JDK 安装目录中 native2ascii.exe 命令详解
native2ascii 简介
native2ascii 是 sun java sdk提供的一个工具。用来将别的文本类文件(比如*.txt,*.ini,*.properties,*.java等等)编码转为 Unicode 编码。为什么要进行转码,原因在于程序的国际化。Unicode 编码的定义:Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。1990年开始研发,1994年正式公布。随着计算机工作能力的增强,Unicode也在面世以来的十多年里得到普及。
该命令主要用于中文的不同编码之间的转换,对于纯数字和字母的文本类型文件(只有ASCII码),转码前后的内容是一样的。
获取 native2ascii
安装了 JDK 后,假如你是在windows上安装,那么在 JDK 的安装目录下,会有一个bin目录,其中 native2ascii.exe 正是。
比如我的 native2ascii 命令是在:
C:\java\jdk1.8.0_152\bin
native2ascii 命令格式
native2ascii -[options] [inputfile [outputfile]]
说明:
[options]:表示命令开关,有两个选项可供选择。如果缺少此参数,则转为Unicode编码。
-reverse [-encoding encoding_name]:将Unicode编码(或指定编码,编码名称为源文件编码名称,不指定编码情况下,默认为Unicode)转为本地编码。
-encoding encoding_name:转换为指定编码,encoding_name为编码名称。编码名称为目标文件编码名称。
[inputfile [outputfile]]:指定文件。
inputfile:表示输入文件全名。
outputfile:表示输出文件全名。如果缺少此参数,将输出到控制台。
最佳实践
首先将JDK的bin目录加入系统变量path。在盘下建立一个test目录,在test目录里建立一个zh.txt文件(注意该文件编码为 ANSI,也就是 GBK),文件内容为:“熔岩”,打开CMD命令行黑窗口,并进入test目录下。下面就可以按照说明一步一步来操作,注意观察其中编码的变化。
(1)将 zh.tx(GBK) t转换为 Unicode 编码,输出到文件 u.txt。
C:\test>native2ascii zh.txt u.txt
C:\test>
打开u.txt,内容为“\u7194\u5ca9”。
将 zh.txt 转换为 Unicode 编码,输出到控制台。(后续命令同样操作,只要不指定输出文件,就会默认输出到控制台。)
C:\test>native2ascii zh.txt
\u7194\u5ca9
C:\test>
(2)将 zh.txt(GBK) 转换为 ISO8859-1 编码,输出到文件 i.txt。
C:\test>native2ascii -encoding ISO8859-1 zh.txt i.txt
C:\test>
打开i.txt文件,内容为“\u00c8\u00db\u00d1\u00d2”。
(3)将 u.txt (Unicode)转换为本地编码(GBK),输出到文件 u_nv.txt。
C:\test>native2ascii -reverse u.txt u_nv.txt
C:\test>
打开 u_nv.txt 文件,内容为“熔岩”。
(4)将 i.txt(ISO8859-1)转换为本地编码(GBK),输出到 i_nv.txt。
C:\test>native2ascii -reverse i.txt i_nv.txt
C:\test>
打开 u_nv.txt 文件,内容为“\u00c8\u00db\u00d1\u00d2”。发现转码前后完全一样的。也就是说,等于没有转。命令使用错误。
-reverse 后面指定编码,所以默认是本地编码GBk,而源文件 i.txt 的编码为 ISO8859-1,所以出现错误,没有进行转码。
(5)将 i.txt( ISO8859-1)转换为本地编码编码(GBK),输出到 i_gbk.txt。
C:\test>native2ascii -reverse -encoding GBK i.txt i_gbk.txt
C:\test>
打开 i_gbk.txt 文件,内容为“/u00c8/u00db/u00d1/u00d2”。发现转码前后完全一样的。也就是说,等于没有转。命令使用错误。
-reverse 后面指定编码 GBK,而源文件 i.txt 的编码为 ISO8859-1,所以出现错误,没有进行转码。
(6)将 i.txt(ISO8859-1)转码到本地编码(GBK),输出到 i_gbk1.txt。
C:\test>native2ascii -reverse -encoding ISO8859-1 i.txt i_gbk1.txt
C:\test>
打开 i_gbk1.txt 文件,内容为“熔岩”,从这个结果看,目标达到到了,编码 i.txt 为 ISO8859-1,转为本地编码后内容为“熔岩”。
从这里应该意识到,native2ascii -reverse 命令中 -encoding 指定的编码为源文件的编码格式。而在 native2ascii -encoding 命令指定的编码为(生成的)目标文件的编码格式。这一点非常的重要!切记!!!
(7)该命令也可以直接对汉字进行转换,退出命令使用 Ctrl + C。
汉字(GBK)转为Unicode
C:\test>native2ascii
测试
\u6d4b\u8bd5
Unicode转为汉字(GBK)
C:\test>native2ascii -reverse
\u6d4b\u8bd5
测试
踩坑记录
记录下我按照这篇网上流传很广的教程操作的踩坑记录:
首先,上面的最佳实践中第一步建立的 zh.txt 文件的编码是 ANSI,而我新建的 zh.txt 文件编码是 UTF-8(我用的文本工具是EditPlus,进行了编码设置)。
Windows自带的记事本新建的文本文件编码是 ANSI。
所以刚开始我就一直用的EditPlus文档进行测试,测试结果一直和教程不一样,经过一番努力,最后找到了是这个编码的的原因。
什么是 ANSI
不同的国家和地区制定了不同的标准,由此产生了 GB2312、GBK、Big5、Shift_JIS 等各自的编码标准。这些使用 1 至 4 个字节来代表一个字符的各种汉字延伸编码方式,称为 ANSI 编码。在简体中文Windows操作系统中,ANSI 编码代表 GBK 编码;在日文Windows操作系统中,ANSI 编码代表 Shift_JIS 编码。 不同 ANSI 编码之间互不兼容,当信息在国际间交流时,无法将属于两种语言的文字,存储在同一段 ANSI 编码的文本中。 当然对于ANSI编码而言,0x00~0x7F之间的字符,依旧是1个字节代表1个字符。这一点是ANSI编码与Unicode编码之间最大也最明显的区别。
继续深入可以看看这篇博客:ANSI是什么编码?
查看文本文件编码
可以通过另存为操作来查看,我是这么干的。

查看Windows编码
(1)第一种方法是在cmd命令行标题栏右键属性,在弹出对话框内可以看到当前的字符集编码。
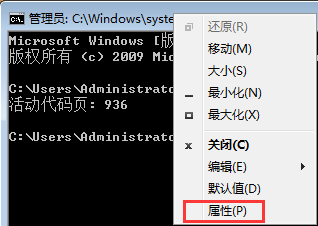
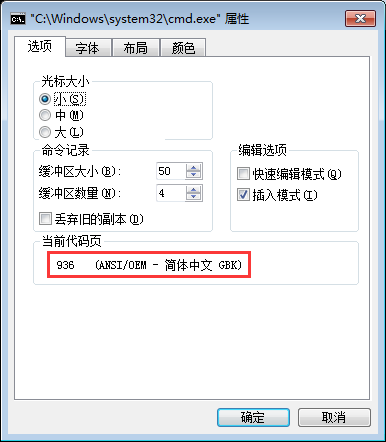
(2)第二种方法是在cmd命令行界面上通过chcp命令查看。
C:\Users\Administrator>chcp 活动代码页: 936 C:\Users\Administrator>
代码页是字符集编码的别名,也有人称"内码表"。早期,代码页是IBM称呼电脑BIOS本身支持的字符集编码的名称。当时通用的操作系统都是命令行界面系统,这些操作系统直接使用BIOS供应的VGA功能来显示字符,操作系统的编码支持也就依靠BIOS的编码。现在这BIOS代码页被称为OEM代码页。图形操作系统解决了此问题,图形操作系统使用自己字符呈现引擎可以支持很多不同的字符集编码。
早期IBM和微软内部使用特别数字来标记这些编码,其实大多的这些编码已经有自己的名称了。虽然图形操作系统可以支持很多编码,很多微软程序还使用这些数字来点名某编码。
下表列出了所有支持的代码页及其国家(地区)或者语言:
代码页 国家(地区)或语言
437 美国
708 阿拉伯文(ASMO 708)
720 阿拉伯文(DOS)
850 多语言(拉丁文 I)
852 中欧(DOS) - 斯拉夫语(拉丁文 II)
855 西里尔文(俄语)
857 土耳其语
860 葡萄牙语
861 冰岛语
862 希伯来文(DOS)
863 加拿大 - 法语
865 日耳曼语
866 俄语 - 西里尔文(DOS)
869 现代希腊语
874 泰文(Windows)
932 日文(Shift-JIS)
936 中国 - 简体中文(GB2312)
949 韩文
950 繁体中文(Big5)
1200 Unicode
1201 Unicode (Big-Endian)
1250 中欧(Windows)
1251 西里尔文(Windows)
1252 西欧(Windows)
1253 希腊文(Windows)
1254 土耳其文(Windows)
1255 希伯来文(Windows)
1256 阿拉伯文(Windows)
1257 波罗的海文(Windows)
1258 越南文(Windows)
20866 西里尔文(KOI8-R)
21866 西里尔文(KOI8-U)
28592 中欧(ISO)
28593 拉丁文 3 (ISO)
28594 波罗的海文(ISO)
28595 西里尔文(ISO)
28596 阿拉伯文(ISO)
28597 希腊文(ISO)
28598 希伯来文(ISO-Visual)
38598 希伯来文(ISO-Logical)
50000 用户定义的
50001 自动选择
50220 日文(JIS)
50221 日文(JIS-允许一个字节的片假名)
50222 日文(JIS-允许一个字节的片假名 - SO/SI)
50225 韩文(ISO)
50932 日文(自动选择)
50949 韩文(自动选择)
51932 日文(EUC)
51949 韩文(EUC)
52936 简体中文(HZ)
65000 Unicode (UTF-7)
65001 Unicode (UTF-8)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号