


mysql命令
1、备份数据库:
mysql -uroot -p med1_h >med1_h.sql
./mysqldump -h192.168.0.74 -p3306 -uroot -proot med1_hospital | gzip > /home/mysql/mysql_back/med1_hospital.sql.gz
2、恢复数据库:
./mysql -h192.168.0.168 -p3306 -uroot -proot med1_h < /home/mysql/mysql_back/med1_h.sql
GRANT SELECT ON ygt.v_tb_tag_disease TO 'hismb'@'%';
一、mysql最大连接数修改
1、查看当前数据库的最大连接数:SHOW VARIABLES LIKE '%max_connections%';
2、设置数据库的最大连接数:
1)在当前会话中设,数据库重启之后失效:
SET GLOBAL max_connections = 1000;
2)在数据库的配置文件my.ini里设,长期有效:
max_connections=151
二、缓存:
1、开启:在my.ini中的[mysqld]中加入以下:
query_cache_size = 32M
query_cache_type = 1
//设置后重启服务;
2、查询缓存是否开启:
SHOW VARIABLES LIKE '%query_cache%';
3、使用注意:
1)开启缓存第二次重复查询时,会加快速度;
2)如果对缓存对应的数据进行修改、新增,会导致缓存清掉;
3)由于增删操作会清理缓存,导致增删操作变慢;
4)主要用于查询频繁,增删少的数据库
查看mysql是否开启日志:show variables like '%log_bin%';
mysql -h 127.0.0.1 -uroot -p
命令创建数据库
create database med1_hospital
修改mysql 的用户名密码
报错:Authentication plugin 'caching_sha2_password' cannot be loaded
出现这个原因是mysql8 之前的版本中加密规则是mysql_native_password,而在mysql8之后,加密规则是caching_sha2_password。
解决问题方法有两种,一种是升级navicat驱动(博主用的是navicat是19年装的了,其他软件同理),另一种是把mysql用户登录密码加密
规则还原成mysql_native_password。
此处介绍第二种,修改加密规则:
1、登录Mysql:
mysql -u root -p
2、修改账户密码加密规则并更新用户密码:
//修改加密规则(可以直接复制)
ALTER USER 'root'@'%' IDENTIFIED BY 'password' PASSWORD EXPIRE NEVER;
//更新一下用户的密码(可以直接复制)
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY 'password';
3、刷新权限并重置密码
//刷新权限(可以直接复制)
FLUSH PRIVILEGES;
4、重置密码
//此处请自定义密码,红色的root就是博主自定义的密码
alter user 'root'@'%' identified by 'root';
此处将密码改为root
2-2-2、不登陆进入mysql直接删除用mysqladmin
2-5-1、备份:mysqldump -u root -p mydb > mydb.sql
2-5-2、恢复:mysql -u root -p mydb<>
4-3-1、格式一:delete from 表名 where 条件;
4-3-2、格式二:truncate table 表名(删除表的所有数据,保留表结构)
4-3-3、格式三:drop table 表名(删除表,所有数据和表结构都删掉)
4-3-4、Truncate、Delete、Drop的区别:
4-4-2-1-4、范围查询in between...and...:
4-4-2-3、排序查询order by ...asc/desc...:
4-4-2-4-1、扩展:分组后的数据筛选group by ...having...
4-4-2-5-2、分页格式:limit 典型的应用场景就是根据公式计算显示某⻚的数据,实现分页查询
4-4-2-6-1、内连接inner join...on..:
4-4-2-6-2、左连接left join...on...:
4-4-2-6-3、右连接right join ...on...:
一、登陆
1-1、命令行登陆
mysql -h127.0.0.1 -uroot -p
二、数据库的操作
2-1、增create
语法格式:create database 数据库名 [charset] [字符编码] [collate] [校验规则];
2-2、删除drop;
2-2-1、语法:drop database 数据库名;
2-2-2、不登陆进入mysql直接删除用mysqladmin
mysqladmin -u root -p drop 数据库名
2-3、查看show
2-3-1、查看有哪些数据库
show databases;注意是复数
2-3-2、查看数据库编码类型
show create database mydb;
2-4、修改alter
2-4-1、修改数据库数据集和校验集
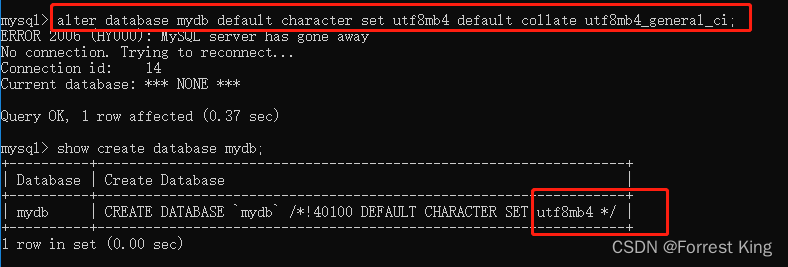
2-5、备份与恢复
2-5-1、备份:mysqldump -u root -p mydb > mydb.sql
(注意没有分号;,备份文件保存在shell对应目录下)
2-5-2、恢复:mysql -u root -p mydb<mydb.sql
三、数据表的操作
3-1、增加create
语法结构:CREATE TABLE 表名(字段名1 类型 约束, 字段名2 类型 约束, ...) ENGINE=INNODB DEFAULT CHARSET=utf8 DEFAULT COLLATE utf8_general_ci;
3-1-1、表名规范:项目简称_表的内容_表的附加内容
- 例如:NT_goods_attr
- 含义:NT商城_商品_属性
3-1-2、数据类型:为了更加准确的存储数据,保证数据的正确有效,需要合理的使用数据类型和约束来限制数据的存储。常用数据类型如下:
- 整数:int,有符号范围(-2147483648~2147483647),unsigned,无符号范围(0~4294967295)
- 小数:decimal,例如:decimal(5,2)表示共存5位数,小数占2位,整数占3位
- 字符串:varchar,范围(0~65533),例如:varchar(3)表示最多存3个字符,一个中文或一个字母都占一个字符
- 日期时间:datatime,范围(1000-0101 00:00:00~9999-12-31 23:59:59),例如:'2020-0101 12:29:59'
3-1-3、表中约束:主键(primary key)、外键(foreign key)、非空(not null)、唯一(unique)、默认值(default)
3-1-3-1、主键(primary key):能唯一标识表中的每一条记录的属性组
- 作用:用来保证数据完整性。主要用于保证数据表内的数据每一条的顺序是固定的,不会由于删除或增加数据,而导致数据乱序。
- 个数:一张数据表中主键只能有一个
- 定义:
- 唯一的标识一条记录,不能重复,不能为空,类型为整数;
- id:习惯用法的字段名;
- 设置主键:为了使用方便,一般会设置为自动递增并且是无符号;
- 在创建数据库表时,create table中指定主键。
- 设置主键:
- 语法格式:create table 数据表名(主键字段名 数据类型 unsigned PRIMARY KEY auto_increment, ...);
- 举例:
- # 创建编辑表(班级编号、班级名称),以及班级编号为主键:
- create table class(
- id int unsigned primary key auto_increment,
- name varchar(10));
3-1-3-2、外键(foreign key):一个表中的一个字段引用另外一个表的主键
- 作用:用来和其他表建立联系
- 个数:一个表可以有多个外键
- 定义:一表的属性是另一表的主键,可以重复,可以为空
- 注意:
- 1)通过外部数据表的字段,来控制当前数据表的数据内容变更,以避免单方面移除数据,导致关联表数据产生垃圾数据的一种方法。
- 2)如果大量增加外键设置,会严重影响数据查询操作以外的其他操作(增/删/改)的操作效率,因此在实际项目工作中很少会被采用,但是在面试中容易被问到。
- 设置外键:
- 语法格式:在创建数据库时,create table中设置外键,即:create table 数据表名(constraint 外键名 foreign key(自己的字段) references 主表(主表字段));
- 举例:
- # 创建学生表,以班级编号关联班级表:
- create table student(
- name varchar(10),
- class_id int unsigned,
- constraint stu_fk foreign key(class_id)
- references class(id));
3-2、查看show
3-2-1、查看表
show tablse;
3-2-2、查看表信息
show create table student;
3-2-3、查看表结构
desc student;
3-3、修改alter
修改表的引擎和字符集:在 创建表语句 中修改,如:alter database testpython default character set utf8mb4 default collate utf8mb4_general_ci;
3-4、删除drop
- 格式二:drop table if exists 表名;
- 举例:删除学生表:
- drop table students;
- drop table if exists students;
四、数据的操作
4-1、新增数据insert into
关键字: insert into ... values ...
添加一行数据:
- 格式一:所有字段设置值,值的顺序与表中字段的顺序对应
- 说明:主键列是自动增长,插入时需要占位,通常使用0或者default或者null来占位,后以实际数据为准。
- 语法格式:insert into 表名 values(...)
- 举例:插入一个学生,设置所有字段的信息:insert into students values(0, '亚瑟', 22, 1.83);
- 格式二:部分字段设置值,值的顺序与给出的字段顺序对应
- 语法格式:insert into 表名(字段1, ...) values(值1, ...)
- 举例:插入一个学生,只设置姓名:insert into students(name) values('老夫子');
添加多行数据:
- 方式一:写多条insert语句,语句之间用英文分号隔开
- 举例:
- insert into students(name) values('张三');
- insert into students(name) values('李四');
- insert into students values(0, '王五', 23, 1.82);
- insert into students values
- (0, '王五', 23, 1.82),
- (0, '赵六', 23, 1.85);
- 方式二:写一条 insert 语句,设置多条数据,数据之间用英文逗号隔开
- 格式一:insert into 表名 values(...), (...) ...;
- 举例:
- 格式二:insert into 表名(列1, ...) values(值1, ...), (值2, ...) ...;
- 举例:
insert into students(name) values('秦琪'), ('马骁');
4-2、修改update
- 关键字:update ... set ...
- 语法格式:update 表名 set 列1=值1, 列2=值2 ... where 条件;
- 举例:
- # 修改`id为5`的学生数据,姓名改为 狄仁杰,年龄改为20
- update students set name='狄仁杰', age=20 where id=5;
记住字符串要加英文状态的双引号。
4-3、 删除delete from
- 关键字:delete、truncate、drop
- 4-3-1、格式一:delete from 表名 where 条件;
- 举例:
- # 删除id为6的学生数据:
- delete from students where id=6;
- 注意:where不能省略,否则会删除全部数据
- 4-3-2、格式二:truncate table 表名(删除表的所有数据,保留表结构)
- 举例:
- # 删除学生表的所有数据:
- truncate table students;
- # 删除学生表:
- drop table students;
- 4-3-3、格式三:drop table 表名(删除表,所有数据和表结构都删掉)
- 举例:
- 4-3-4、Truncate、Delete、Drop的区别:
- 1)Delete from 表名;—— 删除所有数据,但是不重置主键字段的计数
- 2)Truncate table 表名;——删除所有数据,并重置主键字段的计数(即其中的自增长字段恢复从1开始)
- 3)Drop table 表名;——删除表(字段和数据均不再存在)
- 4) truncate不支持where条件删除,而delete支持条件删除
- 5)delete是数据操作语言(DML - Data Manipulation Language)支持事务回滚,truncate是数据定义语言(DDL - Data Definition Language)不支持事务回滚
- 4-3-5、扩展:逻辑删除(假删)
- 定义:所谓逻辑删除,就是通过某一特定字段的特定值表示数据是删除或未删除的状态(0为未删除,1为删除)
- 场景:对于重要的数据,不能轻易执行delete语句进行删除,因为一旦删除,数据就无法恢复,这时可以进行逻辑删除。
- 步骤:
- 1)给表添加字段,代表数据是否删除,一般起名 is_delete, 0代表没删除,1代表删除,默认为0不删除;
- 2)当要删除某条数据时,只需要设置这条数据的 is_delete字段为1就可以了;
- 3)以后在查询数据时,只查询出is_delete为0的数据即可。
- 举例:逻辑删除id为1的数据:update students set is_delete=1 where id=1;
4-4、查询select .... from...
4-4-1、基础查询:
4-4-1-1、查询所有字段:
- 关键字:select ... from ...
- 语法格式:select * from 表名;
- 举例:
- # 查询所有学生数据:
- select * from students;
4-4-1-2、查询部分字段:
- 语法格式:select 字段1, 字段2, ... from 表名;
- 举例:
- # 查询所有学生的姓名、性别、年龄:
- select name, sex, age from students;
4-4-1-3、起别名as:
- 关键字:as
- 给表起别名: 在多表查询中经常使用
- 语法格式:select 别名.字段1, 别名.字段2, ... from 表名 [as] 别名;
- 举例:
- # 给学生表起别名:
- select s.name, s.sex, s.age from students as s;
- # 查询所有学生的姓名、性别、年龄,结果中的字段名显示为中文:
- select name as '姓名', sex as 性别, age as 年龄 from students;
- 给字段起别名: 这个别名会出现在结果集中
- 语法格式:select 字段1 as 别名1, 字段2 as 别名2, ... from 表名;
- 举例:
- 注意:别名的引号可以省略,as关键字也可以省略
- 作用:
- 1)美化数据结果的显示效果
- 2)可以起到隐藏真正字段名的作用
- 3)可以给字段起别名外,还可以给数据表起别名(连接查询时使用)
4-4-1-4、去重distinct:
- 关键字:distinct
- 语法格式:select distinct 字段1, ... from 表名;
- 举例:
- # 查询所有学生的性别,不显示重复的数据:
- select distinct sex from students;
4-4-2、复杂查询:
定义: 在基础查询基础上,根据需求描述关系进行查询;实际应用中往往是多种复合查询的组合使用
分类: 条件查询、聚合函数、排序查询、分组查询、分页查询、连接查询、自关联查询、子查询等
4-4-2-1、条件查询where:
- 定义:按照一定条件筛选需要的结果;使用where子句对表中的数据筛选,符合条件的数据会出现在结果集中
- 关键字:where
- 语法格式:select 字段1, 字段2 ... from 表名 where 条件;
- 说明:where后面支持多种运算符,进行条件的处理
条件构成: 比较运算、逻辑运算、模糊查询、范围查询、空判断等
4-4-2-1-1、比较运算=><!:
- 比较运算符:=、>、<、>=、<=、!=或<>
- 举例:
select age from students where name='小乔';
4-4-2-1-2、逻辑运算and-or-not:
- 逻辑运算符:and(与)、or(或)、not(非)
- 举例:
- 例1:select * from students where age<20 and sex='女';
- 例2:select * from students where sex='女' or class='1班';
- 例3:select * from students where not class='1班' and age=20;
- 注意:
- 1)作为查询条件使用的字符串必须带引号。
- 2)not与and和or不同之处在于:not只对自己右侧的条件有作用(右边连接条件),and和or是左右两边连接条件。
4-4-2-1-3、模糊查询like%_:
- 关键字:like
- 特殊符号:%、_
- % 表示任意多个任意字符
- 格式:%关键词%、%关键词、关键词%
- _ 表示一个任意字符
- 格式:_关键词_、_关键词、关键词_
- 举例:
- 例1:select * from students where name like '孙%';
- 例2:select * from students where name like '孙_';
- 例3:select * from students where name like '%乔';
- 例4:select * from students where name like '%白%';
4-4-2-1-4、范围查询in between...and...:
- 关键字:in、between ... and ...
- in:表示在一个非连续的范围内
- 格式:in(..., ...)
- 举例:
- # 例如:
- select * from students
- where hometown in('北京', '上海', '深圳');
- #例如:
- select * from students
- where age between 18 and 20;
- between ... and ... :表示在一个连续的范围内
- 举例:
- 注意:between ... and ... 的范围必须是从小到大
4-4-2-1-5、空判断is not null:
- 关键字:is null、is not null
- 判空:is null
- 举例:
- #例如:
- select * from students
- where card is null;
- # 例如:
- select * from students
- where card is not null;
- 判非空:is not null
- 举例:
- 注意: 在MySQL中,只有现实为NULL的才为空!其余空白可能是空格/制表符/换行符等空白符号;NULL与 ' '是不同的。
4-4-2-2、聚合函数:
- 定义:对于一组数据进行计算返回单个结果的实现过程,系统提供的一些可以直接用来获取统计数据的函数。
- 注意:
- 1)使用聚合函数方便进行数据统计;聚合函数不能在where子句中使用。
- 2)在需求允许的情况下,可以一次性在一条SQL语句中,使用所有的聚合函数。
- # 例如:
- select count(* ),
- max(price),
- min(price),
- avg(price) from goods;
常用聚合函数: count()、max()、min()、sum()、avg()
4-4-2-2-1、count():查询总记录数
- 格式:count(字段名),count(* )表示计算总行数
- 举例:
- # 查询学生总数:
- select count(* ) from students;
- 注意: 统计数据总数,建议使用*,如果使用某一特定字段,可能会造成数据总数错误!
4-4-2-2-2、max():查询最大值
- 格式:max(字段名)
- 举例:select max(price) from goods;
4-4-2-2-3、min():查询最小值
- 格式:min(字段名)
- 举例:select min(price) from goods;
4-4-2-2-4、sum():求和
- 格式:sum(字段名)
- 举例:
- # 举例:
- select sum(count)
- from goods where remark
- like '%一次性%';
4-4-2-2-5、avg():求平均值
- 格式:avg(字段名)
- 举例:select avg(price) from goods;
4-4-2-3、排序查询order by ...asc/desc...:
- 定义:为了方便查看数据,可以对数据进行排序;排序是按照一定的排序规则筛选所需结果
- 关键字:order by
- 语法格式:select * from 表名 order by 列1 asc/desc, 列2 asc/desc, ...;
- 注意:
- 1)默认按照列值从小到大排列,即升序,asc可省略;asc从小到大排列,即升序;desc从大到小排列,即降序。
- 2)排序过程中,支持连续设置多条排序规则,但离order by关键字越近,排序数据的范围越大!
- 3)将行数据按照列1进行排序,如果某些行列1的值相同时,则按照列2排序,以此类推。
- 举例:select * from goods order by price desc, count;
4-4-2-4分组查询group by:
- 定义:在同一属性(字段)中,将值相同的放到一组的过程。按照字段分组,此字段相同的数据会被放到一个组中。分组的目的是对每一组的数据进行统计(使用聚合函数)
- 关键字:group by
- 语法格式:select 字段1, 字段2, 聚合函数 ... from 表名 group by 字段1, 字段2...
- 注意:
- 1)一般情况,使用哪个字段进行分组,那么只有该字段可以在* 的位置使用,其他字段没有实际意义(只有一组数据中的一条);
- 2)分组操作多和聚合函数配合使用。
- 例1:查询各种性别的人数:select sex, count(* ) from students group by sex;
- 例2:查询每个班级中各种性别的人数:select class, sex, count(* ) from students group by class, sex;
4-4-2-4-1、扩展:分组后的数据筛选group by ...having...
- 关键字:group by、having
- 语法格式:select 字段1, 字段2, 聚合 ... from 表名 group by 字段1, 字段2, 字段3 ... having 字段1, ... 聚合函数 ...
- 注意:
- 1)group by后面增加过滤条件时,需要使用having关键字;group by和having一般情况下需要配合使用
- 2)group by后边不推荐使用where进行条件过滤,推荐使用having进行条件过滤
- 3)having关键字后面可以使用的内容与where完全一致(比较运算符/逻辑运算符/模糊查询/判断空)
- 4)having关键字后面允许使用聚合函数,where后面不允许使用聚合函数
- 举例:查询男生总人数
- 方案一:select count(* ) from students where sex='男';
- 方案二:select sex, count(* ) from students group by sex having sex='男';
- 4-4-2-4-2、where 与 having 的区别:
- 1)where是对from后面指定的表进行数据筛选,属于对原始数据的筛选;
- 2)having是对group by的结果进行筛选;
- 3)having后面的条件可以用聚合函数where后面不可以。
- 例:查询班级平均年龄大于22岁的班级有哪些:select class from students group by class having avg(age)>22;
4-4-2-5、分页查询limit:
- 定义:对大批量数据进行设定数量展示的过程
- 场景:当数据量过大时,在一页中查看数据是一件非常麻烦的事情
- 关键字:limit
- 语法格式:select * from 表名 limit start, count;
4-4-2-5-1、分行格式:查 m ~ n 行的数据
- 语法格式:select * from 表名 limit m-1, n-m+1;
- 注意:
- 1)limit start, count;start:起始行号,start起始行号为m-1行;count:数据行数,count数据行数为n-(m-1)(即:n-m+1)行。
- 2)计算机的计数是从0开始,因此start默认的第一条数据应该为0,后续数据依次减1
- 3)start索引从0开始
- 4)如果默认从第一条数据开始获取,则0可以省略
4-4-2-5-2、分页格式:limit 典型的应用场景就是根据公式计算显示某⻚的数据,实现分页查询
- 语法格式:select * from 表名 limit (n-1)* m, m;
- 说明:已知每页显示m条数据,求显示第n页的数据
- 例1:要求查询商品价格最贵的数据信息
- select * from goods order by price desc limit 0, 1;
- 即:select * from goods order by price desc limit 1;
- 例2:要求查询商品价格最贵的前三条数据信息
- select * from goods order by price desc limit 3;
- 例3:表students每页显示10条数据,需要查询第6页的数据
- select * from students limit (6-1)x10,10;,即:select * from students limit 50,10;
4-4-2-6、连接查询:
定义: 将不同的表通过特定关系连接的过程,包括内连接、左连接、右连接。
4-4-2-6-1、内连接inner join...on..:
- 定义:查询的结果为两个表匹配的数据
- 关键字:inner join ... on ...
- 格式一:select * from 表1 inner join 表2 on 表1.列=表2.列;
- 格式二:select * from 表1 表1别名 inner join 表2 表2别名 on 表1别名.列=表2别名.列;
- 内连接的旧式写法:select * from 表1, 表2 where 表1.列=表2.列;。但效率低于 inner join ... on ... ;
- 注意:
- 显示效果:两张表中有对应关系的数据都会显示出来,没有对应关系的数据不显示
- 表别名的作用:缩短表名利于缩写;用别名给表创建副本。
- 举例:查询所有存在商品分类的商品信息
- select * from goods;
- select * from category;
- 内连接:select * from goods inner join category on goods.typeId=category.typeId;
- 内连接起别名:select * from goods go inner join category ca on go.typeId=ca.typeId;
- 内连接旧式写法:select * from goods, category where goods.typeId=category.typeId;
4-4-2-6-2、左连接left join...on...:
- 定义:查询的结果为两个表匹配到的数据加左表特有的数据,对于右表中不存在的数据使用null填充
- 关键字:left join ... on ...
- 语法格式:select * from 表1 left join 表2 on 表1.列=表2.列;
- 说明:表1为主表,表2为从表
- 注意:
- 1)如果要保证一张数据表的全部数据都存在,则一定不能选择内连接,可以使用左连接或者右连接。
- 2)以left join关键字为界,关键字左侧表为主表(都显示),而关键字右侧为从表(对应内容显示,不对应为null)
- 举例: 查询所有商品信息,包含商品分类
- select * from goods go left join category ca on go.typeId=ca.typeId;
- 扩充需求: 以分类为主展示所有内容(以哪张表为主表, 显示结果上是有区别的!)
- select * from category ca left join goods go on ca.typeId=go.typeId;
4-4-2-6-3、右连接right join ...on...:
- 定义:查询的结果为两个表匹配到的数据加右表特有的数据,对于左表中不存在的数据使用 null 填充
- 关键字:right join ... on ...
- 语法格式:select * from 表1 right join 表2 on 表1.列=表2.列;
- 说明:表1为从表,表2为主表
- 注意:以right join关键字为界,关键字右侧表为主表(都显示),而关键字左侧为从表(对应内容显示,不对应为null)
- 补充:存在右连接的必要性
- 能够体现左右连接必要性的场景为:至少为三张表进行连接查询;三张表连接:表1、表2的连接结果和表3连接,且以表3为主(表3内容全显示)则只能用右连接;而在实际工作中,最多也就三张表连接
- 举例:查询所有商品分类及其对应的商品的信息
- select * from goods go right join category ca on go.typeId=ca.typeId;
- 扩充需求: 查询所有商品信息及其对应分类信息:select * from category ca right join goods go on ca.typeId=go.typeId;
4-4-2-7、子查询(...):
- 定义:在一个查询套入另一个查询的过程(充当条件或者数据源)
- 说明:查询语句中包含另一个查询语句,分为主查询和子查询,充当子查询的语句需要使用括号括起来(运算优先级括号最高!)
- 主查询:外层的 select 语句称之为主查询语句
- 子查询:在一个 select 语句中,嵌入了另外一个 select 语句,那么嵌入的 select 语句称之为子查询语句
- 主查询和子查询的关系:
- 1)子查询是嵌入到主查询中的
- 2)子查询是可以独立使用的语句,是一条完整的 select 语句
- 3)子查询是辅助主查询的,要么充当条件,要么充当数据源
子查询语句充当条件:
- 需求:查询价格高于平均价的商品信息
- 语句:
- select * from goods
- where price > (select avg(price) from goods);
子查询语句充当数据源:
- 需求: 查询所有来自并夕夕的商品信息,包含商品分类
- 语句:
- SELECT * FROM (
- SELECT * FROM goods go
- LEFT JOIN category ca
- ON go.typeId=ca.typeId) new
- WHERE new.company='并夕夕';
- SELECT * FROM
- (SELECT go.* ,
- ca.id cid,
- ca.typeId ctid,
- ca.cateName
- FROM goods go
- LEFT JOIN category ca
- ON go.typeId=ca.typeId) new
- WHERE new.company='并夕夕';
- 问题:连接查询的结果中,表和表之间的字段名不能出现重复,否则无法直接使用
- 解决:将重复字段使用别名加以区分(表.* :表示当前表的所有字段):
- 举例:
- SELECT * FROM
- (SELECT go.* ,
- ca.id cid,
- ca.typeId ctid,
- ca.cateName
- FROM goods go
- LEFT JOIN category ca
- ON go.typeId=ca.typeId) new
- WHERE new.company='并夕夕';
CREATE DATABASE mydatabase
CHARACTER SET utf8mb4
COLLATE utf8mb4_unicode_ci;


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY