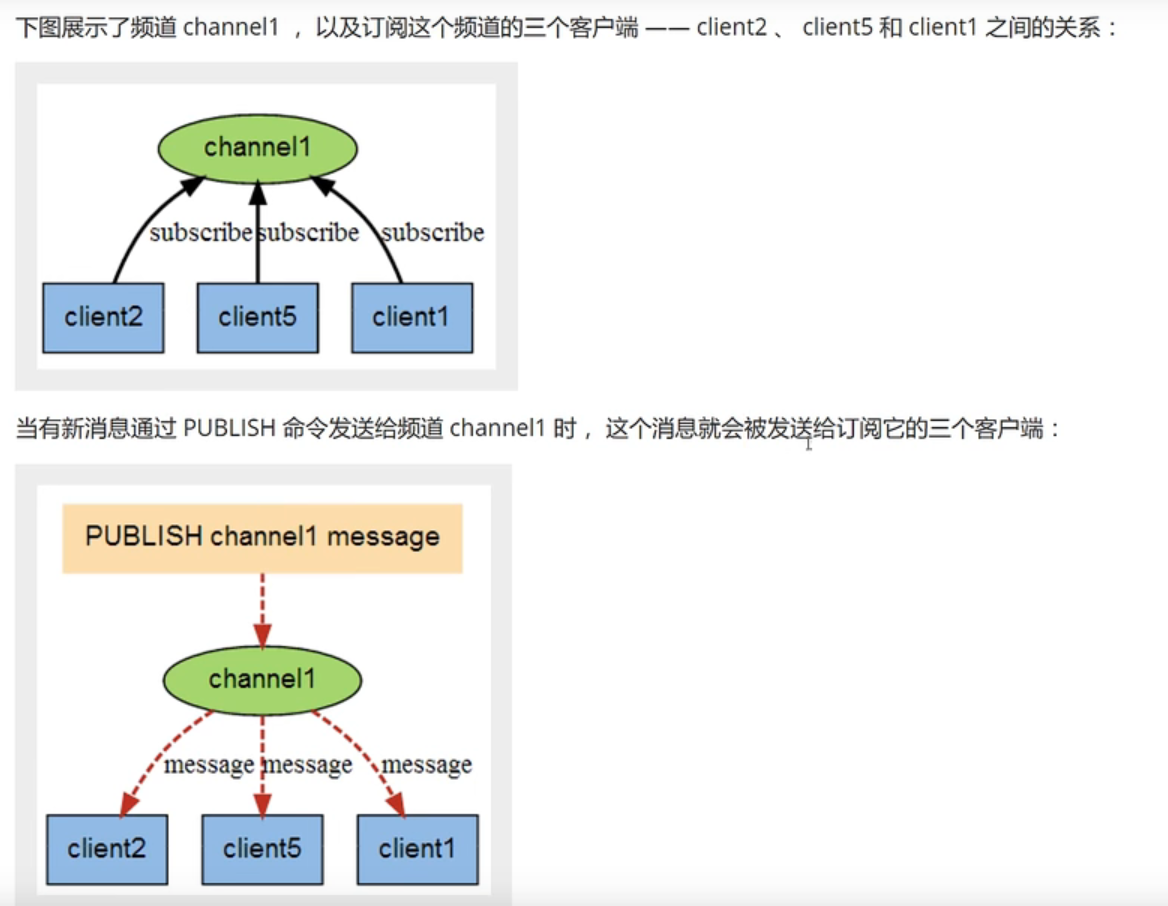
2.1、订阅/发布信息图
2.2、测试:
订阅端:
127.0.0.1:6379> subscribe wcy
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "wcy"
3) (integer) 1
发送端
127.0.0.1:6379> publish wcy "hello wcy"
(integer) 1
订阅端收到消息:
127.0.0.1:6379> subscribe wcy
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "wcy"
3) (integer) 1
1) "message"
2) "wcy"
3) "hello wcy"
使用场景:
1、实时消息系统
2、实时聊天系统
3、订阅、关注系统
稍微复杂的场景就会用到消息中间件MQ来做
3、主从复制
3.1、概念:
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者成为主节点(master/leader),后者成为从节点(slave/follower);数据的复制是单向的,只能从主节点到从节点。
Master以写为,Slave以读为主。
默认情况下,每台Redis服务器都是主节点;且一个主节点可以有多个从节点(或者没有),但是一个从节点只能有一个主节点
3.2、作用:
1、数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余的方式
2、故障恢复:当主节点出现了问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种恢复的冗余
3、负载均衡:主节点提供写服务,从节点提供读服务,分担服务器负载,尤其是适用读多写少的情景,可以很大程度提高并发量
4、高可用(集群)基础:主从复制是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础

3.3、环境配置
127.0.0.1:6379> info replication #查看当前库信息
# Replication
role:master #角色 master
connected_slaves:0 #没有从机
master_replid:111d651e246cc49215f97c2df95bf78d5dc2a4d2
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
复制3个配置文件,然后修改对应的信息
1、端口
2、pid名字(windows不支持)
3、log文件名字
4、dump.rdb名字
然后按照对应的配置文件启动:
注:windows是先启动服务 redis-server D:\Enviroment\Redis-x64-5.0.14.1\redis80.windows.conf,然后再打开一个端口连接 redis-cli -p 6380
3.4、复制原理
从机认老大:
C:\Users\86155>redis-cli -p 6380 #从机配置主机IP和端口
127.0.0.1:6380> slaveof 127.0.0.1 6379 #查看主从信息
OK
127.0.0.1:6380> info replication
# Replication
role:slave #已经变成从机
master_host:127.0.0.1 #主机ip
master_port:6379 #主机端口
master_link_status:up
master_last_io_seconds_ago:7
master_sync_in_progress:0
slave_repl_offset:56
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:6b0486e1a13898f6d4ba5907c0c7b66537d37226
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:56
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:56
如果是使用命令行配置的主从关系,重启redis之后,都会变回默认的关系(都是主机)
而真实的主从配置是在配置文件里修改的,这样是永久的
# replicaof <masterip> <masterport>
# masterauth <master-password>
设置成功之后,就已经设定好了主机可以读和写,从机只能读
如果主机断开连接,从机中的数据依旧存在,同时,如果主机恢复,从机一样可以直接读取到主机中的信息

层层链路模型:
主机-->从机-->从机,第二个从机是第三个从机的主机,但是依旧不能写
4、哨兵模式
4.1、在哨兵模式没有出来之前
如果主机宕机,通过在从机上:
127.0.0.1:6380> SLAVEOF no one
OK
可以自动让当前机器变成主机,然后其他从机手动连接到这个主机
这个时候如果主机恢复,那就需要手动重新配置
4.1、哨兵模式
就是当主机宕机后,根据投票数自动选举从机当主机
哨兵是一个独立的进程,作为进程它会独立运行,通过发送命令等待服务器响应来监控服务器
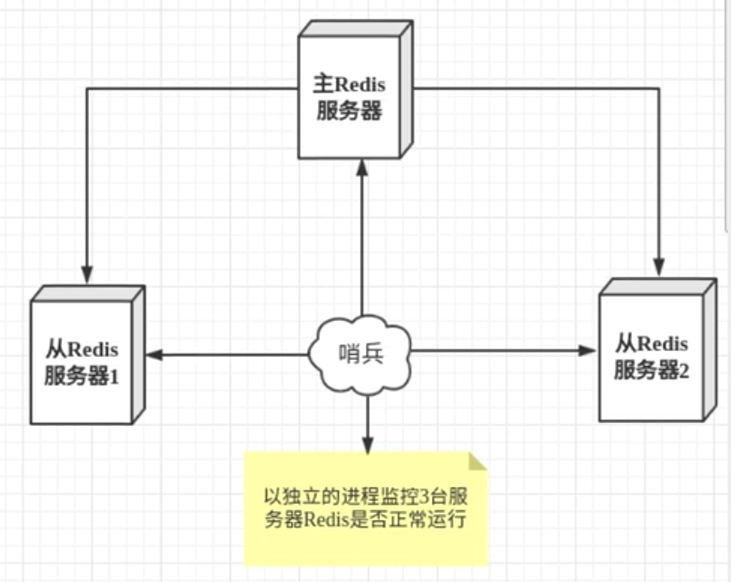
这里的哨兵有两个作用:
- 通过发送命令,让redis服务器返回信息,监控其运行状态,包括主服务器和从服务器
- 当哨兵监控到master宕机,会自动将slave切换成master,然后通过发布订阅模式通知其他从服务器,修改配置文件,让他们切换主机
但是哨兵进程也可能出现问题,所以出现了多个哨兵互相监督的模式:
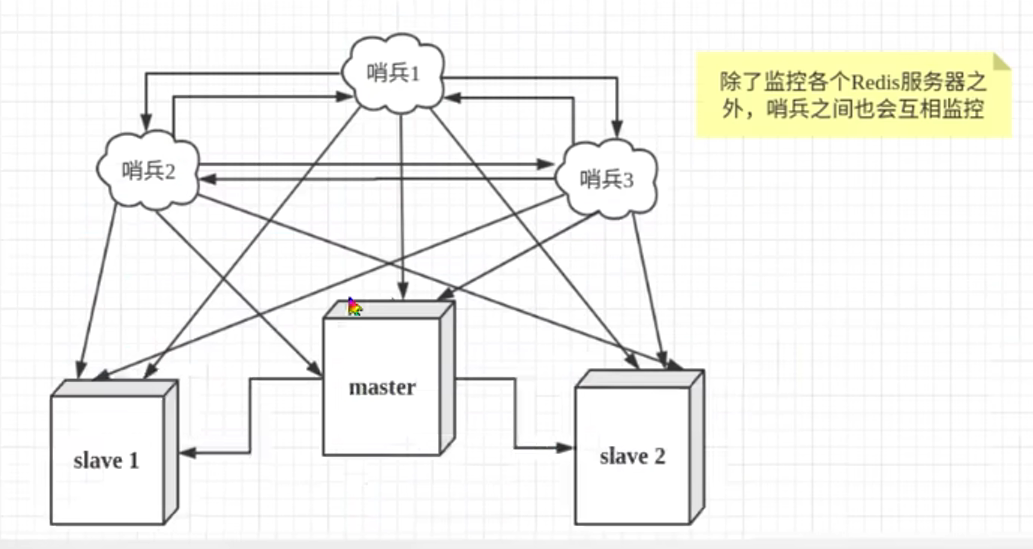
假如服务器宕机,哨兵1检测到这个情况,并不会马上进行failover,这个状态叫做主观下线,如果其他哨兵也检测到主机不可用,数量达到已成程度,
就会发起一次投票,进行failover操作。切换成功后发布订阅模式让各个哨兵分别把自己监控的从机关联主机,这个过程叫客观下线。
4.2、实现哨兵模式
1、配置哨兵配置文件
#创建配置文件
vim sentinel.conf
#sentinel monitor 被监控的名称 IP port 1
sentinel monitor myredis 127.0.0.1 6379 1
后面这个数字1代表,判断主机宕机的票数
2、启动哨兵
redis-sentinel 配置文件路径
如果主机宕机,视频截图如下,检测到主机宕机,选举了81当主机
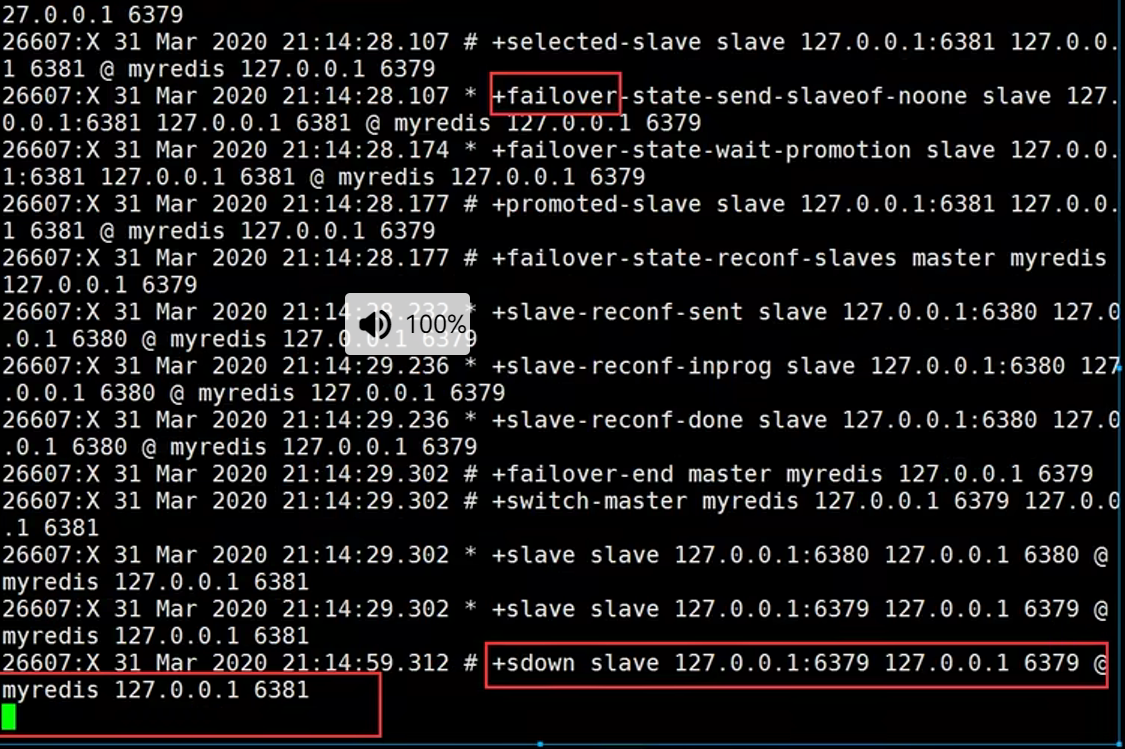
这种情况如果主机恢复了,只能归并到新主机下当从机
3、优缺点
优点:
- 哨兵集群,就是基于主从辅助,主从复制的有点它自身都带有
- 主从可以切换,故障可以转移
- 哨兵模式就是主从复制的升级版,手动到自动,更加健壮
缺点:
- redis不好在线扩容,集群容量到达上线,在线扩容非常麻烦
- 实现哨兵模式非常麻烦,里面有很多选择
4、哨兵模式的全部配置
# Example sentinel.conf
哨兵sentinel实例运行的端口 默认26379
port 26379
哨兵sentinel的工作目录
dir /tmp
哨兵sentinel监控的redis主节点的 ip port
master-name 可以自己命名的主节点名字 只能由字母A-z、数字0-9 、这三个字符".-_"组成。
quorum 当这些quorum个数sentinel哨兵认为master主节点失联 那么这时 客观上认为主节点失联了
sentinel monitor <master-name> <ip> <redis-port> <quorum>
sentinel monitor mymaster 127.0.0.1 6379 1
当在Redis实例中开启了requirepass foobared 授权密码 这样所有连接Redis实例的客户端都要提供密码
设置哨兵sentinel 连接主从的密码 注意必须为主从设置一样的验证密码
sentinel auth-pass <master-name> <password>
sentinel auth-pass mymaster MySUPER--secret-0123passw0rd
指定多少毫秒之后 主节点没有应答哨兵sentinel 此时 哨兵主观上认为主节点下线 默认30秒
sentinel down-after-milliseconds <master-name> <milliseconds>
sentinel down-after-milliseconds mymaster 30000
这个配置项指定了在发生failover主备切换时最多可以有多少个slave同时对新的master进行 同步,
这个数字越小,完成failover所需的时间就越长,
但是如果这个数字越大,就意味着越 多的slave因为replication而不可用。
可以通过将这个值设为 1 来保证每次只有一个slave 处于不能处理命令请求的状态。
sentinel parallel-syncs <master-name> <numslaves>
sentinel parallel-syncs mymaster 1
故障转移的超时时间 failover-timeout 可以用在以下这些方面:
1. 同一个sentinel对同一个master两次failover之间的间隔时间。
2. 当一个slave从一个错误的master那里同步数据开始计算时间。直到slave被纠正为向正确的master那里同步数据时。
3.当想要取消一个正在进行的failover所需要的时间。
4.当进行failover时,配置所有slaves指向新的master所需的最大时间。不过,即使过了这个超时,slaves依然会被正确配置为指向master,但是就不按parallel-syncs所配置的规则来了
默认三分钟
sentinel failover-timeout <master-name> <milliseconds>
sentinel failover-timeout mymaster 180000
SCRIPTS EXECUTION
配置当某一事件发生时所需要执行的脚本,可以通过脚本来通知管理员,例如当系统运行不正常时发邮件通知相关人员。
对于脚本的运行结果有以下规则:
若脚本执行后返回1,那么该脚本稍后将会被再次执行,重复次数目前默认为10
若脚本执行后返回2,或者比2更高的一个返回值,脚本将不会重复执行。
如果脚本在执行过程中由于收到系统中断信号被终止了,则同返回值为1时的行为相同。
一个脚本的最大执行时间为60s,如果超过这个时间,脚本将会被一个SIGKILL信号终止,之后重新执行。
通知型脚本:当sentinel有任何警告级别的事件发生时(比如说redis实例的主观失效和客观失效等等),将会去调用这个脚本,
这时这个脚本应该通过邮件,SMS等方式去通知系统管理员关于系统不正常运行的信息。调用该脚本时,将传给脚本两个参数,
一个是事件的类型,
一个是事件的描述。
如果sentinel.conf配置文件中配置了这个脚本路径,那么必须保证这个脚本存在于这个路径,并且是可执行的,否则sentinel无法正常启动成功。
通知脚本
sentinel notification-script <master-name> <script-path>
sentinel notification-script mymaster /var/redis/notify.sh
客户端重新配置主节点参数脚本
当一个master由于failover而发生改变时,这个脚本将会被调用,通知相关的客户端关于master地址已经发生改变的信息。
以下参数将会在调用脚本时传给脚本:
<master-name> <role> <state> <from-ip> <from-port> <to-ip> <to-port>
目前<state>总是“failover”,
<role>是“leader”或者“observer”中的一个。
参数 from-ip, from-port, to-ip, to-port是用来和旧的master和新的master(即旧的slave)通信的
这个脚本应该是通用的,能被多次调用,不是针对性的。
sentinel client-reconfig-script <master-name> <script-path>
sentinel client-reconfig-script mymaster /var/redis/reconfig.sh
5、缓存穿透、击穿和雪崩
5.1、缓存穿透
概念:
用户查询数据的以后,发现redis缓存里面没有对应的数据,于是向持久层数据库查询,发现也没有查到,
当用户很多的时候,请求都去了持久层数据库,给数据库造成了非常大的压力,这种现象就叫缓存穿透。
解决方案:
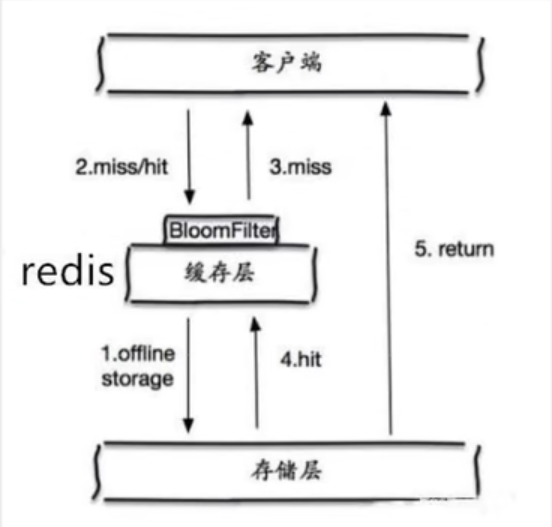
布隆过滤器:
布隆过滤器是一种数据结构,对所有可能查询的参数以hash形式存储,在控制层先进行校验,不符合则丢弃,从而避免了对底层存储系统的压力
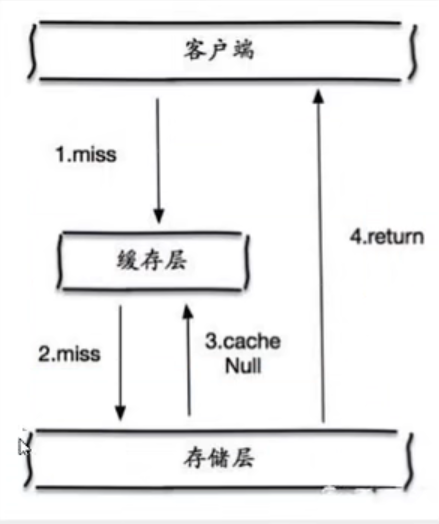
缓存空对象:
当存储层不命中后,即使返回的空对象也将其缓存起来,同时会设置一个过期时间,之后再访问这个数据将会从缓存中获取,保护了后端数据
但是这种方法存在两个问题:
1、 如果空值能够被缓存起来,意味会花费更多的内存
2、 即使对空值设置了过期时间,还是会存在缓存层和存储层的数据会有一段时间的不一致,这对需要保持一致性的业务有影响
5.2、缓存击穿
概念
缓存击穿是指一个key,扛着非常大的并发量,当这个key过期的瞬间,持续的高并发就穿破缓存,直接请求数据库,导致数据库瞬间压力过大
比如微博热搜
解决方案
-
设置热点用不过期
-
加互斥锁:使用分布式锁,保证每个key同一时间只有一个线程访问后端服务,这种方式将高并发的压力转移到了分布式锁,因此对分布锁的要求很高
5.3、缓存雪崩
概念
是指某一时间段,缓存集中过期失效,例如redis宕机
产生缓存雪崩的原因还有,例如双十二零点秒杀的时候,出现了集中的放入缓存,假设缓存了一小时,到了一点钟的时候,这些缓存全部过期,
那么针对这些商品的访问查询全部落到数据库上,数据库产生周期性的压力波峰,可能导致存储层直接挂掉
其实集中过期并不是非常的致命,因为自然形成的缓存雪崩,一定是某个时间段集中的创建缓存,这个时候数据库是可以顶住压力的。
但是服务器宕机带来的压力不可预知,很可能把服务器压垮
解决方案
redis高可用:
这个思想的含义就是,既然redis可能挂掉,那么就增设多几台redis,保证redis可以继续工作,其实就是搭建的集群
限流降级:
这个解决方案的思想是,在缓存失效后,通过加锁或者队列来控制访问数据库写缓存的线程数量。比如某一个key只允许一个线程查询数据和写缓存,其他线程等待
数据预热:
数据加热的含义就是正式部署之前,把可能访问的数据都预先访问一遍,这样就有大量的缓存存在redis当中。
在即将发生大并发访问前手动触发加载缓存不同的key,设置不用的过期时,让缓存的过期时间尽量均匀。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号