

Apache Calcite 学习 (一)
关于 Apache Calcite 的简单介绍可以参考 Apache Calcite:Hadoop 中新型大数据查询引擎 这篇文章,Calcite 一开始设计的目标就是 one size fits all,它希望能为不同计算存储引擎提供统一的 SQL 查询引擎,当然 Calcite 并不仅仅是一个简单的 SQL 查询引擎,在论文 Apache Calcite: A Foundational Framework for Optimized Query Processing Over Heterogeneous Data Sources 的摘要(摘要见下面)部分,关于 Calcite 的核心点有简单的介绍,Calcite 的架构有三个特点:flexible, embeddable, and extensible,就是灵活性、组件可插拔、可扩展,它的 SQL Parser 层、Optimizer 层等都可以单独使用,这也是 Calcite 受总多开源框架欢迎的原因之一。
Apache Calcite is a foundational software framework that provides query processing, optimization, and query language support to many popular open-source data processing systems such as Apache Hive, Apache Storm, Apache Flink, Druid, and MapD. Calcite’s architecture consists of
- a modular and extensible query optimizer with hundreds of built-in optimization rules,
- a query processor capable of processing a variety of query languages,
- an adapter architecture designed for extensibility,
- and support for heterogeneous data models and stores (relational, semi-structured, streaming, and geospatial).
This flexible, embeddable, and extensible architecture is what makes Calcite an attractive choice for adoption in bigdata frameworks. It is an active project that continues to introduce support for the new types of data sources, query languages, and approaches to query processing and optimization.
Calcite 概念
在介绍 Calcite 架构之前,先来看下与 Calcite 相关的基础性内容。
关系代数的基本知识
关系代数是关系型数据库操作的理论基础,关系代数支持并、差、笛卡尔积、投影和选择等基本运算。关系代数也是 Calcite 的核心,任何一个查询都可以表示成由关系运算符组成的树。在 Calcite 中,它会先将 SQL 转换成关系表达式(relational expression),然后通过规则匹配(rules match)进行相应的优化,优化会有一个成本(cost)模型为参考。
这里先看下关系代数相关内容,这对于理解 Calcite 很有帮助,特别是 Calcite Optimizer 这块的内容,关系代数的基础可以参考这篇文章SQL 形式化语言——关系代数,简单总结如下:
| 名称 | 英文 | 符号 | 说明 |
|---|---|---|---|
| 选择 | select | σ | 类似于 SQL 中的 where |
| 投影 | project | Π | 类似于 SQL 中的 select |
| 并 | union | ∪ | 类似于 SQL 中的 union |
| 集合差 | set-difference | - | SQL中没有对应的操作符 |
| 笛卡儿积 | Cartesian-product | × | 类似于 SQL 中不带 on 条件的 inner join |
| 重命名 | rename | ρ | 类似于 SQL 中的 as |
| 集合交 | intersection | ∩ | SQL中没有对应的操作符 |
| 自然连接 | natural join | ⋈ | 类似于 SQL 中的 inner join |
| 赋值 | assignment | ← |
查询优化
查询优化主要是围绕着 等价交换 的原则做相应的转换,这部分可以参考【《数据库系统概念(中文第六版)》第13章——查询优化】,关于查询优化理论知识,这里就不再详述,列出一些个人不错不错的博客,大家可以参考一下:
- 数据库查询优化入门: 代数与物理优化基础;
- 高级数据库十五:查询优化器(一);
- 高级数据库十六:查询优化器(二);
- 「 数据库原理 」查询优化(关系代数表达式优化);
- 4.1.3 关系数据库系统的查询优化(1);
- 4.1.3 关系数据库系统的查询优化(10);
Calcite 中的一些概念
Calcite 抛出的概念非常多,笔者最开始在看代码时就被这些概念绕得云里雾里,这时候先从代码的细节里跳出来,先把这些概念理清楚、归归类后再去看代码,思路就清晰很多,因此,在介绍 Calcite 整体实现前,先把这些概念梳理一下,需要对这些概念有个基本的理解,相关的概念如下图所示:
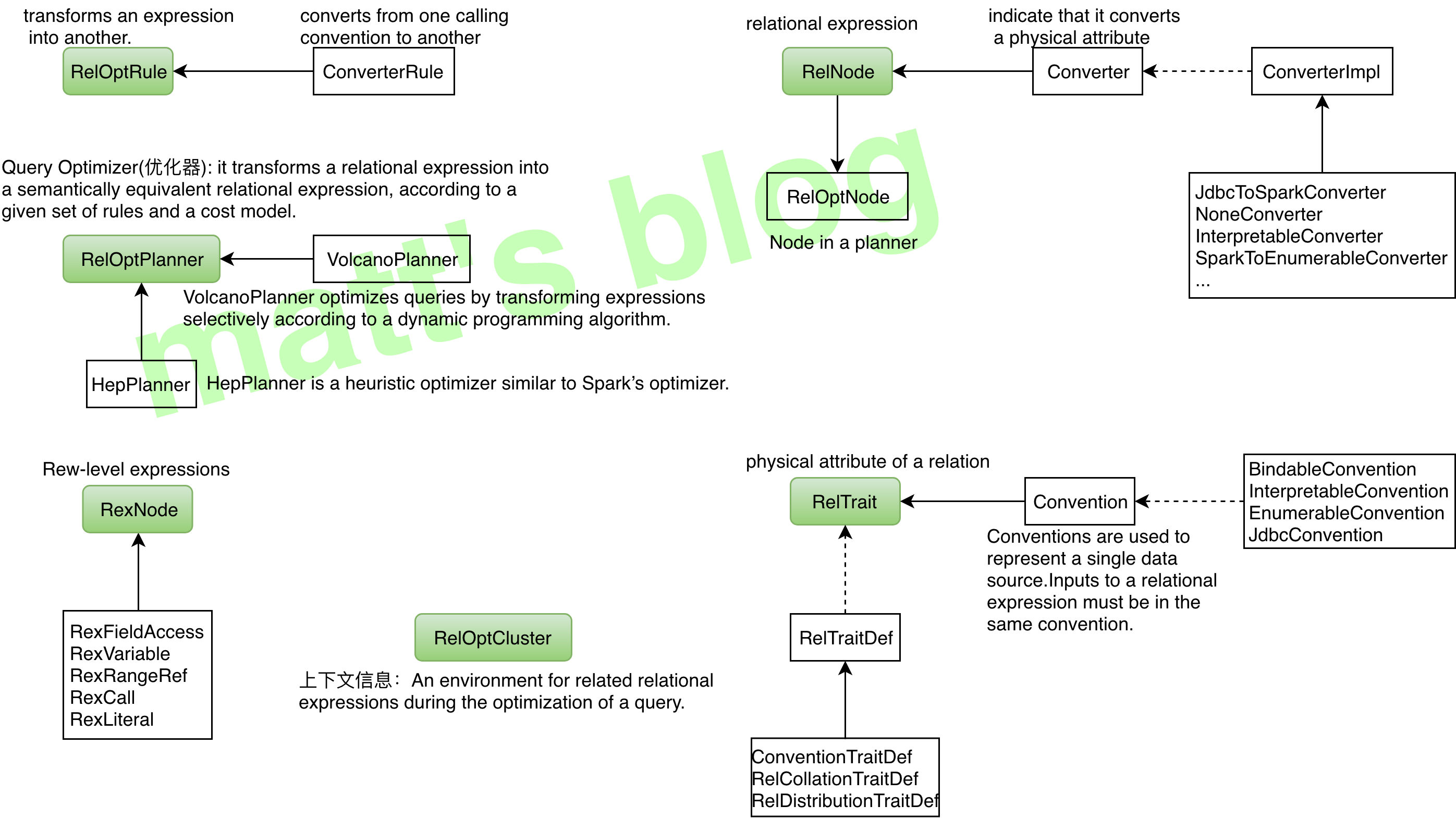
整理如下表所示:
| 类型 | 描述 | 特点 |
|---|---|---|
| RelOptRule | transforms an expression into another。对 expression 做等价转换 | 根据传递给它的 RelOptRuleOperand 来对目标 RelNode 树进行规则匹配,匹配成功后,会再次调用 matches() 方法(默认返回真)进行进一步检查。如果 mathes() 结果为真,则调用 onMatch() 进行转换。 |
| ConverterRule | Abstract base class for a rule which converts from one calling convention to another without changing semantics. | 它是 RelOptRule 的子类,专门用来做数据源之间的转换(Calling convention),ConverterRule 一般会调用对应的 Converter 来完成工作,比如说:JdbcToSparkConverterRule 调用 JdbcToSparkConverter 来完成对 JDBC Table 到 Spark RDD 的转换。 |
| RelNode | relational expression,RelNode 会标识其 input RelNode 信息,这样就构成了一棵 RelNode 树 | 代表了对数据的一个处理操作,常见的操作有 Sort、Join、Project、Filter、Scan 等。它蕴含的是对整个 Relation 的操作,而不是对具体数据的处理逻辑。 |
| Converter | A relational expression implements the interface Converter to indicate that it converts a physical attribute, or RelTrait of a relational expression from one value to another. |
用来把一种 RelTrait 转换为另一种 RelTrait 的 RelNode。如 JdbcToSparkConverter 可以把 JDBC 里的 table 转换为 Spark RDD。如果需要在一个 RelNode 中处理来源于异构系统的逻辑表,Calcite 要求先用 Converter 把异构系统的逻辑表转换为同一种 Convention。 |
| RexNode | Row-level expression | 行表达式(标量表达式),蕴含的是对一行数据的处理逻辑。每个行表达式都有数据的类型。这是因为在 Valdiation 的过程中,编译器会推导出表达式的结果类型。常见的行表达式包括字面量 RexLiteral, 变量 RexVariable, 函数或操作符调用 RexCall 等。 RexNode 通过 RexBuilder 进行构建。 |
| RelTrait | RelTrait represents the manifestation of a relational expression trait within a trait definition. | 用来定义逻辑表的物理相关属性(physical property),三种主要的 trait 类型是:Convention、RelCollation、RelDistribution; |
| Convention | Calling convention used to repressent a single data source, inputs must be in the same convention | 继承自 RelTrait,类型很少,代表一个单一的数据源,一个 relational expression 必须在同一个 convention 中; |
| RelTraitDef | 主要有三种:ConventionTraitDef:用来代表数据源 RelCollationTraitDef:用来定义参与排序的字段;RelDistributionTraitDef:用来定义数据在物理存储上的分布方式(比如:single、hash、range、random 等); | |
| RelOptCluster | An environment for related relational expressions during the optimization of a query. | palnner 运行时的环境,保存上下文信息; |
| RelOptPlanner | A RelOptPlanner is a query optimizer: it transforms a relational expression into a semantically equivalent relational expression, according to a given set of rules and a cost model. | 也就是优化器,Calcite 支持RBO(Rule-Based Optimizer) 和 CBO(Cost-Based Optimizer)。Calcite 的 RBO (HepPlanner)称为启发式优化器(heuristic implementation ),它简单地按 AST 树结构匹配所有已知规则,直到没有规则能够匹配为止;Calcite 的 CBO 称为火山式优化器(VolcanoPlanner)成本优化器也会匹配并应用规则,当整棵树的成本降低趋于稳定后,优化完成,成本优化器依赖于比较准确的成本估算。RelOptCost 和 Statistic 与成本估算相关; |
| RelOptCost | defines an interface for optimizer cost in terms of number of rows processed, CPU cost, and I/O cost. | 优化器成本模型会依赖; |
Calcite 架构
关于 Calcite 的架构,可以参考下图(图片来自前面那篇论文),它与传统数据库管理系统有一些相似之处,相比而言,它将数据存储、数据处理算法和元数据存储这些部分忽略掉了,这样设计带来的好处是:对于涉及多种数据源和多种计算引擎的应用而言,Calcite 因为可以兼容多种存储和计算引擎,使得 Calcite 可以提供统一查询服务,Calcite 将会是这些应用的最佳选择。
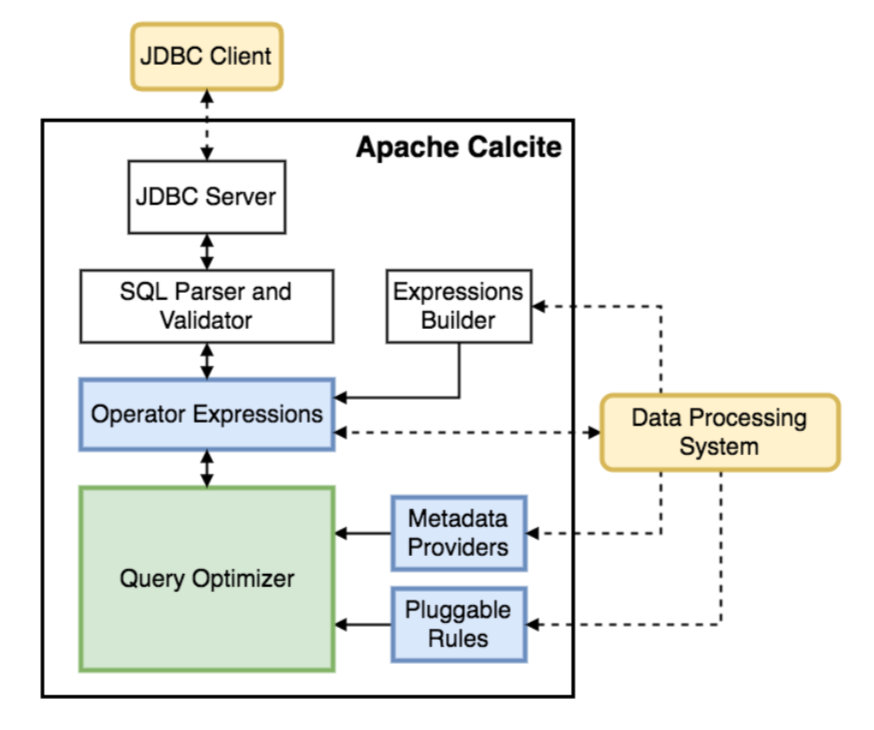
在 Calcite 架构中,最核心地方就是 Optimizer,也就是优化器,一个 Optimization Engine 包含三个组成部分:
- rules:也就是匹配规则,Calcite 内置上百种 Rules 来优化 relational expression,当然也支持自定义 rules;
- metadata providers:主要是向优化器提供信息,这些信息会有助于指导优化器向着目标(减少整体 cost)进行优化,信息可以包括行数、table 哪一列是唯一列等,也包括计算 RelNode 树中执行 subexpression cost 的函数;
- planner engines:它的主要目标是进行触发 rules 来达到指定目标,比如像 cost-based optimizer(CBO)的目标是减少cost(Cost 包括处理的数据行数、CPU cost、IO cost 等)。
Calcite 处理流程
Sql 的执行过程一般可以分为下图中的四个阶段,Calcite 同样也是这样:

但这里为了讲述方便,把 SQL 的执行分为下面五个阶段(跟上面比比又独立出了一个阶段):
- 解析 SQL, 把 SQL 转换成为 AST (抽象语法树),在 Calcite 中用 SqlNode 来表示;
- 语法检查,根据数据库的元数据信息进行语法验证,验证之后还是用 SqlNode 表示 AST 语法树;
- 语义分析,根据 SqlNode 及元信息构建 RelNode 树,也就是最初版本的逻辑计划(Logical Plan);
- 逻辑计划优化,优化器的核心,根据前面生成的逻辑计划按照相应的规则(Rule)进行优化;
- 物理执行,生成物理计划,物理执行计划执行。
这里我们只关注前四步的内容,会配合源码实现以及一个示例来讲解。
示例
示例 SQL 如下:
select u.id as user_id, u.name as user_name, j.company as user_company, u.age as user_age from users u join jobs j on u.name=j.name where u.age > 30 and j.id>10 order by user_id
这里有两张表,其表各个字段及类型定义如下:
SchemaPlus rootSchema = Frameworks.createRootSchema(true); rootSchema.add("USERS", new AbstractTable() { //note: add a table @Override public RelDataType getRowType(final RelDataTypeFactory typeFactory) { RelDataTypeFactory.Builder builder = typeFactory.builder(); builder.add("ID", new BasicSqlType(new RelDataTypeSystemImpl() {}, SqlTypeName.INTEGER)); builder.add("NAME", new BasicSqlType(new RelDataTypeSystemImpl() {}, SqlTypeName.CHAR)); builder.add("AGE", new BasicSqlType(new RelDataTypeSystemImpl() {}, SqlTypeName.INTEGER)); return builder.build(); } }); rootSchema.add("JOBS", new AbstractTable() { @Override public RelDataType getRowType(final RelDataTypeFactory typeFactory) { RelDataTypeFactory.Builder builder = typeFactory.builder(); builder.add("ID", new BasicSqlType(new RelDataTypeSystemImpl() {}, SqlTypeName.INTEGER)); builder.add("NAME", new BasicSqlType(new RelDataTypeSystemImpl() {}, SqlTypeName.CHAR)); builder.add("COMPANY", new BasicSqlType(new RelDataTypeSystemImpl() {}, SqlTypeName.CHAR)); return builder.build(); } });
Step1: SQL 解析阶段(SQL–>SqlNode)
使用 Calcite 进行 Sql 解析的代码如下:
SqlParser parser = SqlParser.create(sql, SqlParser.Config.DEFAULT);
SqlNode sqlNode = parser.parseStmt();
Calcite 使用 JavaCC 做 SQL 解析,JavaCC 根据 Calcite 中定义的 Parser.jj 文件,生成一系列的 java 代码,生成的 Java 代码会把 SQL 转换成 AST 的数据结构(这里是 SqlNode 类型)。
与 Javacc 相似的工具还有 ANTLR,JavaCC 中的 jj 文件也跟 ANTLR 中的 G4文件类似,Apache Spark 中使用这个工具做类似的事情。
Javacc
关于 Javacc 内容可以参考下面这几篇文章,这里就不再详细展开,可以通过下面文章的例子把 JavaCC 的语法了解一下,这样我们也可以自己设计一个 DSL(Doomain Specific Language)。
- JavaCC 研究与应用( 8000字 心得 源程序); https://www.cnblogs.com/Gavin_Liu/archive/2009/03/07/1405029.html
- JavaCC、解析树和 XQuery 语法,第 1 部分;https://www.ibm.com/developerworks/cn/xml/x-javacc/part1/index.html
- JavaCC、解析树和 XQuery 语法,第 2 部分;https://www.ibm.com/developerworks/cn/xml/x-javacc/part2/index.html
- 编译原理之Javacc使用;https://www.yangguo.info/2014/12/13/%E7%BC%96%E8%AF%91%E5%8E%9F%E7%90%86-Javacc%E4%BD%BF%E7%94%A8/
- javacc tutorial;http://www.engr.mun.ca/~theo/JavaCC-Tutorial/javacc-tutorial.pdf
回到 Calcite,Javacc 这里要实现一个 SQL Parser,它的功能有以下两个,这里都是需要在 jj 文件中定义的。
- 设计词法和语义,定义 SQL 中具体的元素;
- 实现词法分析器(Lexer)和语法分析器(Parser),完成对 SQL 的解析,完成相应的转换。
SQL Parser 流程
当 SqlParser 调用 parseStmt() 方法后,其相应的逻辑如下:
// org.apache.calcite.sql.parser.SqlParser public SqlNode parseStmt() throws SqlParseException { return parseQuery(); } public SqlNode parseQuery() throws SqlParseException { try { return parser.parseSqlStmtEof(); //note: 解析sql语句 } catch (Throwable ex) { if (ex instanceof CalciteContextException) { final String originalSql = parser.getOriginalSql(); if (originalSql != null) { ((CalciteContextException) ex).setOriginalStatement(originalSql); } } throw parser.normalizeException(ex); } }
其中 SqlParser 中 parser 指的是 SqlParserImpl 类(SqlParser.Config.DEFAULT 指定的),它就是由 JJ 文件生成的解析类,其处理流程如下,具体解析逻辑还是要看 JJ 文件中的定义。
//org.apache.calcite.sql.parser.impl.SqlParserImpl public SqlNode parseSqlStmtEof() throws Exception { return SqlStmtEof(); } /** * Parses an SQL statement followed by the end-of-file symbol. * note:解析SQL语句(后面有文件结束符号) */ final public SqlNode SqlStmtEof() throws ParseException { SqlNode stmt; stmt = SqlStmt(); jj_consume_token(0); {if (true) return stmt;} throw new Error("Missing return statement in function"); } //note: 解析 SQL statement final public SqlNode SqlStmt() throws ParseException { SqlNode stmt; if (jj_2_34(2)) { stmt = SqlSetOption(Span.of(), null); } else if (jj_2_35(2)) { stmt = SqlAlter(); } else if (jj_2_36(2)) { stmt = OrderedQueryOrExpr(ExprContext.ACCEPT_QUERY); } else if (jj_2_37(2)) { stmt = SqlExplain(); } else if (jj_2_38(2)) { stmt = SqlDescribe(); } else if (jj_2_39(2)) { stmt = SqlInsert(); } else if (jj_2_40(2)) { stmt = SqlDelete(); } else if (jj_2_41(2)) { stmt = SqlUpdate(); } else if (jj_2_42(2)) { stmt = SqlMerge(); } else if (jj_2_43(2)) { stmt = SqlProcedureCall(); } else { jj_consume_token(-1); throw new ParseException(); } {if (true) return stmt;} throw new Error("Missing return statement in function"); }
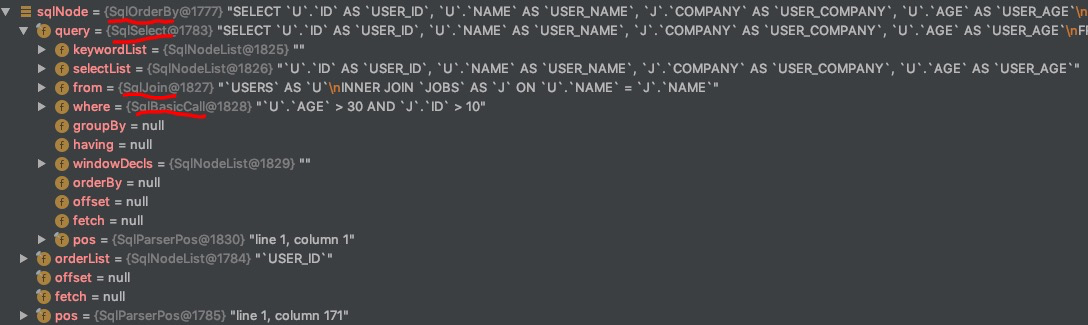
示例中 SQL 经过前面的解析之后,会生成一个 SqlNode,这个 SqlNode 是一个 SqlOrder 类型,DEBUG 后的 SqlOrder 对象如下图所示。
Step2: SqlNode 验证(SqlNode–>SqlNode)
经过上面的第一步,会生成一个 SqlNode 对象,它是一个未经验证的抽象语法树,下面就进入了一个语法检查阶段,语法检查前需要知道元数据信息,这个检查会包括表名、字段名、函数名、数据类型的检查。进行语法检查的实现如下:
//note: 二、sql validate(会先通过Catalog读取获取相应的metadata和namespace) //note: get metadata and namespace SqlTypeFactoryImpl factory = new SqlTypeFactoryImpl(RelDataTypeSystem.DEFAULT); CalciteCatalogReader calciteCatalogReader = new CalciteCatalogReader( CalciteSchema.from(rootScheme), CalciteSchema.from(rootScheme).path(null), factory, new CalciteConnectionConfigImpl(new Properties())); //note: 校验(包括对表名,字段名,函数名,字段类型的校验。) SqlValidator validator = SqlValidatorUtil.newValidator(SqlStdOperatorTable.instance(), calciteCatalogReader, factory, conformance(frameworkConfig)); SqlNode validateSqlNode = validator.validate(sqlNode);
我们知道 Calcite 本身是不管理和存储元数据的,在检查之前,需要先把元信息注册到 Calcite 中,一般的操作方法是实现 SchemaFactory,由它去创建相应的 Schema,在 Schema 中可以注册相应的元数据信息(如:通过 getTableMap() 方法注册表信息),如下所示:
//org.apache.calcite.schema.impl.AbstractSchema /** * Returns a map of tables in this schema by name. * * <p>The implementations of {@link #getTableNames()} * and {@link #getTable(String)} depend on this map. * The default implementation of this method returns the empty map. * Override this method to change their behavior.</p> * * @return Map of tables in this schema by name */ protected Map<String, Table> getTableMap() { return ImmutableMap.of(); } //org.apache.calcite.adapter.csvorg.apache.calcite.adapter.csv.CsvSchemasvSchema //note: 创建表 @Override protected Map<String, Table> getTableMap() { if (tableMap == null) { tableMap = createTableMap(); } return tableMap; }
CsvSchemasvSchema 中的 getTableMap() 方法通过 createTableMap() 来注册相应的表信息。
结合前面的例子再来分析,在前面定义了 CalciteCatalogReader 实例,该实例就是用来读取 Schema 中的元数据信息的。真正检查的逻辑是在 SqlValidatorImpl 类中实现的,这个 check 的逻辑比较复杂,在看代码时通过两种手段来看:
- DEBUG 的方式,可以看到其方法调用的过程;
- 测试程序中故意构造一些 Case,观察其异常栈。
比如,在示例中 SQL 中,如果把一个字段名写错,写成 ids,其报错信息如下:
org.apache.calcite.runtime.CalciteContextException: From line 1, column 156 to line 1, column 158: Column 'IDS' not found in table 'J' at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:423) at org.apache.calcite.runtime.Resources$ExInstWithCause.ex(Resources.java:463) at org.apache.calcite.sql.SqlUtil.newContextException(SqlUtil.java:787) at org.apache.calcite.sql.SqlUtil.newContextException(SqlUtil.java:772) at org.apache.calcite.sql.validate.SqlValidatorImpl.newValidationError(SqlValidatorImpl.java:4788) at org.apache.calcite.sql.validate.DelegatingScope.fullyQualify(DelegatingScope.java:439) at org.apache.calcite.sql.validate.SqlValidatorImpl$Expander.visit(SqlValidatorImpl.java:5683) at org.apache.calcite.sql.validate.SqlValidatorImpl$Expander.visit(SqlValidatorImpl.java:5665) at org.apache.calcite.sql.SqlIdentifier.accept(SqlIdentifier.java:334) at org.apache.calcite.sql.util.SqlShuttle$CallCopyingArgHandler.visitChild(SqlShuttle.java:134) at org.apache.calcite.sql.util.SqlShuttle$CallCopyingArgHandler.visitChild(SqlShuttle.java:101) at org.apache.calcite.sql.SqlOperator.acceptCall(SqlOperator.java:865) at org.apache.calcite.sql.validate.SqlValidatorImpl$Expander.visitScoped(SqlValidatorImpl.java:5701) at org.apache.calcite.sql.validate.SqlScopedShuttle.visit(SqlScopedShuttle.java:50) at org.apache.calcite.sql.validate.SqlScopedShuttle.visit(SqlScopedShuttle.java:33) at org.apache.calcite.sql.SqlCall.accept(SqlCall.java:138) at org.apache.calcite.sql.util.SqlShuttle$CallCopyingArgHandler.visitChild(SqlShuttle.java:134) at org.apache.calcite.sql.util.SqlShuttle$CallCopyingArgHandler.visitChild(SqlShuttle.java:101) at org.apache.calcite.sql.SqlOperator.acceptCall(SqlOperator.java:865) at org.apache.calcite.sql.validate.SqlValidatorImpl$Expander.visitScoped(SqlValidatorImpl.java:5701) at org.apache.calcite.sql.validate.SqlScopedShuttle.visit(SqlScopedShuttle.java:50) at org.apache.calcite.sql.validate.SqlScopedShuttle.visit(SqlScopedShuttle.java:33) at org.apache.calcite.sql.SqlCall.accept(SqlCall.java:138) at org.apache.calcite.sql.validate.SqlValidatorImpl.expand(SqlValidatorImpl.java:5272) at org.apache.calcite.sql.validate.SqlValidatorImpl.validateWhereClause(SqlValidatorImpl.java:3977) at org.apache.calcite.sql.validate.SqlValidatorImpl.validateSelect(SqlValidatorImpl.java:3305) at org.apache.calcite.sql.validate.SelectNamespace.validateImpl(SelectNamespace.java:60) at org.apache.calcite.sql.validate.AbstractNamespace.validate(AbstractNamespace.java:84) at org.apache.calcite.sql.validate.SqlValidatorImpl.validateNamespace(SqlValidatorImpl.java:977) at org.apache.calcite.sql.validate.SqlValidatorImpl.validateQuery(SqlValidatorImpl.java:953) at org.apache.calcite.sql.SqlSelect.validate(SqlSelect.java:216) at org.apache.calcite.sql.validate.SqlValidatorImpl.validateScopedExpression(SqlValidatorImpl.java:928) at org.apache.calcite.sql.validate.SqlValidatorImpl.validate(SqlValidatorImpl.java:632) at com.matt.test.calcite.test.SqlTest3.sqlToRelNode(SqlTest3.java:200) at com.matt.test.calcite.test.SqlTest3.main(SqlTest3.java:117) Caused by: org.apache.calcite.sql.validate.SqlValidatorException: Column 'IDS' not found in table 'J' at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:423) at org.apache.calcite.runtime.Resources$ExInstWithCause.ex(Resources.java:463) at org.apache.calcite.runtime.Resources$ExInst.ex(Resources.java:572) ... 33 more java.lang.NullPointerException at org.apache.calcite.plan.hep.HepPlanner.addRelToGraph(HepPlanner.java:806) at org.apache.calcite.plan.hep.HepPlanner.setRoot(HepPlanner.java:152) at com.matt.test.calcite.test.SqlTest3.main(SqlTest3.java:124)
SqlValidatorImpl 检查过程
语法检查验证是通过 SqlValidatorImpl 的 validate() 方法进行操作的,其实现如下:
org.apache.calcite.sql.validate.SqlValidatorImpl //note: 做相应的语法树校验 public SqlNode validate(SqlNode topNode) { //note: root 对应的 Scope SqlValidatorScope scope = new EmptyScope(this); scope = new CatalogScope(scope, ImmutableList.of("CATALOG")); //note: 1.rewrite expression //note: 2.做相应的语法检查 final SqlNode topNode2 = validateScopedExpression(topNode, scope); //note: 验证 final RelDataType type = getValidatedNodeType(topNode2); Util.discard(type); return topNode2; }
主要的实现是在 validateScopedExpression() 方法中,其实现如下
private SqlNode validateScopedExpression( SqlNode topNode, SqlValidatorScope scope) { //note: 1. rewrite expression,将其标准化,便于后面的逻辑计划优化 SqlNode outermostNode = performUnconditionalRewrites(topNode, false); cursorSet.add(outermostNode); top = outermostNode; TRACER.trace("After unconditional rewrite: {}", outermostNode); //note: 2. Registers a query in a parent scope. //note: register scopes and namespaces implied a relational expression if (outermostNode.isA(SqlKind.TOP_LEVEL)) { registerQuery(scope, null, outermostNode, outermostNode, null, false); } //note: 3. catalog 验证,调用 SqlNode 的 validate 方法, outermostNode.validate(this, scope); if (!outermostNode.isA(SqlKind.TOP_LEVEL)) { // force type derivation so that we can provide it to the // caller later without needing the scope deriveType(scope, outermostNode); } TRACER.trace("After validation: {}", outermostNode); return outermostNode; }
它的处理逻辑主要分为三步:
- rewrite expression,将其标准化,便于后面的逻辑计划优化;
- 注册这个 relational expression 的 scopes 和 namespaces(这两个对象代表了其元信息);
- 进行相应的验证,这里会依赖第二步注册的 scopes 和 namespaces 信息。
Rewrite
关于 Rewrite 这一步,一直困惑比较,因为根据 After unconditional rewrite: 这条日志的结果看,其实前后 SqlNode 并没有太大变化,看 performUnconditionalRewrites() 这部分代码时,看得不是很明白,不过还是注意到了 SqlOrderBy 的注释(注释如下),它的意思是 SqlOrderBy 通过 performUnconditionalRewrites() 方法已经被 SqlSelect 对象中的 ORDER_OPERAND 取代了。
/** * Parse tree node that represents an {@code ORDER BY} on a query other than a * {@code SELECT} (e.g. {@code VALUES} or {@code UNION}). * * <p>It is a purely syntactic operator, and is eliminated by * {@link org.apache.calcite.sql.validate.SqlValidatorImpl#performUnconditionalRewrites} * and replaced with the ORDER_OPERAND of SqlSelect.</p> */ public class SqlOrderBy extends SqlCall {
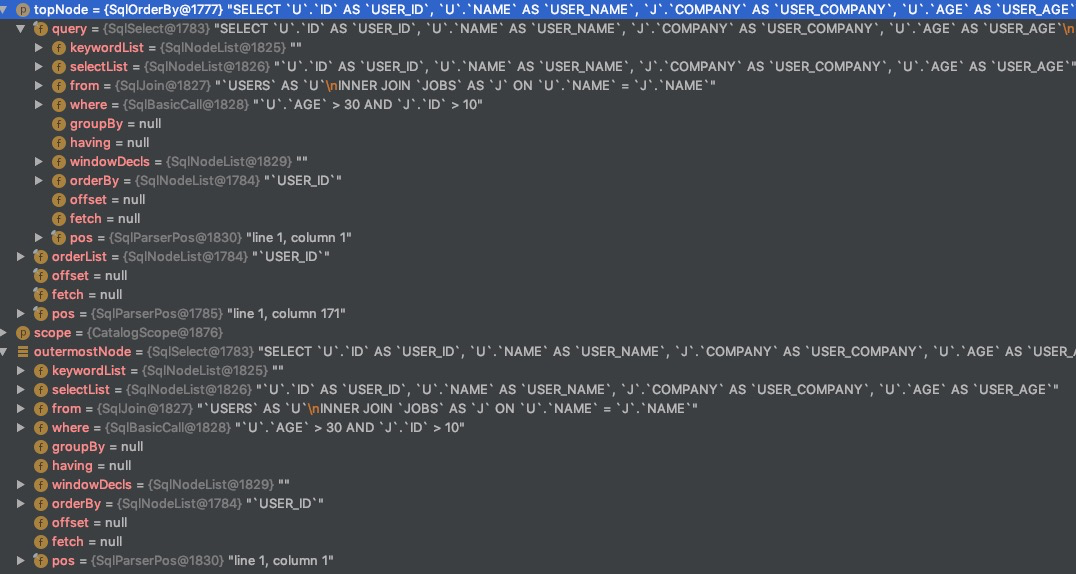
注意到 SqlOrderBy 的原因是因为在 performUnconditionalRewrites() 方法前面都是递归对每个对象进行处理,在后面进行真正的 ransform 时,主要在围绕着 ORDER_BY 这个类型做处理,而且从代码中可以看出,将其类型从 SqlOrderBy 转换成了 SqlSelect,BUDEG 前面的示例,发现 outermostNode 与 topNode 的类型确实发生了变化,如下图所示。
这个方法有个好的地方就是,在不改变原有 SQL Parser 的逻辑的情况下,可以在这个方法里做一些改动,当然如果 SQL Parser 的结果如果直接可用当然是最好的,就不需要再进行一次 Rewrite 了。
registerQuery
这里的功能主要就是将[元数据]转换成 SqlValidator 内部的 对象 进行表示,也就是 SqlValidatorScope 和 SqlValidatorNamespace 两种类型的对象:
- SqlValidatorNamespace:a description of a data source used in a query,它代表了 SQL 查询的数据源,它是一个逻辑上数据源,可以是一张表,也可以是一个子查询;
- SqlValidatorScope:describes the tables and columns accessible at a particular point in the query,代表了在某一个程序运行点,当前可见的字段名和表名。
这个理解起来并不是那么容易,在 SelectScope 类中有一个示例讲述,这个示例对这两个概念的理解很有帮助。
/** * <h3>Scopes</h3> * * <p>In the query</p> * * <blockquote> * <pre> * SELECT expr1 * FROM t1, * t2, * (SELECT expr2 FROM t3) AS q3 * WHERE c1 IN (SELECT expr3 FROM t4) * ORDER BY expr4</pre> * </blockquote> * * <p>The scopes available at various points of the query are as follows:</p> * * <ul> * <li>expr1 can see t1, t2, q3</li> * <li>expr2 can see t3</li> * <li>expr3 can see t4, t1, t2</li> * <li>expr4 can see t1, t2, q3, plus (depending upon the dialect) any aliases * defined in the SELECT clause</li> * </ul> * * <h3>Namespaces</h3> * * <p>In the above query, there are 4 namespaces:</p> * * <ul> * <li>t1</li> * <li>t2</li> * <li>(SELECT expr2 FROM t3) AS q3</li> * <li>(SELECT expr3 FROM t4)</li> */
validate 验证
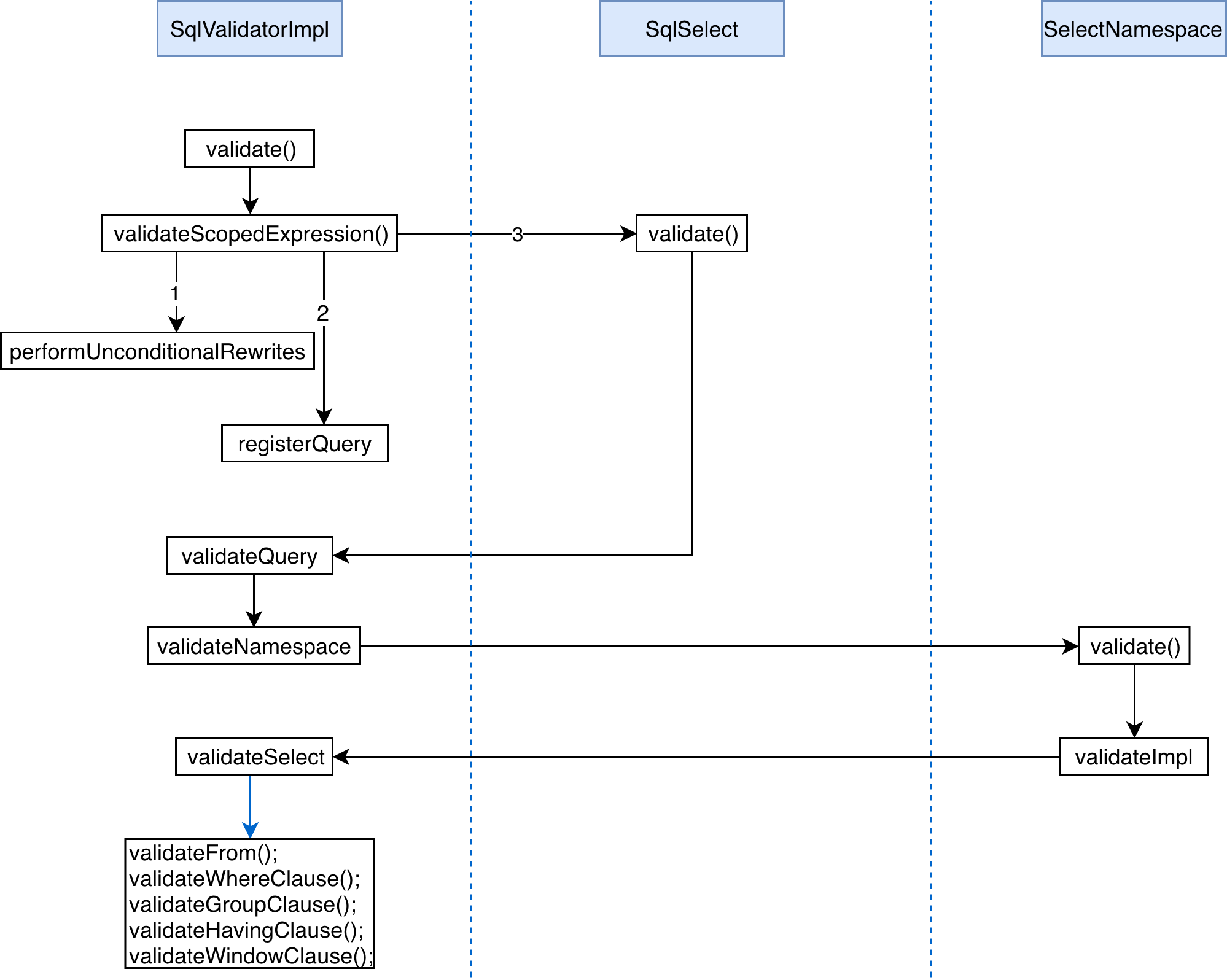
接着回到最复杂的一步,就是 outermostNode 实例调用 validate(this, scope) 方法进行验证的部分,对于我们这个示例,这里最后调用的是 SqlSelect 的 validate() 方法,如下所示:
public void validate(SqlValidator validator, SqlValidatorScope scope) { validator.validateQuery(this, scope, validator.getUnknownType()); }
它调用的是 SqlValidatorImpl 的 validateQuery() 方法
public void validateQuery(SqlNode node, SqlValidatorScope scope, RelDataType targetRowType) { final SqlValidatorNamespace ns = getNamespace(node, scope); if (node.getKind() == SqlKind.TABLESAMPLE) { List<SqlNode> operands = ((SqlCall) node).getOperandList(); SqlSampleSpec sampleSpec = SqlLiteral.sampleValue(operands.get(1)); if (sampleSpec instanceof SqlSampleSpec.SqlTableSampleSpec) { validateFeature(RESOURCE.sQLFeature_T613(), node.getParserPosition()); } else if (sampleSpec instanceof SqlSampleSpec.SqlSubstitutionSampleSpec) { validateFeature(RESOURCE.sQLFeatureExt_T613_Substitution(), node.getParserPosition()); } } validateNamespace(ns, targetRowType);//note: 检查 switch (node.getKind()) { case EXTEND: // Until we have a dedicated namespace for EXTEND deriveType(scope, node); } if (node == top) { validateModality(node); } validateAccess( node, ns.getTable(), SqlAccessEnum.SELECT); } /** * Validates a namespace. * * @param namespace Namespace * @param targetRowType Desired row type, must not be null, may be the data * type 'unknown'. */ protected void validateNamespace(final SqlValidatorNamespace namespace, RelDataType targetRowType) { namespace.validate(targetRowType);//note: 验证 if (namespace.getNode() != null) { setValidatedNodeType(namespace.getNode(), namespace.getType()); } }
这部分的调用逻辑非常复杂,主要的语法验证是 SqlValidatorScope 部分(它里面有相应的表名、字段名等信息),而 namespace 表示需要进行验证的数据源,最开始的这个 SqlNode 有一个 root namespace,上面的 validateNamespace() 方法会首先调用其 namespace 的 validate() 方法进行验证,以前面的示例为例,这里是 SelectNamespace,其实现如下:
//org.apache.calcite.sql.validate.AbstractNamespace public final void validate(RelDataType targetRowType) { switch (status) { case UNVALIDATED: //note: 还没开始 check try { status = SqlValidatorImpl.Status.IN_PROGRESS; //note: 更新当前 namespace 的状态 Preconditions.checkArgument(rowType == null, "Namespace.rowType must be null before validate has been called"); RelDataType type = validateImpl(targetRowType); //note: 检查验证 Preconditions.checkArgument(type != null, "validateImpl() returned null"); setType(type); } finally { status = SqlValidatorImpl.Status.VALID; } break; case IN_PROGRESS: //note: 已经开始 check 了,死循环了 throw new AssertionError("Cycle detected during type-checking"); case VALID://note: 检查结束 break; default: throw Util.unexpected(status); } } //org.apache.calcite.sql.validate.SelectNamespace //note: 检查,还是调用 SqlValidatorImpl 的方法 public RelDataType validateImpl(RelDataType targetRowType) { validator.validateSelect(select, targetRowType); return rowType; }
最后验证方法的实现是 SqlValidatorImpl 的 validateSelect() 方法(对本示例而言),其调用过程如下图所示:
Step3: 语义分析(SqlNode–>RelNode/RexNode)
经过第二步之后,这里的 SqlNode 就是经过语法校验的 SqlNode 树,接下来这一步就是将 SqlNode 转换成 RelNode/RexNode,也就是生成相应的逻辑计划(Logical Plan),示例的代码实现如下:
// create the rexBuilder final RexBuilder rexBuilder = new RexBuilder(factory); // init the planner // 这里也可以注册 VolcanoPlanner,这一步 planner 并没有使用 HepProgramBuilder builder = new HepProgramBuilder(); RelOptPlanner planner = new HepPlanner(builder.build()); //note: init cluster: An environment for related relational expressions during the optimization of a query. final RelOptCluster cluster = RelOptCluster.create(planner, rexBuilder); //note: init SqlToRelConverter final SqlToRelConverter.Config config = SqlToRelConverter.configBuilder() .withConfig(frameworkConfig.getSqlToRelConverterConfig()) .withTrimUnusedFields(false) .withConvertTableAccess(false) .build(); //note: config // 创建 SqlToRelConverter 实例,cluster、calciteCatalogReader、validator 都传进去了,SqlToRelConverter 会缓存这些对象 final SqlToRelConverter sqlToRelConverter = new SqlToRelConverter(new DogView(), validator, calciteCatalogReader, cluster, StandardConvertletTable.INSTANCE, config); // convert to RelNode RelRoot root = sqlToRelConverter.convertQuery(validateSqlNode, false, true); root = root.withRel(sqlToRelConverter.flattenTypes(root.rel, true)); final RelBuilder relBuilder = config.getRelBuilderFactory().create(cluster, null); root = root.withRel(RelDecorrelator.decorrelateQuery(root.rel, relBuilder)); RelNode relNode = root.rel; //DogView 的实现 private static class DogView implements RelOptTable.ViewExpander { public DogView() { } @Override public RelRoot expandView(RelDataType rowType, String queryString, List<String> schemaPath, List<String> viewPath) { return null; } }
为了方便分析,这里也把上面的过程分为以下几步:
- 初始化 RexBuilder;
- 初始化 RelOptPlanner;
- 初始化 RelOptCluster;
- 初始化 SqlToRelConverter;
- 进行转换;
第1、2、4步在上述代码已经有相应的注释,这里不再介绍,下面从第三步开始讲述。
初始化 RelOptCluster
RelOptCluster 初始化的代码如下,这里基本都走默认的参数配置。
org.apache.calcite.plan.RelOptCluster /** Creates a cluster. */ public static RelOptCluster create(RelOptPlanner planner, RexBuilder rexBuilder) { return new RelOptCluster(planner, rexBuilder.getTypeFactory(), rexBuilder, new AtomicInteger(0), new HashMap<>()); } /** * Creates a cluster. * * <p>For use only from {@link #create} and {@link RelOptQuery}. */ RelOptCluster(RelOptPlanner planner, RelDataTypeFactory typeFactory, RexBuilder rexBuilder, AtomicInteger nextCorrel, Map<String, RelNode> mapCorrelToRel) { this.nextCorrel = nextCorrel; this.mapCorrelToRel = mapCorrelToRel; this.planner = Objects.requireNonNull(planner); this.typeFactory = Objects.requireNonNull(typeFactory); this.rexBuilder = rexBuilder; this.originalExpression = rexBuilder.makeLiteral("?"); // set up a default rel metadata provider, // giving the planner first crack at everything //note: 默认的 metadata provider setMetadataProvider(DefaultRelMetadataProvider.INSTANCE); //note: trait(对于 HepPlaner 和 VolcanoPlanner 不一样) this.emptyTraitSet = planner.emptyTraitSet(); assert emptyTraitSet.size() == planner.getRelTraitDefs().size(); }
SqlToRelConverter 转换
SqlToRelConverter 中的 convertQuery() 将 SqlNode 转换为 RelRoot,其实现如下:
/** * Converts an unvalidated query's parse tree into a relational expression. * note:把一个 parser tree 转换为 relational expression * @param query Query to convert * @param needsValidation Whether to validate the query before converting; * <code>false</code> if the query has already been * validated. * @param top Whether the query is top-level, say if its result * will become a JDBC result set; <code>false</code> if * the query will be part of a view. */ public RelRoot convertQuery( SqlNode query, final boolean needsValidation, final boolean top) { if (needsValidation) { //note: 是否需要做相应的校验(如果校验过了,这里就不需要了) query = validator.validate(query); } //note: 设置 MetadataProvider RelMetadataQuery.THREAD_PROVIDERS.set( JaninoRelMetadataProvider.of(cluster.getMetadataProvider())); //note: 得到 RelNode(relational expression) RelNode result = convertQueryRecursive(query, top, null).rel; if (top) { if (isStream(query)) {//note: 如果 stream 的话 result = new LogicalDelta(cluster, result.getTraitSet(), result); } } RelCollation collation = RelCollations.EMPTY; if (!query.isA(SqlKind.DML)) { //note: 如果是 DML 语句 if (isOrdered(query)) { //note: 如果需要做排序的话 collation = requiredCollation(result); } } //note: 对转换前后的 RelDataType 做验证 checkConvertedType(query, result); if (SQL2REL_LOGGER.isDebugEnabled()) { SQL2REL_LOGGER.debug( RelOptUtil.dumpPlan("Plan after converting SqlNode to RelNode", result, SqlExplainFormat.TEXT, SqlExplainLevel.EXPPLAN_ATTRIBUTES)); } final RelDataType validatedRowType = validator.getValidatedNodeType(query); return RelRoot.of(result, validatedRowType, query.getKind()) .withCollation(collation); }
真正的实现是在 convertQueryRecursive() 方法中完成的,如下:
/** * Recursively converts a query to a relational expression. * note:递归地讲一个 query 转换为 relational expression * * @param query Query * @param top Whether this query is the top-level query of the * statement * @param targetRowType Target row type, or null * @return Relational expression */ protected RelRoot convertQueryRecursive(SqlNode query, boolean top, RelDataType targetRowType) { final SqlKind kind = query.getKind(); switch (kind) { case SELECT: return RelRoot.of(convertSelect((SqlSelect) query, top), kind); case INSERT: return RelRoot.of(convertInsert((SqlInsert) query), kind); case DELETE: return RelRoot.of(convertDelete((SqlDelete) query), kind); case UPDATE: return RelRoot.of(convertUpdate((SqlUpdate) query), kind); case MERGE: return RelRoot.of(convertMerge((SqlMerge) query), kind); case UNION: case INTERSECT: case EXCEPT: return RelRoot.of(convertSetOp((SqlCall) query), kind); case WITH: return convertWith((SqlWith) query, top); case VALUES: return RelRoot.of(convertValues((SqlCall) query, targetRowType), kind); default: throw new AssertionError("not a query: " + query); } }
依然以前面的示例为例,因为是 SqlSelect 类型,这里会调用下面的方法做相应的转换:
/** * Converts a SELECT statement's parse tree into a relational expression. * note:将一个 Select parse tree 转换成一个关系表达式 */ public RelNode convertSelect(SqlSelect select, boolean top) { final SqlValidatorScope selectScope = validator.getWhereScope(select); final Blackboard bb = createBlackboard(selectScope, null, top); convertSelectImpl(bb, select);//note: 做相应的转换 return bb.root; }
在 convertSelectImpl() 方法中会依次对 SqlSelect 的各个部分做相应转换,其实现如下:
/** * Implementation of {@link #convertSelect(SqlSelect, boolean)}; * derived class may override. */ protected void convertSelectImpl( final Blackboard bb, SqlSelect select) { //note: convertFrom convertFrom( bb, select.getFrom()); //note: convertWhere convertWhere( bb, select.getWhere()); final List<SqlNode> orderExprList = new ArrayList<>(); final List<RelFieldCollation> collationList = new ArrayList<>(); //note: 有 order by 操作时 gatherOrderExprs( bb, select, select.getOrderList(), orderExprList, collationList); final RelCollation collation = cluster.traitSet().canonize(RelCollations.of(collationList)); if (validator.isAggregate(select)) { //note: 当有聚合操作时,也就是含有 group by、having 或者 Select 和 order by 中含有聚合函数 convertAgg( bb, select, orderExprList); } else { //note: 对 select list 部分的处理 convertSelectList( bb, select, orderExprList); } if (select.isDistinct()) { //note: select 后面含有 DISTINCT 关键字时(去重) distinctify(bb, true); } //note: Converts a query's ORDER BY clause, if any. convertOrder( select, bb, collation, orderExprList, select.getOffset(), select.getFetch()); bb.setRoot(bb.root, true); }
这里以示例中的 From 部分为例介绍 SqlNode 到 RelNode 的逻辑,按照示例 DEUBG 后的结果如下图所示,因为 form 部分是一个 join 操作,会进入 join 相关的处理中。
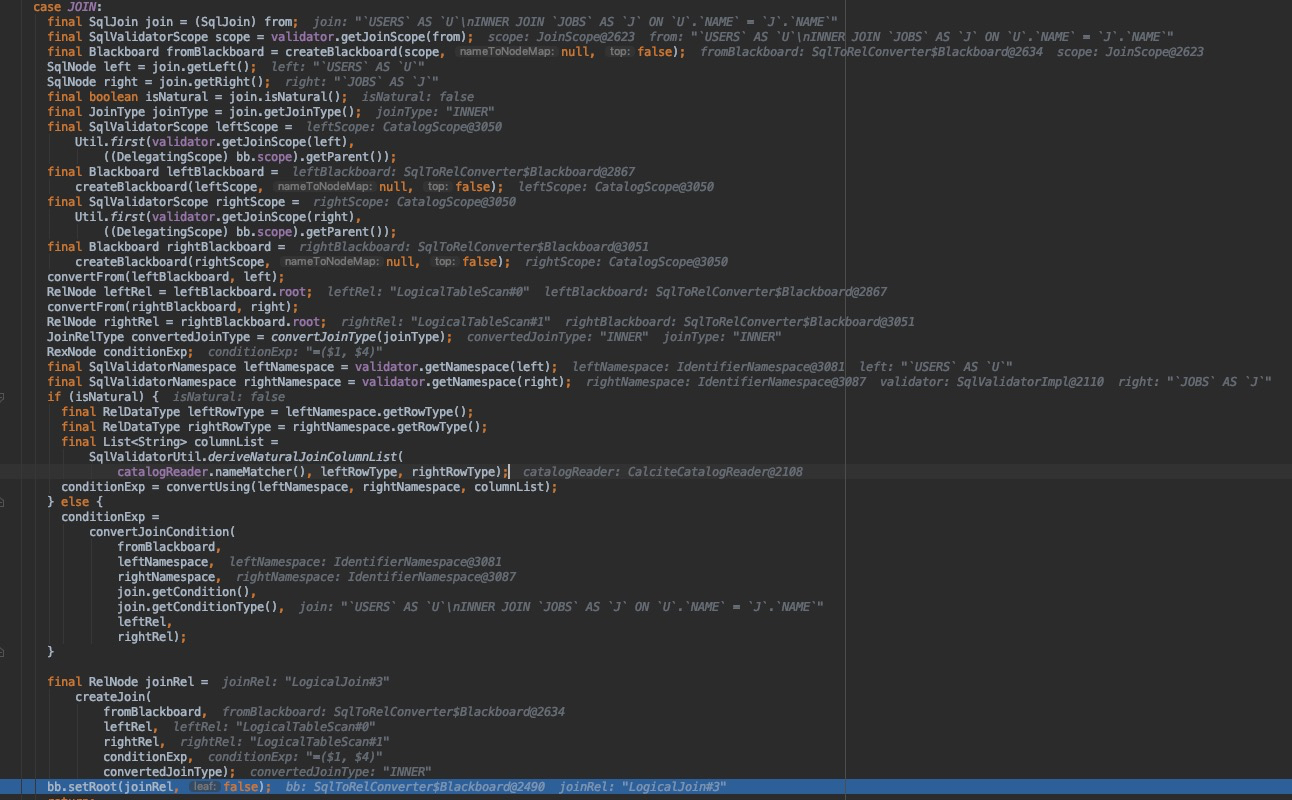
这部分方法调用过程是:
convertQuery --> convertQueryRecursive --> convertSelect --> convertSelectImpl --> convertFrom & convertWhere & convertSelectList
到这里 SqlNode 到 RelNode 过程就完成了,生成的逻辑计划如下:
LogicalSort(sort0=[$0], dir0=[ASC]) LogicalProject(USER_ID=[$0], USER_NAME=[$1], USER_COMPANY=[$5], USER_AGE=[$2]) LogicalFilter(condition=[AND(>($2, 30), >($3, 10))]) LogicalJoin(condition=[=($1, $4)], joinType=[inner]) LogicalTableScan(table=[[USERS]]) LogicalTableScan(table=[[JOBS]])
到这里前三步就算全部完成了。
Step4: 优化阶段(RelNode–>RelNode)
终于来来到了第四阶段,也就是 Calcite 的核心所在,优化器进行优化的地方,前面 sql 中有一个明显可以优化的地方就是过滤条件的下压(push down),在进行 join 操作前,先进行 filter 操作,这样的话就不需要在 join 时进行全量 join,减少参与 join 的数据量。
关于filter 操作下压,在 Calcite 中已经有相应的 Rule 实现,就是 FilterJoinRule.FilterIntoJoinRule.FILTER_ON_JOIN,这里使用 HepPlanner 作为示例的 planer,并注册 FilterIntoJoinRule 规则进行相应的优化,其代码实现如下:
HepProgramBuilder builder = new HepProgramBuilder(); builder.addRuleInstance(FilterJoinRule.FilterIntoJoinRule.FILTER_ON_JOIN); //note: 添加 rule HepPlanner hepPlanner = new HepPlanner(builder.build()); hepPlanner.setRoot(relNode); relNode = hepPlanner.findBestExp();
在 Calcite 中,提供了两种 planner:HepPlanner 和 VolcanoPlanner,关于这块内容可以参考【Drill/Calcite查询优化系列】这几篇文章(讲述得非常详细,赞),这里先简单介绍一下 HepPlanner 和 VolcanoPlanner,后面会关于这两个 planner 的代码实现做深入的讲述。
HepPlanner
特点(来自 Apache Calcite介绍):
- HepPlanner is a heuristic optimizer similar to Spark’s optimizer,与 spark 的优化器相似,HepPlanner 是一个 heuristic 优化器;
- Applies all matching rules until none can be applied:将会匹配所有的 rules 直到一个 rule 被满足;
- Heuristic optimization is faster than cost- based optimization:它比 CBO 更快;
- Risk of infinite recursion if rules make opposing changes to the plan:如果没有每次都不匹配规则,可能会有无限递归风险;
VolcanoPlanner
特点(来自 Apache Calcite介绍):
- VolcanoPlanner is a cost-based optimizer:VolcanoPlanner是一个CBO优化器;
- Applies matching rules iteratively, selecting the plan with the cheapest cost on each iteration:迭代地应用 rules,直到找到cost最小的plan;
- Costs are provided by relational expressions;
- Not all possible plans can be computed:不会计算所有可能的计划;
- Stops optimization when the cost does not significantly improve through a determinable number of iterations:根据已知的情况,如果下面的迭代不能带来提升时,这些计划将会停止优化;
示例运行结果
经过 HepPlanner 优化后的逻辑计划为:
LogicalSort(sort0=[$0], dir0=[ASC]) LogicalProject(USER_ID=[$0], USER_NAME=[$1], USER_COMPANY=[$5], USER_AGE=[$2]) LogicalJoin(condition=[=($1, $4)], joinType=[inner]) LogicalFilter(condition=[>($2, 30)]) EnumerableTableScan(table=[[USERS]]) LogicalFilter(condition=[>($0, 10)]) EnumerableTableScan(table=[[JOBS]])
可以看到优化的结果是符合我们预期的,HepPlanner 和 VolcanoPlanner 详细流程比较复杂,后面会有单独的文章进行讲述。
总结
Calcite 本身的架构比较好理解,但是具体到代码层面就不是那么好理解了,它抛出了很多的概念,如果不把这些概念搞明白,代码基本看得也是云里雾里,特别是之前没有接触过这块内容的同学(我最开始看 Calcite 代码时是真的头大),入门的门槛确实高一些,但是当这些流程梳理清楚之后,其实再回头看,也没有多少东西,在生产中用的时候主要也是针对具体的业务场景扩展相应的 SQL 语法、进行具体的规则优化。
Calcite 架构设计得比较好,其中各个组件都可以单独使用,Rule(规则)扩展性很强,用户可以根据业务场景自定义相应的优化规则,它支持标准的 SQL,支持不同的存储和计算引擎,目前在业界应用也比较广泛,这也证明其牛叉之处。
Apache calcite 优化器解析(二)https://matt33.com/2019/03/17/apache-calcite-planner/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号