
Greedy Algorithm
Interval Scheduling
场景
一个人有一堆事务,每个事务有开始时间和结束时间,现在需要找到一个schedule,能完成尽量多的事务,而且事务的时间段不能有重合
算法

这是一个O(nlogn)的算法
证明
假设该算法找到的Schedule S不是最优的,而存在更优的S'
假设S和S'在前r个事务上,schedule相同,在第r+1个上,S'选择了结束时间比较晚的事务
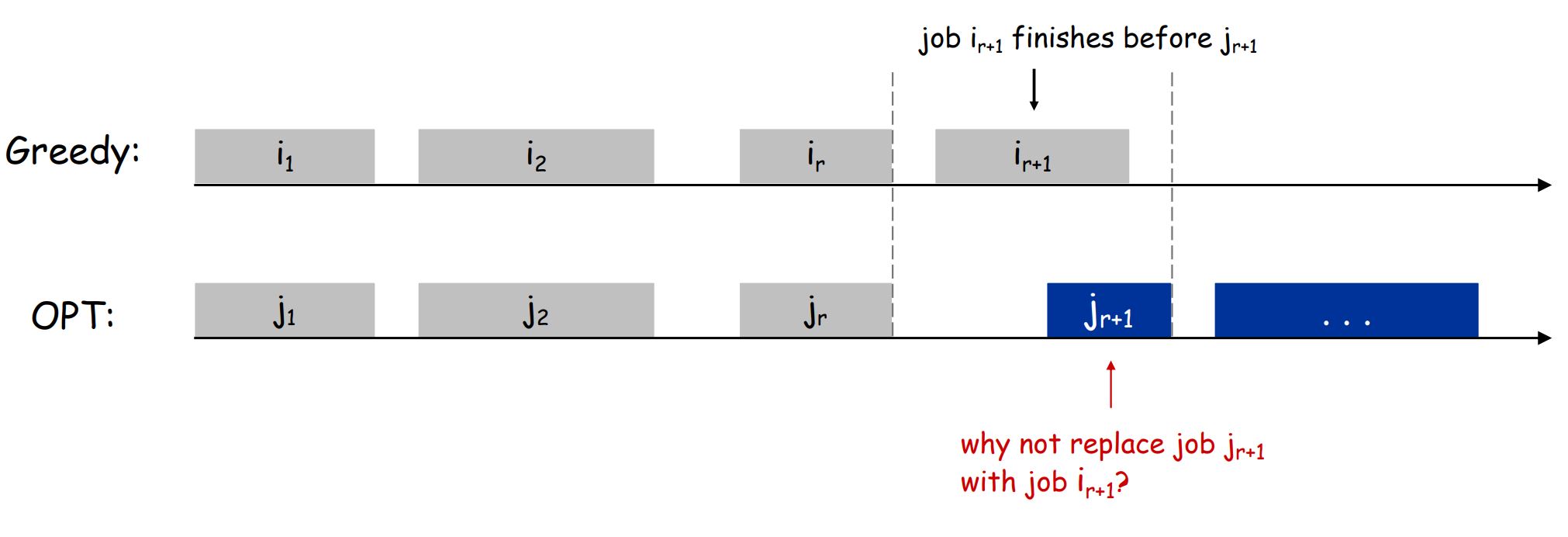
但是显而易见的是,选择较晚结束的事务没有任何好处,反而会阻碍后面的事务选择,所以S'并不会比S更优
Interval Partitioning
场景
有n节课,每节课有一个开始时间和结束时间,需要最少准备多少个教室,使得使用同一教室的课不会有时间段重合
算法
假如说在一个时间点,有d个课在同时上,我们把d叫做这个时间点的depth
比如下图中,9:30的depth是3
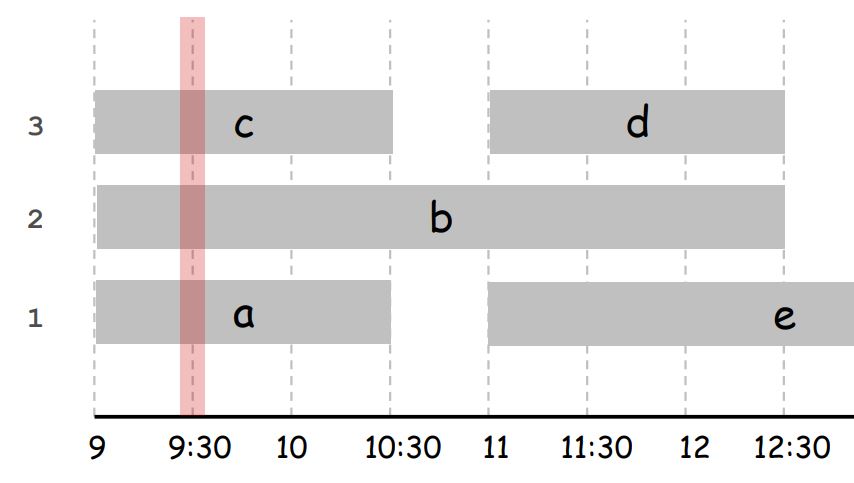
我们把整个schedule的depth记为所有时间点中最大的depth
一个显而易见而关键的观察是,interval partitioning的最优结果OPT一定大于schedule的depth
以下是一个O(nlogn)的算法

证明
算法最优性:
假如我们最后总共安排了d个教室(算法的结果),我们在为第j节课安排第d个教室时,一定存在这样的情况
前d-1个教室都在被占用,也就是存在d-1个课,他们的结束时间比第j节课的开始时间晚,也就是在一个时间点\(s_j\)(j的开始时间),\(s_j\)的depth是d,而整个schedule的depth一定大于等于d
而我们记最优的结果(最少的教室数)为OPT,OPT一定大于等于depth
我们得到了d <= depth <= OPT
所以得出OPT = d
Minimizing Lateness
场景
现在有一堆工作,每个工作有一个花费的时间和一个due time
每个时间只能做一个工作,每个工作的lateness就是该工作做完的时间-他的due time
我们想要找到能使得,所有工作中最大的Latenss,最小的schedule
算法
根据工作花费的时间或者工作的slack time(due time - time cost)来做贪心都是不可行的
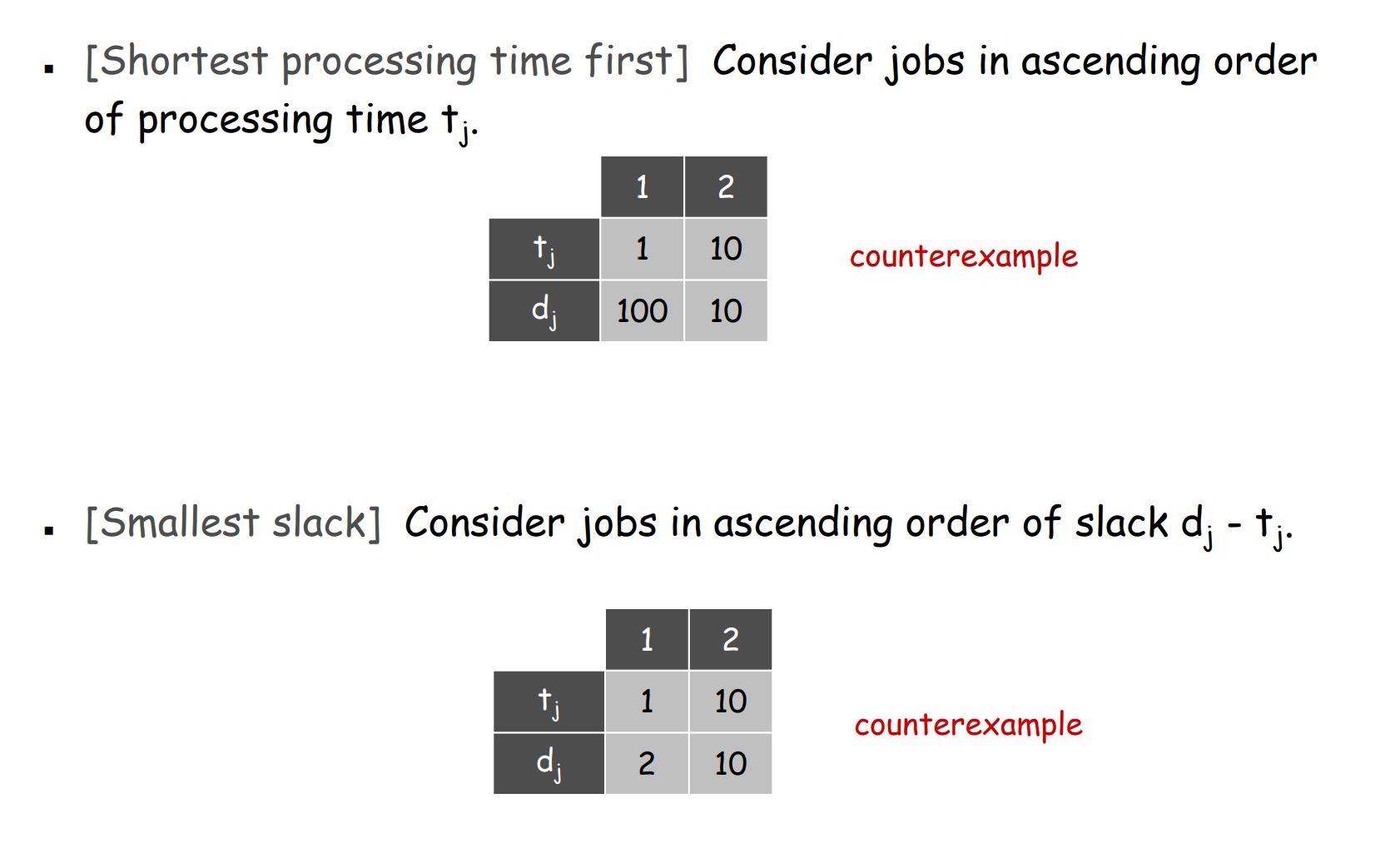
我们选择根据工作的due time来做贪心

显而易见工作的安排之间不应该有空闲时间
证明
我们把schedule中,工作i的due time < 工作j的due time,但j排在i前面的这样一对工作,叫做inversion
上述算法中找到的schedule是不存在inversion的
我们要证明除掉一对inversion,可以使得max lateness不变或减小


记上述算法找到的Schedule为 S
假设存在一个最优schedule OPT,OPT一定能通过除去inversion转换成S,而且不会增加max lateness,所以S是最优解
Optimal Caching
Cache上主要有两个考虑,一个是什么时候把数据搬入Cache,一个是把什么数据踢出Cache
什么时候把数据踢出Cache是显而易见的:在Cache空间不足的时候再踢
搬入数据的时机
如果采用的策略是,在数据被需要时,再放入Cache,而不是提前放入
我们把采用了这种策略的schedule叫做reduced schedule
我们可以证明reduced schedule的cache miss小于等于unreduced schedule的cache miss
S是unreduced schedule,S'是reduced schedule
假设在t'时,我们需要某个暂时不确定的数据
假设S猜测在t'时需要的是数据d,他在t时刻就把d放入
那么分为两种结果,case1是t'时刻需要的并不是d,case2是t'时刻需要的就是d
可以从下图中看到,S的猜测并没有好处,而且在猜错时还增加了一次数据的搬移
S可以转换成reduced的S',并且不会增加Cache miss次数
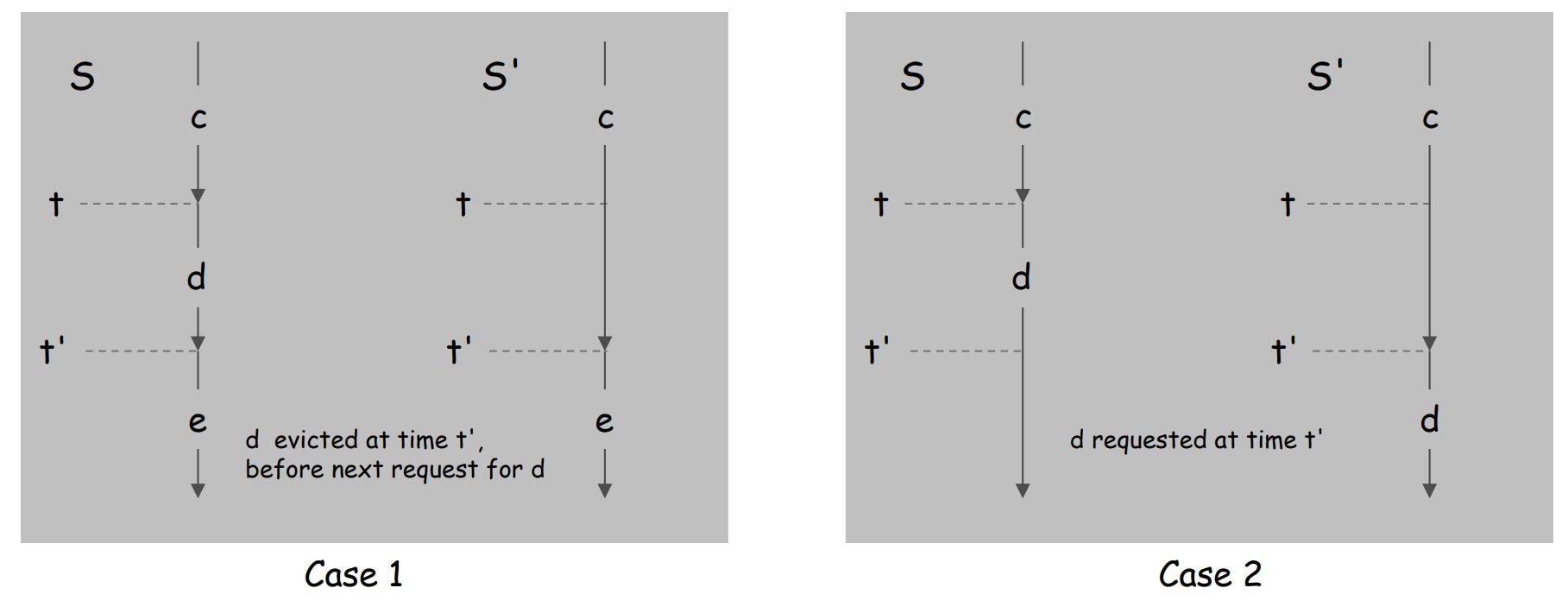
所以reduced schedule会是我们采用的策略
踢出数据的选择
当Cache满了的时候,需要踢出数据
在离线情况下,我们可以知道未来数据请求的序列
在这种情况下,采用farthest in the future会是最好的策略
farthest in the future(FF): 把未来最晚才需要的数据踢出
证明思想是数学归纳法,假设FF得到的schedule和最优的schedule在前j步结果相同,证明在第j+1步也会相同
具体证明讨论繁多,此处省略,可在网上搜索
Dijkstra
Dijkstra是解决单起点的,正边权的,最短路问题算法
算法
用一个集合S,代表已经到过了的节点(已确定最短路径长)的集合
记录从起点到所有节点的距离,比如从起点到节点x的距离记为dist(x)
初始情况下,S为空集,dist(起点)为0,其他节点为无穷大
每次选取dist最小的节点\(v\),加入集合S,
然后用\(v\)遍历并更新它相邻且不在S中的节点的dist
假设\(v\)相邻的节点中\(v'\)不在S中,那么如果dist(v') > dist(v) + edge(v, v'),就要更新dist(v')为dist(v) + edge(v, v')
重复以上步骤,直到所有节点都在S中
证明
Minimum Spanning Tree
我们想要在一个图中,找到一个连通的子图,且边权之和最小,我们把该子图叫做Minimum Spanning Tree (MST)
两个重要的结论
- Cut Property
对于图中任意一个节点子集S,我们称为Cut,如果存在一条边\(e\),e有且只有一端在S中,那么一定存在一个MST包含\(e\) - Cycle Property
对于图中任意一个环,环中最长的边一定不存在于任意一个MST中
有两个找到MST的算法
Prim's Algorithm
有一个节点的集合V,代表已经被我们选入MST的节点,我们需要记录从V到任意一个节点的距离
初始V为空集,把任意一个节点x加入V,然后更新与x相邻的节点的距离(从V到该节点的距离)
根据Cut Property, 选取距离最短的\(e\),\(e\)有且只有一端在V中,加入MST。然后把\(e\)的不在V中的端点y加入V,更新y相邻节点的距离。重复该步骤直到得到MST
Kruskal Algorithm
排序所有的边,
每次找到最短的边,加入MST,如果导致MST有环,则去掉该边(Cycle Property)
遍历完所有的边即可
Clustering
我们可以将一个Connected Component称为一个cluster
将n个离散的节点,通过在他们之间连边,连接成k个cluster,就叫做k-clustering
两个cluster之间最近的距离,就叫做他们的space
要找到k-clustering for max space,也就是使得space之和最大
我们可以采用Kruskal的算法
一开始节点之间都是离散的,有n个cluster
Kruskal中每连一条边(不会出现cycle),就会减少一个cluster
那我们用Kruskal的算法,连接n-k条边,最后就会得到k-clustering for max space
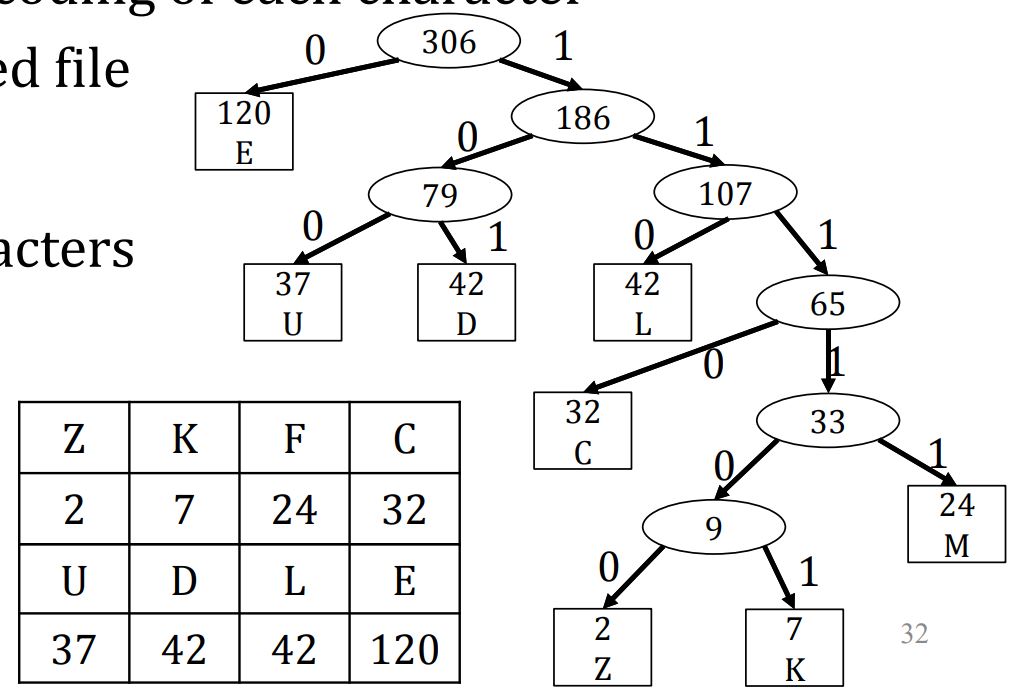
Huffman Coding
想要创造一套对对字符进行01编码的系统时
使用变长的编码更能节省空间
但是要避免以下的情况
A的编码是01,B的编码是0111,C的编码是11
那对于01序列,0111,我们并不知道应该如何解释
也就是需要避免编码x是编码y的前缀
我们用Average bits per letter来衡量一套编码系统的优劣
\(f_x\)是字符出现的频率(\(0<=f_x<=1\))
\(c(x)\)是字符需要的bits位数
S就是字符的集合

Huffman Coding就提供了一个解决了前缀问题,而且找到的编码系统ABL最小的算法

一个Huffman Coding的例子

 浙公网安备 33010602011771号
浙公网安备 33010602011771号