数据解析
上次内容总结
requests作用:模拟浏览器发起请求
urllib:requests的前身
requests模块的编码流程:
- 指定url
- 发起请求:
- get(url,params,headers)
- post(url,data,headers)
- 获取响应数据
- 持久化存储
参数动态化:
- 有些情况下我们是需要将请求参数进行更改。将get或者post请求对应的请求参数封装到一个字典(键值对==请求参数)中,然后将改字典作用到get方法的params参数中或者作用到psot方法的data参数中
UA检测(反爬机制):
- 什么是UA:请求载体的身份标识。服务器端会检测请求的UA来鉴定其身份。
- 反反爬策略:UA伪装。通过抓包工具捕获某一款浏览器的UA值,封装到字典中,且将该字典作用到headers参数中
动态加载的数据:通过另一个单独的请求请求到的数据
对一个陌生的网站进行指定数据的爬取首先要确定爬取的数据在改网站中是否为动态加载的:
- 是:通过抓包工具实现全局搜索,定位动态加载数据对应的数据包,从数据包中提取请求的url和请求参数。
- 不是:就可以直接将浏览器地址栏中的网址作为我们requests请求的url
ip被封
多次爬取导致ip被封,浏览器无法访问网站临时解决方法:
- 进入浏览器搜索代理设置并打开
- 进入局域网(LAN)设置
- 选择为LAN使用代理服务器并录入代理服务器地址与端口
- 一些代理IP网站:
- http://www.goubanjia.com/
- https://www.kuaidaili.com/
- https://www.xicidaili.com/
- http://httpbin.org/
- http://www.dailiyun.com/
- 注意:网站中免费的代理服务器有可能会失效
- 此方法只能让浏览器可以再次访问网站,而爬虫程序依然使用的本机IP,所以不能解决爬虫访问问题。
爬取http://125.35.6.84:81/xk/
需求分析:
- 企业相关数据是由动态加载的
- 通过抓包工具实现全局搜索,定位动态加载数据包为portalAction.do?method=getXkzsList
- 查看数据包中的请求头,是POST请求,Request URL: http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsList
- 在Formm Data中找到请求参数
- 解析数据包的Response中Json数据并分析,没有找到企业详情页的url,但找到了每家企业的id。(json解析网址:https://www.sojson.com/)
- 进入企业详情页,找到数据包,发现为GET请求,每一家企业的详情页url域名都是一样的,只有请求参数id值不同
- 可以使用同一个域名结合不同企业的id值拼接成一家完整企业详情页url
- 再判断企业详情页的数据是否是动态加载的,通过抓包工具检测,发现企业详情页中信息也是动态加载的
- 通过抓包工具实现全局搜索,定位动态加载数据包为portalAction.do?method=getXkzsById
- 查看数据包中的请求头,是POST请求,Request URL: http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsById
- 解析数据包的Response中Json串并分析,即为我们想要的企业详情信息
- 在Formm Data中找到请求参数,发现请求参数为企业ID
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36"
}
# 获取每一家企业的ID
url = "http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsList"
for page in range(1,6): # 已过有354页,现只取前5页,一页15条数据
data = {
"on": "true",
"page": str(page),
"pageSize": "15",
"productName": "",
"conditionType": "1",
"applyname":"",
"applysn":"",
}
company_id = requests.post(url,headers=headers,data=data).json()
for dic in company_id['list']:
_id = dic['ID']
detail_url = "http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsById"
data = {
"id":_id
}
detail_data = requests.post(url=detail_url,data=data,headers=headers).json()
print("企业名称:"+detail_data['epsName'])
数据解析
数据解析的作用:可以帮助我们实现聚焦爬虫
数据解析的实现方式:
- 正则
- bs4
- xpath
- pyquery
数据解析的通用原理:聚焦爬虫爬取的数据都被存储在了相关的标签之中和相关标签的属性中。
- 定位标签
- 取文本或者取属性
正则解析
# 如何爬取图片
url = 'https://pic.qiushibaike.com/system/pictures/12338/123385529/medium/GRIJ2WLLDDCW69P4.jpg'
img_data = requests.get(url,headers=headers).content # 返回byte类型数据
with open('./img.jpg','wb') as fp:
fp.write(img_data)
# 或基于urllib,弊端:不能使用UA伪装
from urllib import request
url = 'https://pic.qiushibaike.com/system/pictures/12338/123385529/medium/GRIJ2WLLDDCW69P4.jpg'
request.urlretrieveieve(url,filename='./img.jpg')
糗图爬取1-3页所有的图片
urlhttps://www.qiushibaike.com/imgrank/
分析:
在浏览器页面跳转页数,查看每页地址栏对应的规律:第二页为
https://www.qiushibaike.com/imgrank/page/2/第三页为https://www.qiushibaike.com/imgrank/page/3/分析页面,找到页面对应的数据包,所搜页面内容,可以搜到。页面图片不是动态加载的
分析页面的html结构,找到想要图片img标签的结构规律
每个图片的img标签都在div标签中,div标签的类名为thumb
编写正则表达式,获取img表签里的src属性
import re
import os
dirName = './imgLibs'
if not os.path.exists(dirName):
os.mkdir(dirName)
# 设置一个通用的url模板
url = 'https://www.qiushibaike.com/imgrank/page/%d/'
# 使用通用爬虫将前3页对应的页面源码数据进行爬取
for page in range(1,4):
new_url = format(url%page)
# 每一个页码对应的页面源码数据
page_text = requests.get(new_url,headers=headers).text
# 在通用爬虫的基础上实现聚焦爬虫(每一个页码对应页面源码数据中解析出图片地址)
ex = '<div class="thumb">.*?<img src="(.*?)" alt.*?</div>'
# re.S 让.匹配任意内容,包括换行符
img_src_list = re.findall(ex,page_text,re.S)
for src in img_src_list:
src = 'https:'+src
img_name = src.split('/')[-1]
img_path = dirName+'/'+img_name #./imgLibs/xxxx.jpg
# 糗事百科没有设置UA检测,所以可以使用urllib爬取
request.urlretrieve(src,filename=img_path)
bs4解析
bs4解析的原理:
- 实例化一个BeautifulSoup的对象,需要将即将被解析的页面源码数据加载到该对象中
- 调用BeautifulSoup对象中的相关方法和属性进行标签定位和数据提取
环境的安装:
- pip install bs4
- pip install lxml
BeautifulSoup的实例化:
BeautifulSoup(fp,'lxml'):fp(文件句柄),将本地存储的一个html文档中的数据加载到实例化好的BeautifulSoup对象中BeautifulSoup(page_text,'lxml'):将从互联网上获取的页面源码数据加载到实例化好的BeautifulSoup对象中
<--新建一个test.html文件,练习对本地文件进行数据解析,html内容如下-->
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>测试bs4</title>
</head>
<body>
<div>
<p>百里守约</p>
</div>
<div class="song">
<p>李清照</p>
<p>王安石</p>
<p>苏轼</p>
<p>柳宗元</p>
<a href="http://www.song.com/" title="赵匡胤" target="_self">
<span>this is span</span>
宋朝是最强大的王朝,不是军队的强大,而是经济很强大,国民都很有钱</a>
<a href="" class="du">总为浮云能蔽日,长安不见使人愁</a>
<img src="http://www.baidu.com/meinv.jpg" alt="" />
</div>
<div class="tang">
<ul>
<li><a href="http://www.baidu.com" title="qing">清明时节雨纷纷,路上行人欲断魂,借问酒家何处有,牧童遥指杏花村</a></li>
<li><a href="http://www.163.com" title="qin">秦时明月汉时关,万里长征人未还,但使龙城飞将在,不教胡马度阴山</a></li>
<li><a href="http://www.126.com" alt="qi">岐王宅里寻常见,崔九堂前几度闻,正是江南好风景,落花时节又逢君</a></li>
<li><a href="http://www.sina.com" class="du">杜甫</a></li>
<li><a href="http://www.dudu.com" class="du">杜牧</a></li>
<li><b>杜小月</b></li>
<li><i>度蜜月</i></li>
<li><a href="http://www.haha.com" id="feng">凤凰台上凤凰游,凤去台空江自流,吴宫花草埋幽径,晋代衣冠成古丘</a></li>
</ul>
</div>
</body>
</html>
标签的操作
定位标签:soup.tagName,定位到第一个出现的tagName标签
属性定位:
soup.find('tagName',attrName='value')soup.find_all('tagName',attrName='value'),返回值为列表
选择器定位:
soup.select('选择器'),返回值是列表层级选择器:>表示一个层级 空格表示多个层级
取文本,返回的是字符串:
.string:获取直系的文本内容.text:获取所有的文本内容
取属性:tagName['attrName']
from bs4 import BeautifulSoup
fp = open('./test.html','r',encoding='utf-8')
soup = BeautifulSoup(fp,'lxml')
# soup 返回的是html源码
soup.div # 返回源码中第一次出现的div标签
# 标签类参数:class_
soup.find('div',class_='song') # 返回源码中第一次匹配的div标签
soup.find('a',id="feng") # 返回源码中第一次匹配的a标签
soup.find_all('div',class_="song") # 返回源码中所有匹配的div标签
soup.select('#feng')
soup.select('.tang > ul > li')
soup.select('.tang li') # 与上面的语句相同
a_tag = soup.select('#feng')[0]
a_tag.text # 获取的所有文本内容
div = soup.div
div.string # 获取直系的文本内容
div = soup.find('div',class_="song")
div.string
a_tag = soup.select('#feng')[0]
a_tag['href'] # 获取属性
爬取三国整篇内容
要求:
获取章节名称+章节内容
url = http://www.shicimingju.com/book/sanguoyanyi.html
fp = open('三国.txt','w',encoding='utf-8')
main_url = 'http://www.shicimingju.com/book/sanguoyanyi.html'
page_text = requests.get(main_url,headers=headers).text
# 解析出章节名称和章节详情页的url
soup = BeautifulSoup(page_text,'lxml')
# 返回的列表中存储的是一个个a标签
a_list = soup.select('.book-mulu > ul > li > a')
for a in a_list:
title = a.string
detail_url = 'http://www.shicimingju.com'+a['href']
detail_page_text = requests.get(detail_url,headers=headers).text
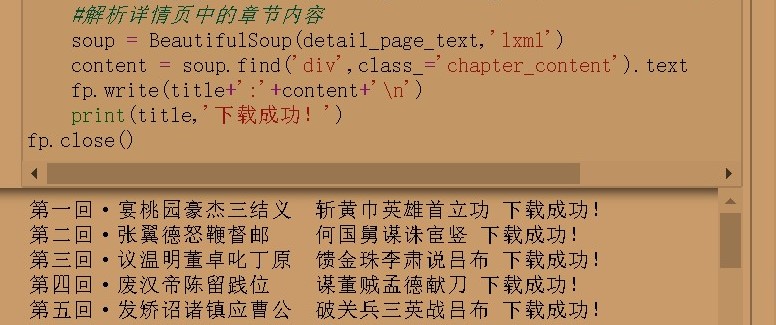
#解析详情页中的章节内容
soup = BeautifulSoup(detail_page_text,'lxml')
content = soup.find('div',class_='chapter_content').text
fp.write(title+':'+content+'\n')
print(title,'下载成功!')
fp.close()
xpath解析
xpath解析的实现原理
- 实例化一个etree的对象,然后将即将被解析的页面源码加载到改对象中
- 使用etree对象中的xpath方法结合着不同形式的xpath表达式实现标签定位和数据提取
环境安装:pip install lxml
etree对象的实例化:
etree.parse('test.html')将本地的html文档加载到etree对象中etree.HTML(page_text)将从互联网上获取的页面源码数据加载到etree对象中。
html文档中的html标签是以树状结构存在的,根标签是<html></html>
xpath表达式:xpath方法的返回值一定是一个列表
全局解析:
最左侧的
/表示:xpath表达式一定要从根标签逐层进行标签查找和定位最左侧的
//表示:xpath表达式可以从任意位置定位标签非最左侧的
/:表示一个层级非最左侧的
//:表示跨多个层级属性定位:
//tagName[@attrName="value"]索引定位:
//tagName[index]索引是从1开始
局部解析:./,对全局解析获得的对象再次解析,开头必须加./
取文本:
/text():直系文本内容//text():所有的文本内容
取属性:/@attrName
from lxml import etree
tree = etree.parse('./test.html')
# 返回<lxml.etree._ElementTree at 0x1a2eacafd88>
tree
# 找到html标签下的head标签的子标签title,该返回的列表中元素是一个对象[<Element title at 0x1a2ead95f48>]
tree.xpath('/html/head/title')
# 从任意位置定位标签
tree.xpath('//title')
tree.xpath('//p')
# 找到所有div标签下的所有p标签,该返回的列表中元素有五个
tree.xpath('/html/body/div/p')
# //跨层级,找到body标签下的所有p标签,该返回的列表中元素有五个
tree.xpath('/html/body//p')
# 属性定位,找到类为song的div标签
tree.xpath('//div[@class="song"]')
# 索引定位,找到第七个li标签
tree.xpath('//li[7]')
# 获取列表中的第一个文本元素
tree.xpath('//a[@id="feng"]/text()')[0]
# 取所有的文本内容,返回列表
tree.xpath('//div[@class="song"]//text()')
# 取属性内容
tree.xpath('//a[@id="feng"]/@href')
爬取糗百中的段子内容和作者名称
urlhttps://www.qiushibaike.com/text/
url = 'https://www.qiushibaike.com/text/'
page_text = requests.get(url,headers=headers).text
# 解析内容
tree = etree.HTML(page_text)
div_list = tree.xpath('//div[@class="col1 old-style-col1"]/div')
for div in div_list:
# 实现局部解析,开头需加.
author = div.xpath('./div[1]/a[2]/h2/text()')[0]
content = div.xpath('./a[1]/div/span//text()')
content = ''.join(content)
print(author,content)
中文乱码的处理
爬取网站urlhttp://pic.netbian.com/4kmeinv/
处理乱码:
处理整个爬取页面的编码比较耗费资源,所以应取到想要的数据,再处理其乱码。
- 对其进行编码
- 对编码结果再进行解码,解码的编码应用本计算机打开不会出现乱码的编码,如utf-8。
注意:一般使用iso-8891-1进行编码,当然也可以使用其他编码。
处理原理python基础中涉及的编码一章已进行了详细讲解,这里不再进行过多解释。
dirName = './meinvLibs'
if not os.path.exists(dirName):
os.mkdir(dirName)
# 通用模板处理
url = 'http://pic.netbian.com/4kmeinv/index_%d.html'
for page in range(1,5):
if page == 1:
new_url = 'http://pic.netbian.com/4kmeinv/'
else:
new_url = format(url%page)
page_text = requests.get(new_url,headers=headers).text
tree = etree.HTML(page_text)
a_list = tree.xpath('//div[@class="slist"]/ul/li/a')
for a in a_list:
img_src = 'http://pic.netbian.com'+a.xpath('./img/@src')[0]
img_name = a.xpath('./b/text()')[0]
# img_name 打印结果出现乱码
#
img_name = img_name.encode('iso-8859-1').decode('gbk')
img_data = requests.get(img_src,headers=headers).content
imgPath = dirName+'/'+img_name+'.jpg'
with open(imgPath,'wb') as fp:
fp.write(img_data)
print(img_name,'下载成功')
提高xpath的通用性
urlhttps://www.aqistudy.cn/historydata/
要求:爬取当前页面的所有城市名称
提高xpath的通用性:.xpath("A|B|...")
- 若A有结果,B无结果,用A;
- 若A有结果,B无结果,用A
- 若A,B都有结果,A,B都有,且返回结果为一个列表。
- 即将所有表达式能匹配到的结果返回进同一个列表中
- 很多情况下一张页面中的标签布局是不一样的,可用|解决。
page_text = requests.get('https://www.aqistudy.cn/historydata/',headers=headers).text
tree = etree.HTML(page_text)
# hot_cities = tree.xpath('//div[@class="bottom"]/ul/li/a/text()')
# all_cities = tree.xpath('//div[@class="bottom"]/ul/div[2]/li/a/text()')
# 提高xpath的通用性 \
cities = tree.xpath('//div[@class="bottom"]/ul/div[2]/li/a/text() | //div[@class="bottom"]/ul/li/a/text()')
cities
xpath表达式小技巧
- 在浏览器中右键检查,定位到想要标签
- 右键-->Copy-->Copy Xpath
即可获取该标签的Xpath表达式

综合案例
urlhttp://sc.chinaz.com/jianli/free.html
要求:对免费的简历模板进行爬取和保存
