正则表达应用
import re
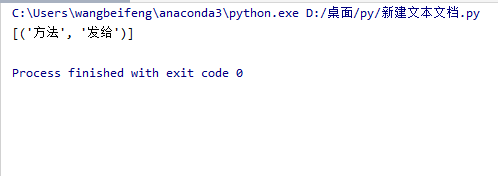
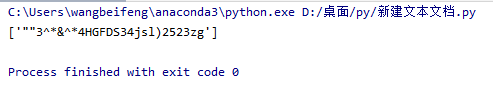
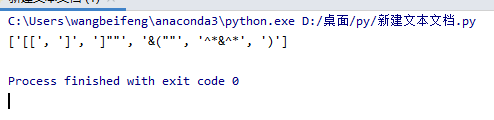
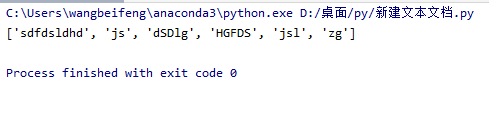
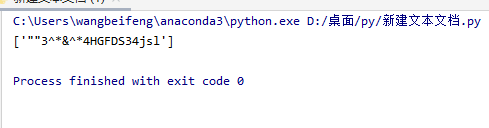
hello = 'sdfdsldhd方法z[[发给g]js]""dSDlg__56S&(""3^*&^*4HGFDS34jsl)2523zg'
demo = re.compile('&\((.*?)\)2',re.S)
lists = demo.findall(hello)
print(lists)
# 1 匹配汉字
# demo = re.compile('hd(.*?)z\[\[(.*?)g',re.S)
#demo = re.compile('[\u4e00-\u9fa5]+',re.S)
# 2 匹配数字
#demo = re.compile('\d+',re.S)
#demo = re.compile('[0-9]{1,}',re.S)

# 3 匹配小写字母
#demo = re.compile('[a-z]{1,}',re.S)

# 4 匹配数字加大写字母
#demo = re.compile('[A-Z 0-9]{1,}',re.S)

# 5 获取(后面的东西
#demo = re.compile('56S\&\((.*)',re.S) 注:括号中不可加?
# 6 获取方括号里的[发给g]js
#demo = re.compile('z\[(.*?)\]"',re.S)

# 7 获取特殊字符
#demo = re.compile('\W+',re.S)
#或
# demo = re.compile('[^0-9 A-Z a-z _ \u4e00-\u9fa5]+',re.S)
# 8 获取连续2个以上的字母
#demo = re.compile('[A-Z a-z]{2,}',re.S)
# 9 获取()里面的东西
#demo = re.compile('\((.*?)\)',re.S)
import re
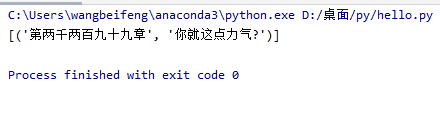
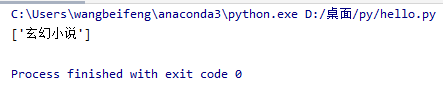
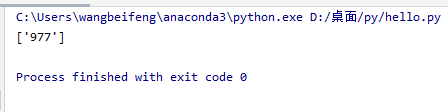
hello = ' <li><p class="ul1">[玄幻小说]《<a class="poptext" href="https://www.23wxc.com/book/977/" title="九天剑主txt下载" target="_blank">九天剑主</a>》</p><p class="ul2"><a href="https://www.23wxc.com/0/977/90728227.html" title="第两千两百九十九章 你就这点力气?" target="_blank">第两千两百九十九章 你就这点力气?</a></p><p>火神</p>20-11-05</li> '
demo = re.compile('<p>.*?</p>(.*?)</li>',re.S)
lists = demo.findall(hello)
print(lists)
#1 获取分类名称
#demo = re.compile('\[(\w+)\]',re.S)
#2 获取977
#demo = re.compile('book/(\d+)/',re.S)
#3 获取书名九天剑主
#demo = re.compile('<a .*?>(\w+)</a>',re.S)
#4 最新章节更新时间
#demo = re.compile('</p>(\d+-\d+-\d+)</li>',re.S)
#demo = re.compile('<p>火神</p>(.*?)</li>',re.S)

#5 匹配章节和内容,分两部分
#demo = re.compile('title="(\w+) (\w+\?)"',re.S)