
IOS 开发:绘制像素到屏幕
像素是如何绘制到屏幕上面的?把数据输出到屏幕的方法有很多,通过调用很多不同的framework和不同的函数。这里我们讲一下这个过程背后的东西。希望能够帮助大家了解什么时候该使用什么API,特别是当遇到性能问题需要调试的时候。当然,我们这里主要讲iOS,但是事实上,很多东西也是可以应用到OSX上面的。
Graphics Stack
绘制屏幕的过程中又很多都是不被人了解的。但是一旦像素被绘制到屏幕上面,那么像素就是有3种颜色组成:红绿蓝。这3个颜色单元通过特定的强弱组合形成一个特定的颜色。对于iPhone5 IPS_LCD 的分辨率是1,136×640 = 727,040个像素,也就是有2,181,120个颜色单元。对于一个15寸高清屏幕的MacBook Pro来说,这个数字差不多是1500万。Graphics Stack 就是确保每一个单元的强弱都正确。当滑动整个屏幕的时候,上百万的颜色单元需要在每秒60次的更新。
The Software Components
下面是一个简单的例子,整个软件看起来是这个样子:
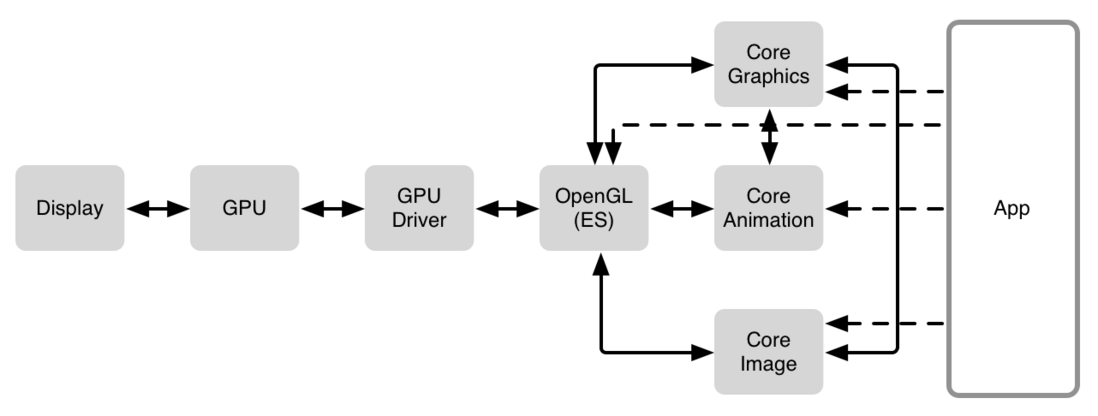
显示器上面的就是GPU,图像处理单元。GPU是一个高度并发计算的硬件单元,特别是处理图形图像的并行计算。这就是为什么可以这么快的更新像素并输出到屏幕的原因。并行计算的设计让GPU可以高效的混合图像纹理。我们会在后面详细解释混合图像纹理这个过程。现在需要知道的就是GPU是被高度优化设计的,因此非常适合计算图像这种类型的工作。他比CPU计算的更快,更节约能耗。因为CPU是为了更一般的计算设计的硬件。CPU虽然可以做很多事情,但是在图像这方面还是远远慢于GPU。
GPU驱动是一些直接操作GPU的代码,由于各个GPU是不同的,驱动在他们之上创建一个层,这个层通常是OpenGL/OpenGL ES。
OpenGL(Open Graphics Library)是用来做2D和3G图形图像渲染的API。由于GPU是一个非常定制化的硬件,OpenGL和GPU紧密合作充分发挥GPU的能力来实现图形图像渲染硬件加速。对大多数情况,OpenGL太底层了。但是当1992年第一个版本发布后(20多年前),它就成为主流的操作GPU的方式,并且前进了一大步。因为程序员再也不用为了每一个GPU编写不同的应用程序。
在OpenGL上面,分开了几个。iOS设备几乎所有的东西变成了Core Animation,但是在OSX,绕过Core Animation而使用Core Graphic 并不是不常见。有一些特别的应用程序,特别是游戏,可能直接使用OpenGL/OpenGL ES. 然后事情变得让人疑惑起来,因为有些渲染Core Animation 使用 Core Graphic。类似AVFoundation, Core Image 这样的框架,或是其他的一些混合的方式。
这里提醒一件事情, GPU是一个强有力的图形图像硬件,在显示像素方面起着核心作用。它也连接着CPU。从硬件方面讲就是有一些总线把他们连接了起来。也有一些框架比如 OpenGL, Core Animation。Core Graphic控制GPU和CPU之间的数据传输。为了让像素能够显示到屏幕上面,有一些工作是需要CPU的。然后数据会被传给GPU,然后数据再被处理,最后显示到屏幕上面。
每一个过程中都有自己的挑战,在这个过程中也存在很多权衡。
硬件层
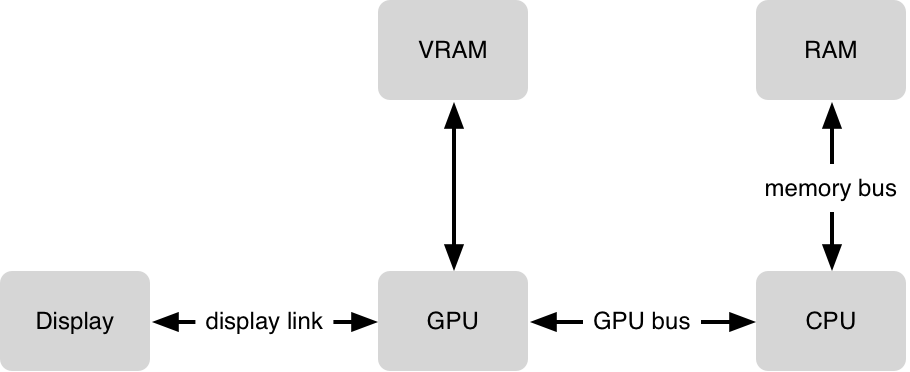
这是一个很简单的图表用来描述一个挑战。GPU有纹理(位图)合成为一帧(比如1秒60帧)每一个纹理占用VRAM(显卡)因此GPU一次处理的纹理有大小限制。GPU处理合成方面非常高效,但是有一些合成任务比其他要复杂,所以GPU对处理能力有一个不能超过16.7ms的限制(1秒60帧)。
另一个挑战是把数据传给GPU。为了让GPU能够访问数据,我们需要把数据从内存复制到显存。这个过程叫做上传到GPU。这个可能看上去不重要,但是对于一个大的纹理来说,会非常耗时。
最后CPU运行程序。你可能告诉CPU从资源文件夹中加载一个PNG图片,并解压。这些过程都发生在CPU。当需要显示这些解压的图片时,就需要上传数据到GPU。一些事情看似非常简单,比如显示一段文字,对CPU来说是一个非常复杂的任务。需要调用Core Text 和 Core Graphic框架去根据文字生成一个位图。完成后,以纹理的方式上传到GPU,然后准备显示。当你滑动或是移动一段屏幕上面的文字时,同样的纹理会被重用,CPU会简单的告诉GPU只是需要一个新的位置,所以GPU可以重新利用现有的纹理。CPU不需要重新绘制文字,位图也不需要重新上传到GPU。
上面的有一点复杂,在有一个整体概念之后,我们会开始解释里面的技术细节。
图像合成
图像合成的字面意思就是把不同的位图放到一起创建成最后的图像然后显示到屏幕上面。在很多方面来看,这个过程都是显而易见的,所以很容易忽视其中的复杂性和运算量。
让我们忽视一些特殊情况,假设屏幕上面都是纹理。纹理就是一个RGBA值的矩形区域。每一个像素包括红,绿,蓝,透明度。在Core Animation世界里面,基本上相当于CALayer。
在这个简单的假设中,每一个层是一个纹理,所有的纹理通过栈的方式排列起来。屏幕上的每一个像素,CPU都需要明白应该如何混合这些纹理,从而得到相对应的RGB值。这就是合成的过程。
如果我们只有一个纹理,而且这个纹理和屏幕大小一致。每一个像素就和纹理中得一个像素对应起来。也就是说这个纹理的像素就是最后屏幕显示的样子。
如果我们有另一个纹理,这个纹理覆盖在之前的纹理上面。GPU需要首先把第二个纹理和第一个纹理合成。这里面有不同的覆盖模式,但是如果我们假设所有的纹理都是像素对齐且我们使用普通的覆盖模式。那么最后的颜色就是通过下面的公式计算出来的。
R = S + D * (1 - Sa)
最后的结果是通过源的颜色(最上面的纹理)加目标颜色(下面的纹理) 乘以(1 – 源颜色的透明度)公式里面所有的颜色就假定已经预先乘以了他们的透明度。
很显然,这里面很麻烦。让我们再假设所有的颜色都是不透明的,也就是alpha = 1. 如果目标纹理(下面的纹理)是蓝色的(RGB = 0,0,1)源纹理(上面的纹理)是红色(RGB = 1,0,0)。因为Sa = 1, 那么这个公式就简化为
R = S
结果就是源的红色,这个和你预期一致。
如果源(上面的)层50%透明,比如 alpha = 0,5. 那么 S 的RGB值需要乘以alpha会变成 (0.5,0,0)。这个公式会变成这个样子
0.5 0 0.5
R = S + D * (1 - Sa) = 0 + 0 * (1 - 0.5) = 0
0 1 0.5
我们最后得到的RGB颜色是紫色(0.5, 0, 0.5) 。这个和我们的直觉预期一致。透明和红色和蓝色背景混合后成为紫色。
要记住,这个只是把一个纹理中的一个像素和另一个纹理中的一个像素合成起来。GPU需要把2个纹理之间覆盖的部分中的像素都合成起来。大家都知道,大多数的app都有多层,因此很多纹理需要被合成起来。这个对GPU的开销很大,即便GPU已经是被高度硬件优化的设备。
不透明 VS 透明
当源纹理是完全不透明,最终的颜色和源纹理一样。这就可以节省GPU的很多工作,因为GPU可以简单的复制源纹理而不用合成所有像素值。但是GPU没有办法区别纹理中的像素是不透明的还是透明。只有程序员才能知道CALayer里面的到底是什么。这也就是CAlayer有opaque属性的原因。如果opaque = YES, 那么GPU将不会做任何合成计算,而是直接直接简单的复制颜色,不管下面还有什么东西。GPU可以减少大量的工作。这就是Instruments(Xcode 的性能测试工具)中 color blended layers 选项做的事情。(这个选项也在模拟器菜单里面)。它可以让你了解哪一个层(纹理)被标记成透明,也就是说,GPU需要做合成工作。合成不透明层要比透明的层工作量少很多,因为没有那么多的数学运算在里面。
如果你知道哪一个层是不透明的,那么一定确保opaque = YES。如果你载入一个没有alpha通道的image,而且在UIImageView显示,那么UIImageView会自动帮你设置opaque = YES。但是需要注意一个没有alpha通道的图片和每个地方的alpha都是100%的图片区别很大。后面的情况,Core Animation 需要假定所有像素的alpha都不是100%。在Finder中,你可以使用Get Info并且检查More Info部分。它将告诉你这张图片是否拥有alpha通道。
像素对齐和不对齐
到目前为止,我们考虑的层都是完美的像素对齐的。当所有的像素都对齐时,我们有一个相对简单的公式。当GPU判断屏幕上面的一个像素应该是什么时,只需要看一下覆盖在屏幕上面的所有层中的单个像素,然后把这些像素合成起来,或者如果最上面的纹理是不透明的,GPU只需要简单的复制最上面的像素就好了。
当一个层上面的所有像素和屏幕上面的像素完美对应,我们就说这个层是像素对齐的。主要有2个原因导致可能不对齐。第一个是放大缩小;当放大或是缩小是,纹理的像素和屏幕像素不对齐。另一个原因是当纹理的起点不在一个像素边界上。
这2种情况,GPU不得不做额外的计算。这个需要从源纹理中混合很多像素来创建一个像素用来合成。当所有像素对齐时,GPU就可以少做很多工作。
注意,Core Animation Instrument和模拟器都有color misaligned images 选项,当CALayer中存在像素不对齐的时候,把问题显示出来。
遮罩(mask)
一个层可以有一个和它相关联的遮罩。遮罩是一个有alpha值的位图,而且在合成像素之前需要被应用到层的contents属性上。当你这顶一个层为圆角时,一就在设置一个遮罩在这个层上面。然而,我们也可以指定一个任意的遮罩。比如我们有一个形状像字母A的遮罩。只有CALayer的contents中的和字母A重合的一部分被会被绘制到屏幕。
离屏渲染(Offscreen rendering)
离屏渲染可以被Core Animation 自动触发或是应用程序手动触发。离屏渲染绘制layer tree中的一部分到一个新的缓存里面(这个缓存不是屏幕,是另一个地方),然后再把这个缓存渲染到屏幕上面。
你可能希望强制离屏渲染,特别是计算很复杂的时候。这是一种缓存合成好的纹理或是层的方式。如果你的呈现树(render tree)是复杂的。那么就希望强制离屏渲染到缓存这些层,然后再使用缓存合成到屏幕。
如果你的APP有很多层,而且希望增加动画。GPU一般来说不得不重新合成所有的层在1秒60帧的速度下。当使用离屏渲染时,GPU需要合成这些层到一个新的位图纹理缓存里面,然后再用这个纹理绘制到屏幕上面。当这些层一起移动时,GPU可以重复利用这个位图缓存,这样就可以提高效率。当然,如果这些层没有修改的化,才能有效。如果这些层被修改了,GPU就不得不重新创建这个位图缓存。你可以触发这个行为,通过设置shouldRasterize = YES
这是一个权衡,如果只是绘制一次,那么这样做反而会更慢。创建一个额外的缓存对GPU来说是一个额外的工作,特别是如果这个位图永远没有被复用。这个实在是太浪费了。然而,如果这个位图缓存可以被重用,GPU也可能把缓存删掉了。所以你需要计算GPU的利用率和帧的速率来判断这个位图是否有用
离屏渲染也可以在一些其他场景发生。如果你直接或是间接的给一个层增加了遮罩。Core Animation 会为了实现遮罩强制做离屏渲染。这个增加了GPU的负担,因为一般上来,这些都是直接在屏幕上面渲染的。
Instrument的Core Animation 有一个叫做Color Offscreen-Rendered Yellow的选项。它会将已经被渲染到屏幕外缓冲区的区域标注为黄色(这个选项在模拟器中也可以用)。同时确保勾选Color Hits Green and Misses Red选项。绿色代表无论何时一个屏幕外缓冲区被复用,而红色代表当缓冲区被重新创建。
一般来说,你需要避免离屏渲染。因为这个开销很大。在屏幕上面直接合成层要比先创建一个离屏缓存然后在缓存上面绘制,最后再绘制缓存到屏幕上面快很多。这里面有2个上下文环境的切换(切换到屏幕外缓存环境,和屏幕环境)。
所以当你打开Color Offscreen-Rendered Yellow后看到黄色,这便是一个警告,但这不一定是不好的。如果Core Animation能够复用屏幕外渲染的结果,这便能够提升性能,当绘制到缓存上面的层没有被修改的时候,就可以被复用了。
注意,缓存位图的尺寸大小是有限制的。Apple 提示大约是2倍屏幕的大小。
如果你使用的层引发了离屏渲染,那么你最好避免这种方式。增加遮罩,设置圆角,设置阴影都造成离屏渲染。
对于遮罩来说,圆角只是一个特殊的遮罩。clipsToBounds 和 masksToBounds 2个属性而已。你可以简单的创建一个已经设置好遮罩的层创建内容。比如,使用已经设置了遮罩的图片。当然,这个也是一种权衡。如果你希望在层的contents属性这只一个矩形的遮罩,那你更应该使用contentsRect而不是使用遮罩。
如果你最后这是shouldRasterize = YES,记住还要设置rasterizationScale = contentsScale
更多的关于合成
通常,维基百科上面有许多关于图像合成的背景知识。我们这里简单的拓展一下像素中的红、绿、蓝以及alpha是如何呈现在内存中的。
OSX
如果你在OSX上面工作,你会发现大部分的这些调试选项在一个独立的叫做“Quartz Debug”的程序里面。而并不在 Instruments 中。Quartz Debug是Graphics Tools中的一部分,这可以在苹果的developer portal中下载到。
Core Animation & OpenGL ES
就像名字所建议的那样,Core Animation 让我们可以创建屏幕动画。我们将跳过大部分的动画,关注于绘制部分。重要的是,Core Animation允许你坐高效的渲染。这就是为什么你可以通过Core Animation 实现每秒60帧的动画。
Core Animation 的核心就是基于OpenGL ES的抽象。简单说,它让你使用OpenGL ES的强大能力而不需要知道OpenGL ES的复杂性。当我讨论像素合成的时候,我们提到的层(layer)和 纹理(texture)是等价的。他们准确来说不是一个东西,但是缺非常类似。
Core Animation的层可以有多个子层。所以最后形成了一个layer tree。Core Animation做的最复杂的事情就是判断出那些层需要被绘制或重新绘制,那些层需要OpenGL ES 去合成到屏幕上面。
例如,当你这是一个layer的contents属性是一个CGImageRef时,Core Animation创建一个OpenGL 纹理,然后确保这个图片中的位图上传到指定的纹理中。或者,你重写了-drawInContext方法,Core Animation 会分配一个纹理,确保你的Core Graphics的调用将会被作用到这个纹理中。层的 性质和CALayer的子类会影响OpenGL渲染方式的效率。很多底层的OpenGL ES行为被简单的封装到容易理解的CALayer的概念中去。
Core Animation通过Core Graphics和OpenGL ES,精心策划基于CPU的位图绘制。因为Core Animation在渲染过程中处于非常重要的地位,所以如何使用Core Animation,将会对性能产生极大影响。
CPU限制 vs GPU限制(CPU bound vs. GPU bound)
当在屏幕上面显示的时候,有很多组件都参与其中。这里面有2个主要的硬件分别是CPU和GPU。P和U的意思就是处理单元。当东西被显示到屏幕上面是,CPU和GPU都需要处理计算。他们也都受到限制。
为了能够达到每秒60帧的效果,你需要确保CPU和GPU都不能过载。也就是说,即使你当前能达到60fps,你还是要尽可能多的绘制工作交给GPU做。CPU需要做其他的应用程序代码,而不是渲染。通常,GPU的渲染性能要比CPU高效很多,同时对系统的负载和消耗也更低一些。
因为绘制的性能是基于GPU和CPU的。你需要去分辨哪一个是你绘制的瓶颈。如果你用尽的GPU的资源,GPU是性能的瓶颈,也就是绘制是GPU的瓶颈,反之就是CPU的瓶颈。
如果你是GPU的瓶颈,你需要为GPU减负(比如把一些工作交给CPU),反之亦然。
如果是GPU瓶颈,可以使用OpenGL ES Driver instrument,然后点击 i 按钮。配置一下,同时注意查看Device Utilization % 是否被选中。然后运行app。你会看到GPU的负荷。如果这个数字接近100%,那么你交给GPU的工作太多了。
CPU瓶颈是更加通常的问题。可以通过Time Profiler instrument,找到问题所在。
Core Graphics / Quartz 2D
通过Core Graphics这个框架名字,Quartz 2D更被人所知。
Quartz 2D 有很多小功能,我们不会在这里提及。我们不会讲有关PDF创建,绘制,解析或打印。只需要了解答应PDF和创建PDF和在屏幕上面绘制位图原理几乎一致,因为他们都是基于Quartz 2D。
让我们简单了解一下Quartz 2D的概念。更多细节可以参考 Apple 的 官方文档。
Quartz 2D是一个处理2D绘制的非常强大的工具。有基于路径的绘制,反锯齿渲染,透明图层,分辨率,并且设备独立等很多特性。因为是更为底层的基于C的API,所以看上去会有一点让人恐惧。
主要概念是非常简单的。UIKit和AppKit都封装了Quartz 2D的一些简单API,一旦你熟练了,一些简单C的API也是很容易理解的。最后你可以做一个引擎,它的功能和Photoshop一样。Apple提到的一个 APP,就是一个很好的Quartz 2D例子。
当你的程序进行位图绘制时,不管使用哪种方式,都是基于Quartz 2D的。也就是说,CPU通过Quartz 2D绘制。尽管Quartz可以做其他事情,但是我们这里还是集中于位图绘制,比如在缓存(一块内存)绘制位图会包括RGBA数据。
比方说,我们要画一个八角形,我们通过UIKit能做到这一点
UIBezierPath *path = [UIBezierPath bezierPath];
[path moveToPoint:CGPointMake(16.72, 7.22)];
[path addLineToPoint:CGPointMake(3.29, 20.83)];
[path addLineToPoint:CGPointMake(0.4, 18.05)];
[path addLineToPoint:CGPointMake(18.8, -0.47)];
[path addLineToPoint:CGPointMake(37.21, 18.05)];
[path addLineToPoint:CGPointMake(34.31, 20.83)];
[path addLineToPoint:CGPointMake(20.88, 7.22)];
[path addLineToPoint:CGPointMake(20.88, 42.18)];
[path addLineToPoint:CGPointMake(16.72, 42.18)];
[path addLineToPoint:CGPointMake(16.72, 7.22)];
[path closePath];
path.lineWidth = 1;
[[UIColor redColor] setStroke];
[path stroke];
Core Graphics 的代码差不多:
CGContextBeginPath(ctx);
CGContextMoveToPoint(ctx, 16.72, 7.22);
CGContextAddLineToPoint(ctx, 3.29, 20.83);
CGContextAddLineToPoint(ctx, 0.4, 18.05);
CGContextAddLineToPoint(ctx, 18.8, -0.47);
CGContextAddLineToPoint(ctx, 37.21, 18.05);
CGContextAddLineToPoint(ctx, 34.31, 20.83);
CGContextAddLineToPoint(ctx, 20.88, 7.22);
CGContextAddLineToPoint(ctx, 20.88, 42.18);
CGContextAddLineToPoint(ctx, 16.72, 42.18);
CGContextAddLineToPoint(ctx, 16.72, 7.22);
CGContextClosePath(ctx);
CGContextSetLineWidth(ctx, 1);
CGContextSetStrokeColorWithColor(ctx, [UIColor redColor].CGColor);
CGContextStrokePath(ctx);
问题就是,绘制到哪里呢? 这就是CGContext做的事情。我们传递的ctx这个参数。这个context定义了我们绘制的地方。如果我们实现了CALayer的-drawInContext:方法。我们传递了一个参数context。在context上面绘制,最后会在layer的一个缓存里面。我们也可以创建我们自己的context,比如 CGBitmapContextCreate()。这个函数返回一个context,然后我们可以传递这个context,然后在刚刚创建的这个context上面绘制。
这里我们发现,UIKit的代码并没有传递context。这是因为UIKit或AppKit的context是隐形的。UIKit和UIKit维护着一个context栈。这些UIKit的方法始终在最上面的context绘制。你可以使用UIGraphicsPushContext()和 UIGraphicsPopContext()来push和pop对应的context。
UIKit有一个简单的方式,通过 UIGraphicsBeginImageContextWithOptions() 和 UIGraphicsEndImageContext()来创建一个位图context,和 CGBitmapContextCreate()一样。混合UIKit和 Core Graphics调用很简单。
UIGraphicsBeginImageContextWithOptions(CGSizeMake(45, 45), YES, 2);
CGContextRef ctx = UIGraphicsGetCurrentContext();
CGContextBeginPath(ctx);
CGContextMoveToPoint(ctx, 16.72, 7.22);
CGContextAddLineToPoint(ctx, 3.29, 20.83);
...
CGContextStrokePath(ctx);
UIGraphicsEndImageContext();
或其他方式
CGContextRef ctx = CGBitmapContextCreate(NULL, 90, 90, 8, 90 * 4, space, bitmapInfo);
CGContextScaleCTM(ctx, 0.5, 0.5);
UIGraphicsPushContext(ctx);
UIBezierPath *path = [UIBezierPath bezierPath];
[path moveToPoint:CGPointMake(16.72, 7.22)];
[path addLineToPoint:CGPointMake(3.29, 20.83)];
...
[path stroke];
UIGraphicsPopContext(ctx);
CGContextRelease(ctx);
通过 Core Graphics可以做很多有趣的事情。苹果的文档有很多例子,我们这里就不太细说他们了。但是Core Graphics有一个非常接近Adobe Illustrator和Adobe Photoshop如何工作的绘图模型,并且大多数工具的理念翻译成Core Graphics了。毕竟这就是NextStep一开始做的。
CGLayer
一件非常值得提起的事,便是CGLayer。它经常被忽视,并且它的名字有时会造成困惑。他不是Photoshop中的图层的意思,也不是Core Animation中的层的意思。
把CGLayer想象成一个子context。它共用父context的所有特性。你可以独立于父context,在它自己的缓存中绘制。并且因为它跟context紧密的联系在一起,CGLayer可以被高效的绘制到context中。
什么时候这将变得有用呢?如果你用Core Graphics来绘制一些相当复杂的,并且部分内容需要被重新绘制的,你只需将那部分内容绘制到CGLayer一次,然后便可绘制这个CGLayer到父context中。这是一个非常优雅的性能窍门。这和我们前面提到的离屏绘制概念有点类似。你需要做出权衡,是否需要为CGLayer的缓存申请额外的内存,确定这是否对你有所帮助。
像素(Pixels)
屏幕上面的像素是通过3个颜色组成的:红,绿,蓝。因此位图数据有时候也被成为RGB数据。你可能想知道这个数据在内存中是什么样子。但是实际上,有非常非常多的方式。
后面我们会提到压缩,这个和下面讲得完全不一样。现在我们看一下RGB位图数据。RGB位图数据的每一个值有3个组成部分,红,绿,蓝。更多的时候,我们有4个组成部分,红,绿,蓝,alpha。这里我们讲4个组成部分的情况。
默认的像素布局
iOS和OS X上面的最通常的文件格式是32 bits-per-pixel (bpp),8 bits-per-component (bpc),alpha会被预先计算进去。在内存里面像这个样子
A R G B A R G B A R G B
| pixel 0 | pixel 1 | pixel 2
0 1 2 3 4 5 6 7 8 9 10 11 ...
这个格式经常被叫做ARGB。每一个像素使用4个字节,每一个颜色组件1个字节。每一个像素有一个alpha值在R,G,B前面。最后RGB分别预先乘以alpha。如果我们有一个橘黄的颜色。那么看上去就是 240,99,24. ARGB就是 255,240,99,24 如果我们有一个同样的颜色,但是alpha是0.33,那么最后的就是 ARGB就是 84,80,33,8
另一个常见的格式是32bpp,8bpc,alpha被跳过了:
x R G B x R G B x R G B
| pixel 0 | pixel 1 | pixel 2
0 1 2 3 4 5 6 7 8 9 10 11 ...
这个也被称为xRGB。像素并没有alpha(也就是100%不透明),但是内存结构是相同的。你可能奇怪为什么这个格式很流行。因为如果我们把这个没用的字节从像素中去掉,我们可以节省25%的空间。实际上,这个格式更适合现代的CPU和图像算法。因为每一个独立的像素和32字节对齐。现代CPU不喜欢读取不对其的数据。算法会处理大量的位移,特别是这个格式和ARGB混合在一起的时候。
当处理xRGB时,Core Graphic也需要支持把alpha放到最后的格式,比如RGBA,RGBx(RGB已经预先乘以alpha的格式)
深奥的布局
大多数时候,当我们处理位图数据时,我们就在使用Core Graphic 或是 Quartz 2D。有一个列表包括了所有的支持的文件格式。让我们先看一下剩余的RGB格式。
有16bpp,5bpc,不包括alpha。这个格式比之前节省50%空间(2个字节一个像素)。但是如果解压成RGB数据在内存里面或是磁盘上面就有用了。但是,因为只有5个字节一个像素,图像特别是一些平滑的渐变,可能就混合到一起了。(图像质量下降)。
还有一个是64bpp,16bpc,最终为128bpp,32bpc,浮点数组件(有或没有alpha值)。它们分别使用8字节和16字节,并且允许更高的精度。当然,这会造成更多的内存和更复杂的计算。
最后,Core Graphics 也支持一些其他格式,比如CMYK,还有一些只有alpha的格式,比如之前提到的遮罩。
平面数据 (Planar Data color plane)
大多数的框架(包括 Core Graphics)使用的像素格式是混合起来的。这就是所谓的 planar components, or component planes。每一个颜色组件都在内存中的一个区域。比如,对于RGB数据。我们有3个独立的内存空间,分别保存红色,绿色,和蓝色的数值。
在某些情况下,一些视频框架会使用 Planar Data。
YCbCr
YCbCr 是一个常见的视频格式。同样有3个部分组成(Y,Cb,Cr)。但是它更倾向于人眼识别的颜色。人眼是很难精确识别出来Cb和Cr的色彩度。但是却能很容易识别出来Y的亮度。在相同的质量下,Cb和Cr要比Y压缩的更多。
JPEG有时候把RGB格式转换为YCbCr格式。JPEG单独压缩每一个color plane。当压缩YCbCr格式时,Cb和Cr比Y压缩得更好。
图片格式
iOS和OSX上面的大多数图片都是JPEG和PNG格式。下面我们再了解一下。
JPEG
每个人都知道JPEG,他来自相机。他代表了图片是图和存储在电脑里,即时是你的妈妈也听过JPEG。
大家都认为JPEG就是一个像素格式。就像我们之前提到的RGB格式一样,但是实际上并不是这样。
真正的JPEG数据变成像素是一个非常复杂的过程。一个星期都没有办法讲清楚,或是更久。对于一个color plane, JPEG使用一种离散余弦变换的算法。讲空间信息转换为频率(convert spatial information into the frequency domain)。然后通过哈夫曼编码的变种来压缩。一开始会把RGB转换成YCbCr,解压缩的时候,再反过来。
这就是为什么从一个JPEG文件创建一个UIImage然后会知道屏幕上面会有一点点延迟的原因。因为CPU正在忙于解压图片。如果每个TableViewCell都需要解压图片的话,那么你的滚动效果就不会平滑。
那么,为什么使用JPEG文件呢?因为JPEG可以把图片压缩的非常非常好。一个没有压缩过的IPhone5拍照的图片差不多24MB。使用默认的压缩设置,这个只有2-3MB。JPEG压缩效果非常好,因为几乎没有损失。他把那些人眼不能识别的部分去掉了。这样做可以远远的超过gzip这样的压缩算法。但是,这个仅仅在图片上面有效。因为,JPEG依赖于丢掉那些人眼无法识别的数据。如果你从一个基本是文本的网页截取一张图片,JPEG就不会那么高效,压缩效率会变得低下。你甚至都可以看出图片已经变形了。
PNG
PNG读作“ping”,和JPEG相反,他是无损压缩的。当你保存图片成PNG时,然后再打开。所有的像素数据和之前的完全一样。因为有这个限制,所有PNG压缩图片的效果没有JPEG那么好。但是对于app中的设计来说,比如按钮,icon,PNG就非常适合。而且PNG的解码工作要比JPEG简单很多。
在真实的世界里面,事情没有这么简单。有很多不同的PNG格式。维基百科上面有很多细节。但是简单说,PNG支持压缩有alpha或是没有alpha通道的RGB像素,这也就是为什么他适合app上面的原因。
格式挑选
当在app中使用颜色是,你需要使用者2种格式中得一个,PNG和JPEG。他们的解码和压缩算法都是被高度硬件优化的。有些情况甚至支持并行计算。同时Apple也在不断地提高解码的能力在未来的操作系统版本中。如果使用其他格式,这可能会对你的程序性能产生影响,而且可能会产生漏洞,因为图像解码的算法是黑客们最喜欢攻击的目标。
已经讲了好多有关PNG的优化了,你可以在互联网上面自己查找。这里需要注意一点,Xcode的压缩算法和大部分的压缩引擎不一样。
当Xcode压缩png时,技术上来说,已经不是一个有效的PNG文件了。但是iOS系统可以读取这个文件,然后比通常的PNG图片处理速度更快。Xcode这样做,是为了更好地利用解码算法,而这些解码算法不能在一般的PNG文件上面适用。就像上面提到的,有非常多的方法去表示RGB数据。而且如果这个格式不是iOS图形图像系统需要的,那么就需要增加额外的计算。这样就不会有性能上的提高了。
再抢到一次,如果你可以,你需要设置 resizable images。你的文件会变得更小,因此,这样就会有更小的文件需要从文件系统里面读取,然后在解码。
UIKit and Pixels
UIKit中得每一个view都有自己的CALayer,一般都有一个缓存,也就是位图,有一点类似图片。这个缓存最后会被绘制到屏幕上面。
With -drawRect:
如果你的自定义view的类实现了-drawRest:,那么就是这样子工作的:
当你调用-setNeedsDisplay时,UIKit会调用这个view的层的 -setNeedsDisplay方法。这个设置一个标记,表明这个层已经脏了(dirty,被修改了)。实际上,并没有做任何事情,所以,调用多次-setNeedsDisplay 没有任何问题。
当渲染系统准备好后,会调用层的-display方法。这时,层会设置缓存。然后设置缓存的Core Graphics的上下文环境(CGContextRef)。后面的绘制会通过这个CGContextRef绘制到缓存中。
当你调用UIKit中的函数,比如UIRectFill() 或者 -[UIBezierPath fill]时,会通过这个CGContextRef调用你的drawRect方法。他们是通过把上面的CGContextRef push 到 图形图像堆栈中,也就是设置成当前的上下文环境。UIGraphicsGetCurrent()会返回刚才push的那个context。由于UIKit绘制方法使用UIGraphicsGetCurrent(),所以这些绘制会被绘制到缓存中。如果你希望直接使用 Core Graphics 方法,那么你需要调用UIGraphicsGetCurrent()方法,然后自己手动传递context参数到Core Graphics的绘制函数中去。
那么,一个个层的缓存都会被绘制到屏幕上面,知道下一次设置-setNeedsDisplay,然后再重新更新缓存,再重复上面的过程。
不使用 drawRect
当你使用UIImageView的时候,有一点点的不同。这个view依然包含一个CALayer,但是这个层并不会分配一个缓存空间。而是使用CGImageRef作为CALayer的contents属性,渲染系统会把这个图片绘制到帧的缓存,比如屏幕。
这个情况下,就没有继续绘制的过程了。我们就是简单的通过传递位图这种方式把图片传递给UIImageView,然后传递给Core Animation,然后传递给渲染系统。
使用drawRect 还是不使用drawRect
听上去不怎么样,但是,最快速的方法,就是不使用。
大多数情况,你可以通过自定义view或是组合其他层来实现。可以看一下Chris的文章,有关自定义控件。这个方法是推荐的,因为UIKit非常高效。
当你需要自定义绘制的时候 WWDC2012 session 506 Optimizing 2D Graphics and Animation Performance是一个非常好的例子 。
另一个地方需要自定义绘制的是iOS的股票软件。这个股票图是通过Core Graphics实现的。注意,这个只是你需要自定义绘制,并不是一定要实现drawRect函数,有时候通过UIGraphicsBeginImageContextWithOptions()或是 CGBitmapContextCreate()创建一个额外的位图,然后再上面绘制图片,然后传递给CALayer的contents会更容易。下面有一个测试例子
单色
这是一个简单的例子
// Don't do this
- (void)drawRect:(CGRect)rect
{
[[UIColor redColor] setFill];
UIRectFill([self bounds]);
}
我们知道为什么这样做很烂,我们让Core Animation创建了一个额外的缓存,然后我们让Core Graphics 在缓存上面填充了一个颜色。然后上传给了GPU。
我们可以不实现-drawRect:函数来省去这些步骤。只是简单的设置view的backgroundColor就好了。如果这个view有CAGradientLayer,那么同样的方法也可以设置成渐变的颜色。
可变大小的图片(resizable image)
你可以简单的通过可变大小的图片减少图形系统的工作压力。如果你原图上面的按钮大小是300*50。那么就有 600 * 100 = 60k 像素 * 4 = 240KB的内存数据需要传递给GPU。传递给显存。如果我们使用resizable image。我们可以使用一个 52 * 12 大小的图片,这样可以节省10kb的内存。这样会更快。
Core Animation 通过 contentsCenter 来resize图片,但是,更简单的是通过 -[UIImage resizableImageWithCapInsets:resizingMode:]。
而且,在第一次绘制的时候,我们并不需要从文件系统读取60K像素的PNG文件,然后解码。越小的图片解码越快。这样,我们的app就可以启动的更快。
并发绘制
上一个我们讲到了并发。UIKit的线程模型非常简单,你只能在主线程使用UIKit。所以,这里面还能有并发的概念?
如果你不得不实现-drawRect:,并且你必须绘制大量的东西,而这个会花费不少时间。而且你希望动画变得更平滑,除了在主线程中,你还希望在其他线程中做一些工作。并发的绘图是复杂的,但是除了几个警告,并发的绘图还是比较容易实现的。
你不能在CAlayer的缓存里面做任何事情出了主线程,否则不好的事情会发生。但是你可以在一个独立的位图上面绘制。
所有的Core Graphics的绘制方法需要一个context参数,指定这个绘制到那里去。UIKit有一个概念是绘制到当前的context上。而这个当前的context是线程独立的。
为了实现异步绘制,我们做下面的事情。我们在其他队列(queue,GCD中的概念)中创建一个图片,然后我们切换到主队列中把结果传递给UIImageView。这个技术被 WWDC 2012 session 211中提到
- (UIImage *)renderInImageOfSize:(CGSize)size;
{
UIGraphicsBeginImageContextWithOptions(size, NO, 0);
// do drawing here
UIImage *result = UIGraphicsGetImageFromCurrentImageContext();
UIGraphicsEndImageContext();
return result;
}
这个函数通过UIGraphicsBeginImageContextWithOptions 创建一个新的CGContextRef。这个函数也修改了当前的UIKit的context。然后可以铜鼓UIKit的方法绘制,然后通过UIGraphicsGetImageFromCurrentImageContext()根据位图数据生成一个UIImage。然后关闭掉创建的这个context。
保证线程安全是非常重要的,比如你访问UIKit的属性,必须线程安全。如果你在其他队列调用这个方法,而这个方法在你的view类里面,这个事情就可能古怪了。更简单的方法是创建一个独立的渲染类,然后当触发绘制这个图片的时候才设置这些必须得属性。
但是UIKit的绘制函数是可以在其他队列中调用的,只需要保证这些操作在 UIGraphicsBeginImageContextWithOptions() 和 UIGraphicsEndImageContext ()之前就好。
你可以通过下面的方法触发绘制
UIImageView *view; // assume we have this
NSOperationQueue *renderQueue; // assume we have this
CGSize size = view.bounds.size;
[renderQueue addOperationWithBlock:^(){
UIImage *image = [renderer renderInImageOfSize:size];
[[NSOperationQueue mainQueue] addOperationWithBlock:^(){
view.image = image;
}];
}];
注意view.image = image; 必须在主队列调用。这是非常重要的细节。你不能在其他队列中调用。
通常来说,异步绘制会带来很多复杂度。你需要实现取消绘制的过程。你还需要限制异步操作的最大数目。
所以,最简单的就是通过NSOperation的子类来实现renderInImageOfSize方法。
最后,有一点非常重要的就是异步设置UITableViewCell 的content有时候很诡异。因为当异步绘制结束的时候,这个Cell很可能已经被重用到其他地方了。
CALayer的奇怪和最后
现在你是到了CALayer某种程度上很像GPU中的纹理。层有自己的缓存,缓存就是一个会被绘制到屏幕上的位图。 大多数情况,当你使用CALayer时,你会设置contents属性给一个图片。这个意思就是告诉 Core Animation,使用这个图片的位图数据作为纹理。 如果这个图片是PNG或JPEG,Core Animation 会解码,然后上传到GPU。
当然,还有其他种类的层,如果你使用CALayer,不设置contents,而是这事background color, Core Animation不会上传任何数据给GPU,当然这些工作还是要被GPU运算的,只是不需要具体的像素数据,同理,渐变也是一个道理,不需要把像素上传给GPU。
图层和自定义绘制
如果CALayer或是子类实现了 -drawInContext 或是-drawLayer:inContext delegate。Core Animation会为这个layer创建一个缓存,用来保存这些函数中绘制的结果。这些代码是在CPU上面运行的,结果会被传递给GPU。
形状和文本层(Shape and Text Layers)
形状和文本层会有一点不同。首先,Core Animation 会为每一个层生成一个位图文件用来保存这些数据。然后Core Animation 会绘制到layer的缓存上面。如果你实现了-drawInContext方法,结果和上面提到的一样。最后性能会受到很大影响。
当你修改形状层或是文本层导致需要更新layer的缓存时,Core Animation会重新渲染缓存,比如。当实现shape layer的大小动画时,Core Animation会在动画的每一帧中重新绘制形状。
异步绘制
CALayer 有一个属性是 drawsAsynchronously。这个似乎看上去很不错,可以解决所有问题。实际上虽然可能会提高效率,但是可能会让事情更慢。
当你设置 drawsAsynchronously = YES 后,-drawRect: 和 -drawInContext: 函数依然实在主线程调用的。但是所有的Core Graphics函数(包括UIKit的绘制API,最后其实还是Core Graphics的调用)不会做任何事情,而是所有的绘制命令会被在后台线程处理。
这种方式就是先记录绘制命令,然后在后台线程执行。为了实现这个过程,更多的事情不得不做,更多的内存开销。最后只是把一些工作从主线程移动出来。这个过程是需要权衡,测试的。
这个可能是代价最昂贵的的提高绘制性能的方法,也不会节省很多资源。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号