

高斯混合模型
笔者最近在计算机视觉课程里接触到了高斯混合模型(Gaussian Mixture Model),遂写一篇笔记来整理记录相关知识点,分享给大家。欢迎讨论、指正!
混合模型(Mixture Model)
混合模型是一个可以用来表示在总体分布(distribution)中含有 K 个子分布的概率模型,换句话说,混合模型表示了观测数据在总体中的概率分布,它是一个由 K 个子分布组成的混合分布。混合模型不要求观测数据提供关于子分布的信息,来计算观测数据在总体分布中的概率。
高斯模型
单高斯模型
当样本数据 X 是一维数据(Univariate)时,高斯分布遵从下方概率密度函数(Probability Density Function):
其中\(\mu\)为数据均值(期望), \(\delta\) 为数据准差(Standard deviation)。
当样本数据 \(X\) 是多维数据(Multivariate)时,高斯分布遵从下方概率密度函数:
其中,\(\mu\) 为数据均值(期望), \(\Sigma\) 为协方差(Covariance),\(D\)为数据维度。
高斯混合模型
高斯混合模型可以看作是由 \(K\) 个单高斯模型组合而成的模型,这 $K $个子模型是混合模型的隐变量(Hidden variable)。一般来说,一个混合模型可以使用任何概率分布,这里使用高斯混合模型是因为高斯分布具备很好的数学性质以及良好的计算性能。
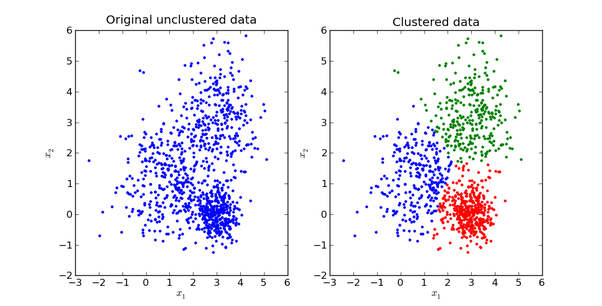
举个不是特别稳妥的例子,比如我们现在有一组狗的样本数据,不同种类的狗,体型、颜色、长相各不相同,但都属于狗这个种类,此时单高斯模型可能不能很好的来描述这个分布,因为样本数据分布并不是一个单一的椭圆,所以用混合高斯分布可以更好的描述这个问题,如下图所示:
首先定义如下信息:
- \(x_j\)表示第 \(j\) 个观测数据,\(j=1,2,\cdots,N\)
- \(k\) 是混合模型中子高斯模型的数量, \(k=1,2,\cdots,K\)
- \(\alpha_k\) 是观测数据属于第\(k\) 个子模型的概率,\(\alpha_k \geq 0,\sum_{k=1}^K\alpha_k =1\)
- \(\phi(x|\theta_k)\) 是第 \(k\)个子模型的高斯分布密度函数,\(\theta_k=(\mu_k,\delta_k^2)\) 。其展开形式与上面介绍的单高斯模型相同
- \(\gamma_{jk}\) 表示第 \(j\)个观测数据属于第\(k\)个子模型的概率
高斯混合模型的概率分布为:
对于这个模型而言,参数\(\theta = (\widetilde{\mu}_k,\widetilde\delta_k,\widetilde\alpha_k)\),也就是每个子模型的期望、方差(或协方差)、在混合模型中发生的概率。
模型参数学习
对于单高斯模型,我们可以用最大似然法(Maximum likelihood)估算参数\(\theta\) 的值,
这里我们假设了每个数据点都是独立的(Independent),似然函数由概率密度函数(PDF)给出:
由于每个点发生的概率都很小,乘积会变得极其小,不利于计算和观察,因此通常我们用 Maximum Log-Likelihood 来计算(因为 Log 函数具备单调性,不会改变极值的位置,同时在 0-1 之间输入值很小的变化可以引起输出值相对较大的变动):
对于高斯混合模型,Log-Likelihood 函数是:
如何计算高斯混合模型的参数呢?这里我们无法像单高斯模型那样使用最大似然法来求导求得使 likelihood 最大的参数,因为对于每个观测数据点来说,事先并不知道它是属于哪个子分布的(hidden variable),因此 log 里面还有求和,对于每个子模型都有未知的\(\alpha_k,\mu_k,\delta_k\),直接求导无法计算。需要通过迭代的方法求解。
EM 算法
EM 算法是一种迭代算法,1977 年由 Dempster 等人总结提出,用于含有隐变量(Hidden variable)的概率模型参数的最大似然估计。
每次迭代包含两个步骤:
- E-step:求期望\(E(\gamma_{jk}|X,\theta),j=1,2,\cdots,N\)
- M-step:求极大,计算新一轮迭代的模型参数
这里不具体介绍一般性的 EM 算法(通过 Jensen 不等式得出似然函数的下界 Lower bound,通过极大化下界做到极大化似然函数),只介绍怎么在高斯混合模型里应用从来推算出模型参数。
通过 EM 迭代更新高斯混合模型参数的方法(我们有样本数据 \(x_1,x_2,\cdots,x_N\)和一个有\(k\)个子模型的高斯混合模型,想要推算出这个高斯混合模型的最佳参数):
-
首先初始化参数
-
E-step:依据当前参数,计算每个数据\(j\) 来自子模型\(k\) 的可能性
\[\gamma_{jk} = \frac{\alpha_k\phi(x_j|\theta_k)}{\sum_{k=1}^{K}\alpha_k\phi(x_j|\theta_k)},j=1,2,\cdots,N;k=1,2,\cdots,K \]M-step:计算新一轮迭代的模型参数
\[\mu_k = \frac{\sum_{j}^N(\gamma_{jk}x_j)}{\sum_j^N\gamma_{jk}},k=1,2,\cdots,K \]\[\delta_K = \frac{\sum_j^N\gamma_{jk}(x_j-\mu_k)(x_j-\mu_k)^T}{\sum_j^N\gamma_{jk}},k=1,2,\cdots,K \]\[\alpha_k = \frac{\sum_{j=1}^N\gamma_{jk}}{N},k=1,2,\cdots,K \] -
重复计算 E-step 和 M-step 直至收敛 :
\[||\theta_{i+1}-\theta_i|| < \epsilon \]\(\epsilon\) 是一个很小的正数,表示经过一次迭代之后参数变化非常小。
至此,我们就找到了高斯混合模型的参数。需要注意的是,EM 算法具备收敛性,但并不保证找到全局最大值,有可能找到局部最大值。解决方法是初始化几次不同的参数进行迭代,取结果最好的那次。
转载地址:高斯混合模型
Reference
- 《统计学习方法》第九章 - EM 算法及其推广——李航
- Mixture model - Wikipedia
- 高斯混合模型(GMM)介绍以及学习笔记

 浙公网安备 33010602011771号
浙公网安备 33010602011771号