
每周总结1

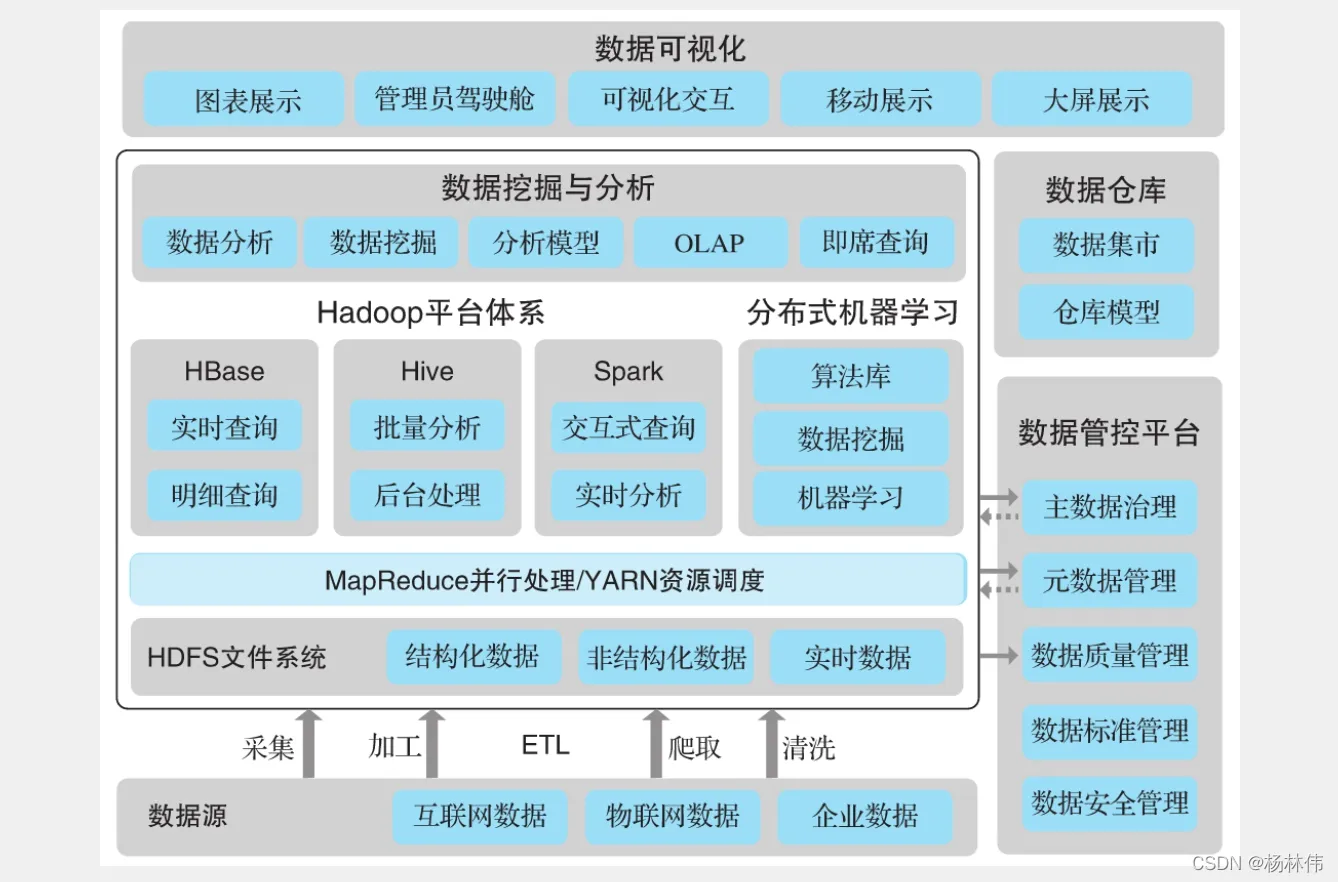
- Hadoop HDFS(核心):Hadoop 分布式存储系统;
- Yarn(核心):Hadoop 2.x版本开始才有的资源管理系统;
- MapReduce(核心):并行处理框架;
- HBase:基于HDFS的列式存储数据库,它是一种 NoSQL 数据库,非常适用于存储海量的稀疏的数据集;
- Hive:Apache Hive是一个数据仓库基础工具,它适用于处理结构化数据。它提供了简单的 sql 查询功能,可以将sql语句转换为 MapReduce任务进行运行;
- Pig:它是一种高级脚本语言。利用它不需要开发Java代码就可以写出复杂的数据处理程序;
- Flume:它可以从不同数据源高效实时的收集海量日志数据;
- Sqoop:适用于在 Hadoop 和关系数据库之间抽取数据;
- Oozie:这是一种 Java Web 系统,用于Hadoop任务的调度,例如设置任务的执行时间和执行频率等;
- Zookeeper:用于管理配置信息,命名空间。提供分布式同步和组服务;
- Mahout:可扩展的机器学习算法库。
HDFS 框架概述
① NameNode(nn): 存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块所在的 DataNode 等。
② DataNode(dn): 在本地文件系统存储文件块数据,以及块数据校验和。
③ Secondary DataNode(2nn): 用来监控 HDFS 状态的辅助后台程序,每隔一段时间获取 HDFS 元数据的快照。
———————————————
Hadoop MapReduce 是一种编程模型,它是 Hadoop 最重要的组件之一。它用于计算海量数据,并把计算任务分割成许多在集群并行计算的独立运行的 task。
MapReduce 是 Hadoop的核心,它会把计算任务移动到离数据最近的地方进行执行,因为移动大量数据是非常耗费资源的。
-
存储:Hadoop使用Hadoop Distributed File System(HDFS)来存储数据。数据被分割成多个块,并复制到集群中不同的节点上,以确保容错性和高可用性。
-
分析:Hadoop使用MapReduce编程模型来处理数据。在MapReduce中,计算任务被分成两个阶段:Map(映射)和 Reduce(归约)。Map阶段将数据分割成若干小块进行处理,Reduce阶段将Map阶段的结果合并起来以生成最终的输出。
-
资源调度:Hadoop使用YARN(Yet Another Resource Negotiator)作为资源管理器,负责集群资源的分配和调度。YARN可以根据应用程序的需求动态分配资源,并监控任务的执行情况。
-
链接:Hadoop生态系统中有许多工具和组件,如Hive、Pig、Spark等,可以与Hadoop集成,使用户能够进行更复杂的数据处理和分析工作。
总的来说,Hadoop的工作方式通过数据存储、并行计算和资源管理,实现了对大规模数据集的高效处理和分析。
hadoop主从工作方式
主节点(Master)负责整个集群的管理和协调工作,它通常负责资源的分配、任务调度、监控和故障处理。主节点还负责维护集群的元数据信息和整体的状态信息。
从节点(Slave)负责执行主节点分配给它们的任务,从节点通常负责存储数据和执行计算任务。从节点会向主节点汇报自己的状态信息,接受主节点的指令并按照指令执行任务。
虚拟机以及Hadoop 的安装耗费了我三天!!!!!!!
太难了


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义