
wcs
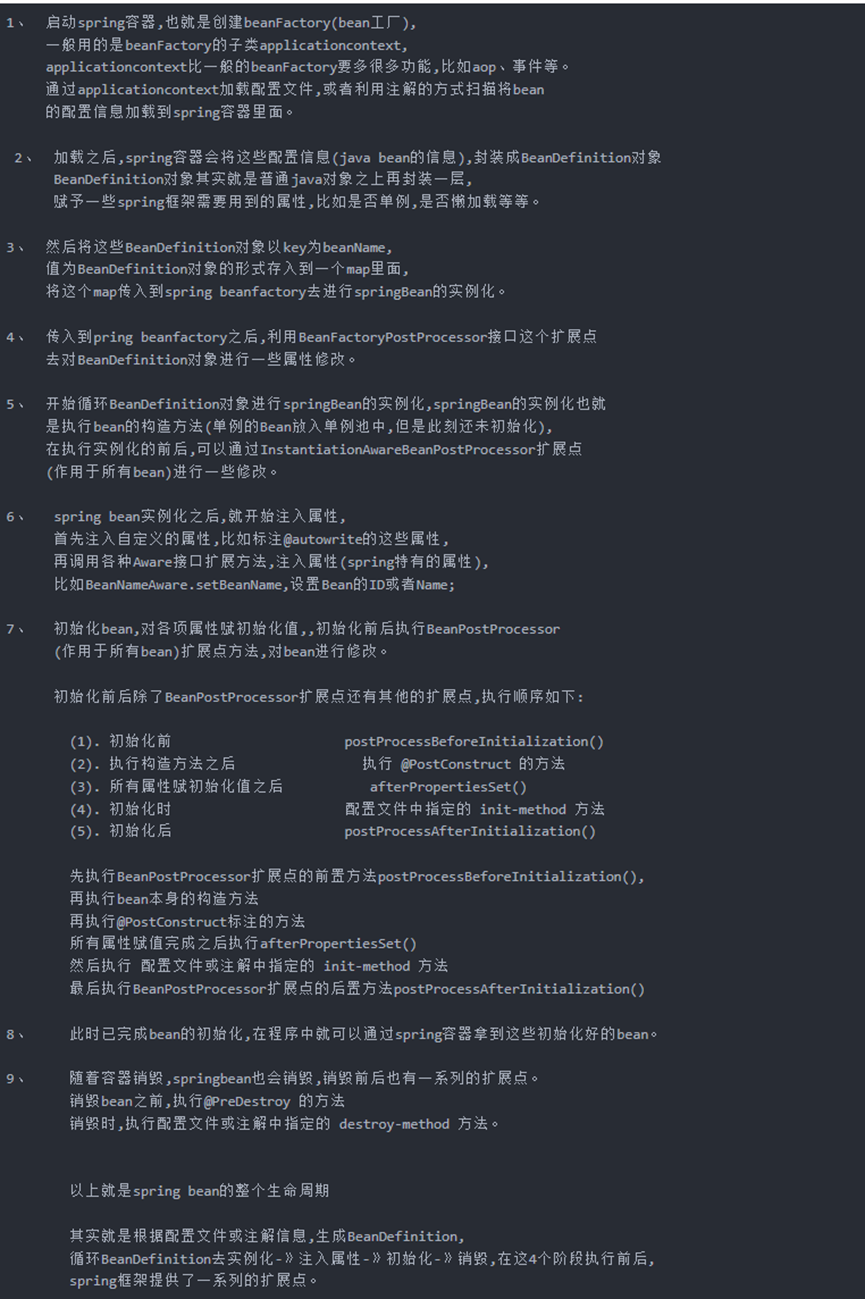
springboot 启动流程
1:实例化SpringApplication 对象
1.1调用initiallize方法,读取两个包的spring.factories。目的给SpringApplication设置初始的监听器和初始化器;

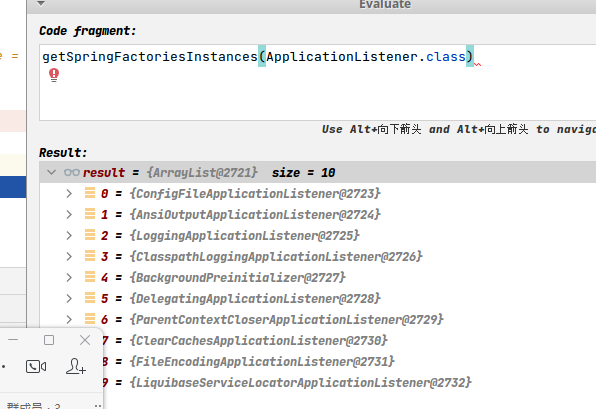
2:调用Application.run()
2.1:调用getRunListeners()
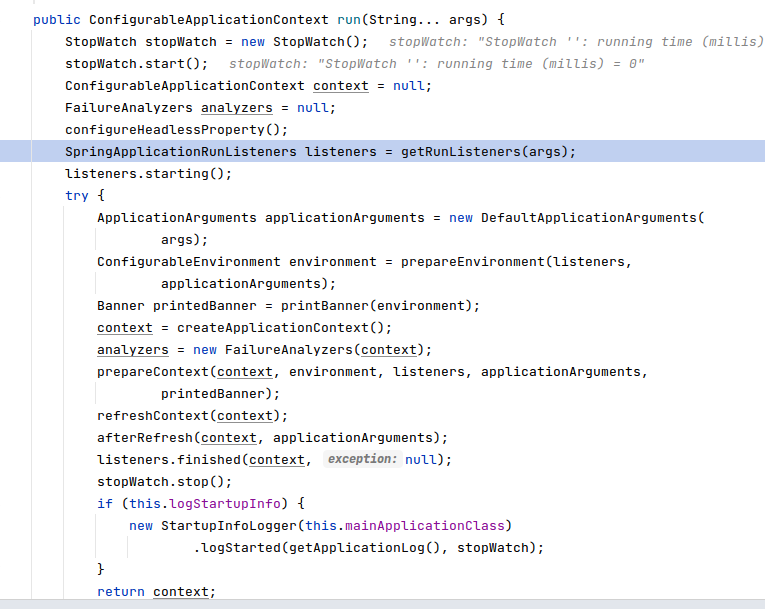
getRunListeners()读取spring.factories实例化EventPublishingRunListener ,包含广播器和Application对象;
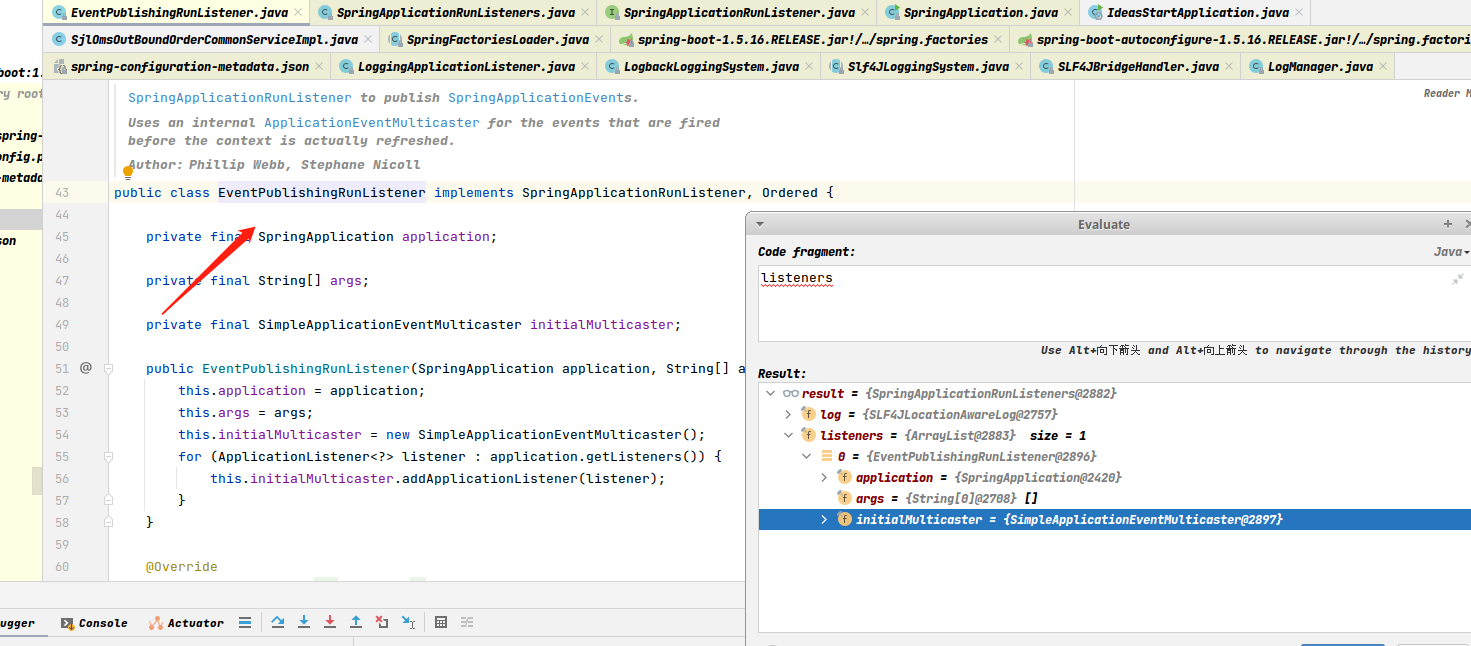
2.2:调用listeners.start();
java8
便于并行计算
lamda更符合阅读习惯
代码少(由于增加了Lambda表达式)
集成Stream API
1.8 HashMap put流程
1、计算key的hash值(高低位异或)
2、判断数组是否为空,如果数组为空 则直接扩容
3、如果数组非空 则 根据hash值计算数组下标(n-1)& hash,根据下标取数组对应值,如果值为空则新建一个node,非空则转为下一步
4、key的hash 和 equals与 下标数组的值都相同,则直接覆盖;
5、如果不相同则 判断下标数组的值 是否 红黑树实例,是红黑树的话 新节点直接加入红黑树中
6、不是红黑树实例就是链表,循环遍历链表,并判断是否为已有节点如果有则直接返回,如果没有 则将新节点放到链表尾部,如果新链表大小超过 阈值(8-1)即>= 7,将链表转为红黑树
7、key存储完毕之后,并判断 hashMap大小是否超阈值(上次map大小的2的次数),如果超过 则直接扩容,否则 put流程结束
ConcurrentHashMap cas(空节点) synchronized(存在节点)
Channels
Buffers
Selectors 1 -> Channels n
Mysql
1:内存页16kb,单行尽量数据小。
2: b+树一个节点16kb,能存储1170左右的指针 二层1170 三层1170*1170个16kb的内存页,一条数据是1kb的话。可以存储2000w条数据
3:mysql没有枚举,可使用tinyint的0,1去区分男女
4:聚簇索引,select * 无法使用覆盖,辅助索引。
5:数据量增长,分区(日期,id)1020个最大的分区。垂直查分,单表变多表(表查询需要考虑)。
分区,垂直拆分(单台服务器)后还无法满足,水平拆分:如订单一天2000w,存储2个服务器,用如一致性hash。注意划分key,避免单个sql查询多张表。
6:冷热备份,可以将无用数据备份。
重做日志(redo log)
重做日志(redo log)的作用是确保事务的持久性,防止在发生故障的时间点,尚有脏页未写入磁盘。在重启 MySQL 服务的时候,根据 redo log 进行重做,从而达到事务的持久性这一特性。
回滚日志(undo log)
保存了事务发生之前的数据的一个版本,可以用于回滚,同时可以提供多版本并发控制下的读(MVCC),也即非锁定读。
二进制日志(binlog)
用于复制,在主从复制中,从库利用主库上的 binlog 进行重播,实现主从同步;用于数据库基于时间点的还原。
错误日志(errorlog)
慢查询日志(slow query log)
一般查询日志(general log)
中继日志(relay log)
Snl简单的被驱动表会扫描多次
Inl 需要回表,随机io
Bnl 缓存主表 一次拿多条主表数据与被驱动表比较,比较次数一样,但减少了从表的扫描次数,存在随机io问题
Mrr 对id进行排序,顺序读 默认开启
Bka index 的升级版,整合bnl和mrr
jvm
.class文件的结构
Javac 编译.Java成.class。jvm能识别的二进制文件
类加载流程:加载,链接,初始化。链接分为验证,准备,解析,
(1)验证阶段。主要的目的是确保被加载的类(.class文件的字节流)满足Java虚拟机规范,不会造成安全错误
(2)准备阶段。负责为类的静态成员分配内存,并设置默认初始值。
(3)解析阶段。将类的二进制数据中的符号引用替换为直接引用。
正确的应该是:
1:java->class。
2:链接里验证:验证文件格式,class的文件结构。
3:加载把class装换成方法区的结构
4:加载内存生成类对象作为方法区的访问入口
5:链接里验证字节码
6:准备 初始化0值等
7:解析 符号引用验证
9:初始化
垃圾回收流程
可达性分析:不可达,从gcRoot遍历。三色标记的算法。被GC roots引用的对象不被GC回收
a.虚拟机栈(栈桢中的本地变量表)中的引用的对象
b.方法区中的类静态属性引用的对象
c.方法区中的常量引用的对象
d.本地方法栈中JNI的引用的对象,jvm内部的
e.锁对象的持有和释放
Young GC Old GC fullgc
cms 用的是标记清理
GC roots是啥:堆外指向堆内的引用
初始标记 标记gcroot,并发标记递归标记,变动的对象标记为Direty ,重新标记 处理direty ,清理,重置。

Jvm调优心得


Minor gc (新生代)频繁(并发大)0,增大eden取得大小(不会造成停顿时间过长),降低频率。实际测试。
如果每次Minor gc频繁容易引发fullGc,存活对象大小是否小于s1,如果大于就会造成频繁fullGc。适当调整s1的大小。
频繁创建大对象,大对象大于阈值会直接进入老年代。解决方式是进行代码拆分,改大对象为小对象。调整阈值。
长时间停顿,gc真实过程;真实过程不长,线程要到达安全点才能gc。
内存泄漏oom。线程没有remove,网络链接,io,数据库链接没有释放资源,静态变量使用完后null
并发编程
Lock 更灵活,显示加锁。避免形成死锁。超时时间。
Cas 轻量级锁,减少锁的状态,使用不当会造成cpu的消耗。
Aqs 用的模板方法模式,用户可以自己实现。有公平锁和非公平锁。
公平锁:多个线程按照申请锁的顺序去获得锁,线程会直接进入队列去排队,永远都是队列的第一位才能得到锁。
优点:所有的线程都能得到资源,不会饿死在队列中。
缺点:吞吐量会下降很多,队列里面除了第一个线程,其他的线程都会阻塞,cpu唤醒阻塞线程的开销会很大。
非公平锁:多个线程去获取锁的时候,会直接去尝试获取,获取不到,再去进入等待队列,如果能获取到,就直接获取到锁。
提高单节点的并发>单个接口。
分布式是最终方案。接口无状态。代码异步多线程。Db查询速度,调优,缓存。第三方调用时用多线程。带宽用stream流。引入消息队列,拆分数据。缓存用redis会有额外的开销。
Sychnozided
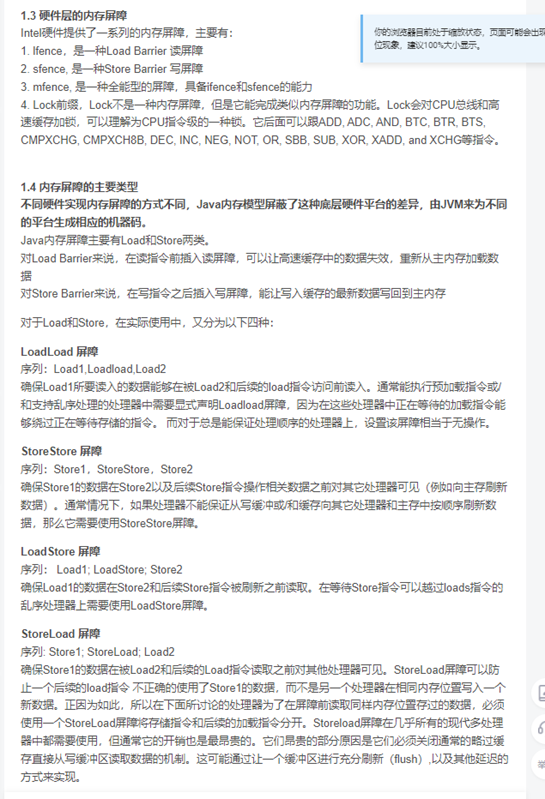
Volitail 保证可见性。重排序(内存屏障)
- Store:将处理器缓存的数据刷新到内存中。
- Load:将内存存储的数据拷贝到处理器的缓存中。
线程池,饱和策略,最大线程数(队列满了,创建的线程数小于最大线程数,可创建新的),核心的size。饱和策略:
1抛异常会附带执行信息。存到数据库,根据业务处理
2:丢弃(默认)
3:调用者线程执行
4:丢弃队列里最近的一个任务,并执行当前提交的任务。
Redis 为什么快:内存v>磁盘v 采用的netty 单(多)线程放映器模型
单个线程轮询客户端
快照和aop速度和文件大小相关。
内存淘汰数据:保证都是热点数据
最少使用,临近过期,随机,返回错误,最近未使用
而在 Redis 中,一个指针是占了 8 个字节
1:(默认开启)对压缩列表(能更大的存储)的配置修改,一个指针6字节共计20,开启后本身加上2字节。默认为小于512条(每一个元素的大小小于64字节)。调整2000左右。
2:代码减少key的大小,拆分长列表
3:分片思想分长列表。
4:把数据打包成二进制位存储,需要程序支撑。
高可用
- 合理的负载均衡,隔离,限流。降级,代码加重试机制
- 三层限流 negix,redis分布式单个ip,用户。令牌桶,3,重要接口限流
跳表:nlgn、
redis雪崩是指redis在某个时间大量失效,设置超时时间的时候要设置随机
缓存穿透是指缓存和数据库中都没有的数据、缓存空
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期)
设置热点数据永不过期
加互斥锁
淘汰策略:
1. noeviction:当内存使用超过配置的时候会返回错误,不会驱逐任何键
2. allkeys-lru:加入键的时候,如果过限,首先通过LRU算法驱逐最久没有使用的键
3. volatile-lru:加入键的时候如果过限,首先从设置了过期时间的键集合中驱逐最久没有使用的键
4. allkeys-random:加入键的时候如果过限,从所有key随机删除
5. volatile-random:加入键的时候如果过限,从过期键的集合中随机驱逐
6. volatile-ttl:从配置了过期时间的键中驱逐马上就要过期的键
7. volatile-lfu:从所有配置了过期时间的键中驱逐使用频率最少的键
8. allkeys-lfu:从所有键中驱逐使用频率最少的键
编码风格
原型模式(Prototype Pattern)是用于创建重复的对象,同时又能保证性能。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。
这种模式是实现了一个原型接口,该接口用于创建当前对象的克隆。当直接创建对象的代价比较大时,则采用这种模式。例如,一个对象需要在一个高代价的数据库操作之后被创建。我们可以缓存该对象,在下一个请求时返回它的克隆,在需要的时候更新数据库,以此来减少数据库调用。直接在内存里用拷贝二进制流的方式创建对象。
发短信,不用大量new对象。
模板方法,比较透明
高并发
长时间的维持瞬时并发量
提高单节点的并发量
分布式是最后考虑
代码(异步),db数据库调优缓存。第三方服务的调用时间(多线程调用)。Json占用的内存较大。无状态接口。消息队列。
分布式节点的缓存 redis会有网络开销。
结合前端和redis缓存。手动触发,消息通知前端刷新缓存。
Nacos 中提供了两种健康检查机制:临时实例的客户端主动上报机制和永久实例的服务端反向探测机制。临时实例每隔 5s 发送一个心跳包给 Nacos 服务器端,服务器端接收到心跳包之后再将健康状况同步给其他注册中心。永久实例支持 3 种探测协议,TCP、HTTP 和 MySQL,默认探测协议为 TCP,也就是通过不断 ping 的方式来判断实例是否健康
@AutoConfigurationPackage负责加载启动类路径下的@Configuration修饰的类
@Import({AutoConfigurationImportSelector.class})负责加载所有依赖包中META-INF/spring-factories里定义的EnableAutoConfiguration这个key中的类
AnnotationConfigApplicationContext
EnableAutoConfiguration
@Import 注解是由 Spring 提供的,作用是将某个类实例化并加入到 Spring IoC 容器中


 浙公网安备 33010602011771号
浙公网安备 33010602011771号