
《程序是怎样跑起来的》第六章——尝试亲自压缩数据
回答章前问题:
1、字节,一字节等于八位
2、DOC和TXT肯定不是,DOC是word文档的后缀,TXT是文本文件的后缀。答案是LZH。(压缩文件扩展名)
3、? 注:不会,问题:数据的值*循环次数 来表示的压缩方法是RLE算法还是哈夫曼算法? (什么是RLE算法?哈夫曼算法?)
4、 一个半角英数为一字节。 注:SHIFT JIS字符编码是什么?
5、BMP格式图像文件没有压缩过
6、可逆压缩和非可逆压缩,为字面意思。前者数据可恢复,后者不可。
解析:
3、RLE算法。RLE(Run-Length Encoding)算法是一种简单的无损数据压缩算法,用于压缩连续重复出现的数据。
RLE 算法的基本思想是将连续重复出现的字符或数据序列替换为一个计数值和对应的字符或数据。具体来说,RLE 算法遍历输入数据,统计连续相同的字符或数据的个数,并将计数值与对应的字符或数据一起记录下来。
例子:AAAABBBCCDAA RLE压缩后——> 4A3B2C1D2A
哈夫曼算法:哈夫曼编码(Huffman Coding)是一种基于字符出现频率的无损数据压缩算法。它通过使用不同长度的编码来表示不同字符,从而实现对数据进行高效压缩的目的。
哈夫曼编码的基本思想是,对于出现频率较高的字符,分配较短的编码;而对于出现频率较低的字符,分配较长的编码。这样可以确保整体编码长度的平均值最小,从而实现对数据的高效压缩。
- 统计输入数据中每个字符出现的频率。
- 根据字符频率构建哈夫曼树(Huffman Tree),其中频率较低的字符在树的较深位置,频率较高的字符在树的较浅位置。
- 通过遍历哈夫曼树,为每个字符赋予对应的哈夫曼编码,确保没有编码是另一个编码的前缀(即具有前缀码)。
- 使用所生成的哈夫曼编码对输入数据进行编码,并将编码后的数据保存或传输。
4、SHIFT JIS(Shift Japanese Industrial Standards)是一种用于编码日文字符的字符编码标准。
在压缩数据之前我们要知道数据在计算机中保存在文件中的数据形式,文件是存储数据到磁盘的一种形式,程序文件中数据的单位是字节,文件就是字节数据的集合,用二进制来表示的话就是00000000~11111111.若存储的是纯文字,就是文本文件。若存储的的是图片就是图像文件。在任何情况下,文件中的字节都是连续存储的。
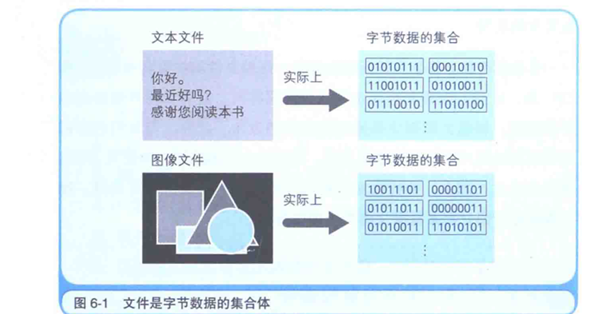
文件有多种压缩机制:如RLE算法,在章前题中就有解析,举个例子:AAAAABBBBCCDDDDD这样一串数据。通过RLE压缩,就是数据*重复次数。
就压缩成了A5B4C2D5,页就压缩了原来的16字节变成了压缩后的8字节。这种“数据*重复次数”的压缩算法就称为RLE算法。RLE算法虽然在图像,文件的压缩中有不错的表现,但在压缩文本文件中却并不适合。因为文本文件中连续出现同样字符的情况很低。
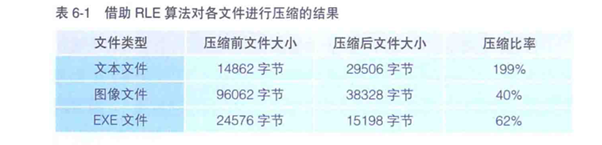
如图,RLE算法在压缩文本文件时文件大小反而还极大的增加了。
但正如一开始就说的,压缩技巧有很多种,第二个要介绍的就是哈夫曼算法。正常来说,半角英文数字的一个字符为一个字节,带哈夫曼算法抛却了这一点,在文本文件中,字符的出现不是连续的,数量也不是固定的,哈夫曼算法用多次出现的数据用小于八位的字节数来表示,不常用的数据可以用超过八位的字节数来表示。若A出现100次,Z出现5次,如果都用八位来表示的话,就是(100*8)+(5*8)=840,而利用哈夫曼算法,A用2位来表示,Z用10表示,压缩后仅为240位。(注:计算机以八位一字节的方式存储,不管满没有满八位,最终都要以八位为单位存储在文件中,过程虽复杂,但压缩率的回报很高。)另外,哈夫曼算法的压缩位数并不能随意指定,它是根据字符出现的频率动态分配不同长度的编码,使得整体的编码长度更短,从而实现数据压缩。
哈夫曼算法压缩后的文件分为两部分,一部分是哈夫曼编码的信息(类似文件头),另一部分是压缩后的数据。
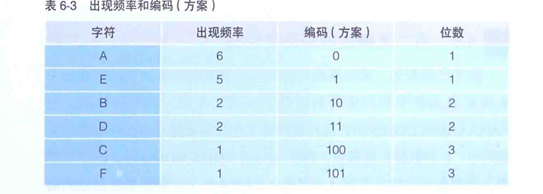
如图通过对文件字符的编码,制作出了这样一个文件,出现次数越多的字符,位数越小,这就是哈夫曼树。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号