
Go单元测试与基准测试
Go单元测试
Go单元测试框架,遵循规则整理如下:
1、文件命名规则:
含有单元测试代码的go文件必须以_test.go结尾,Go语言测试工具只认符合这个规则的文件
单元测试文件名_test.go前面的部分最好是被测试的方法所在go文件的文件名。
2、函数声明规则:
测试函数的签名必须接收一个指向testing.T类型的指针,并且函数没有返回值。
3、函数命名规则:
单元测试的函数名必须以Test开头,是可导出公开的函数,最好是Test+要测试的方法函数名。
go test常用选项整理如下(下文有用到)
-v :查看更详细的测试结果输出
-run:指定输出哪个函数的测试结果,默认为当前路径下所有单元测试函数
-coverprofile:指定生成覆盖率测试输出文件
示例代码
fibonacci.go
package unit
func Fibonacci(n int) []int {
if n <= 0 {
return nil
}
f := make([]int, n)
f[0] = 1
a, b := 1, 1
for i := 1; i < n; i++ {
a, b = b, a+b
f[i] = a
}
return f
}
fibonacci_test.go
package unit
import (
"fmt"
"testing"
)
func TestFibonacci(t *testing.T) {
fmt.Println(Fibonacci(6))
}
代码测试
$ go test -v -run=TestFibonacci
=== RUN TestFibonacci
[1 1 2 3 5 8]
--- PASS: TestFibonacci (0.00s)
PASS
ok learning/testing/unit 0.002s
覆盖率测试
通过控制不同场景、不同参数等因素,来尽可能测试运行到所有代码,以提高测试覆盖率,Go提供可视化、量化工具帮助查看测试覆盖率,测试覆盖率仅供参考。
filetype.go
package unit
import (
"fmt"
"golang.org/x/sys/unix"
)
func FileType(mode int) {
switch mode {
case mode & unix.S_IFBLK:
fmt.Println("Block File")jieguo
case mode & unix.S_IFCHR:
fmt.Println("Char File")
case mode & unix.S_IFIFO:
fmt.Println("Pipe File")
case mode & unix.S_IFREG:
fmt.Println("Regular File")
case mode & unix.S_IFSOCK:
fmt.Println("Socket File")
case mode & unix.S_IFLNK:
fmt.Println("Link File")
case mode & unix.S_IFDIR:
fmt.Println("Dir File")
default:
fmt.Println("Unknown File")
}
}
filetype_test.go
package unit
import (
"golang.org/x/sys/unix"
"testing"
)
func TestFileType(t *testing.T) {
FileType(unix.S_IFBLK)
FileType(unix.S_IFSOCK)
}
使用 go test 选项 -coverprofile 指定生成覆盖率文件
$ go test -v -run=TestFileType -coverprofile=c.out
=== RUN TestFileType
Block File
Socket File
--- PASS: TestFileType (0.00s)
PASS
coverage: 14.3% of statements
ok learning/testing/unit 0.002s
输出显示 coverage: 14.3% of statements,即提示代码测试覆盖率为14.3%
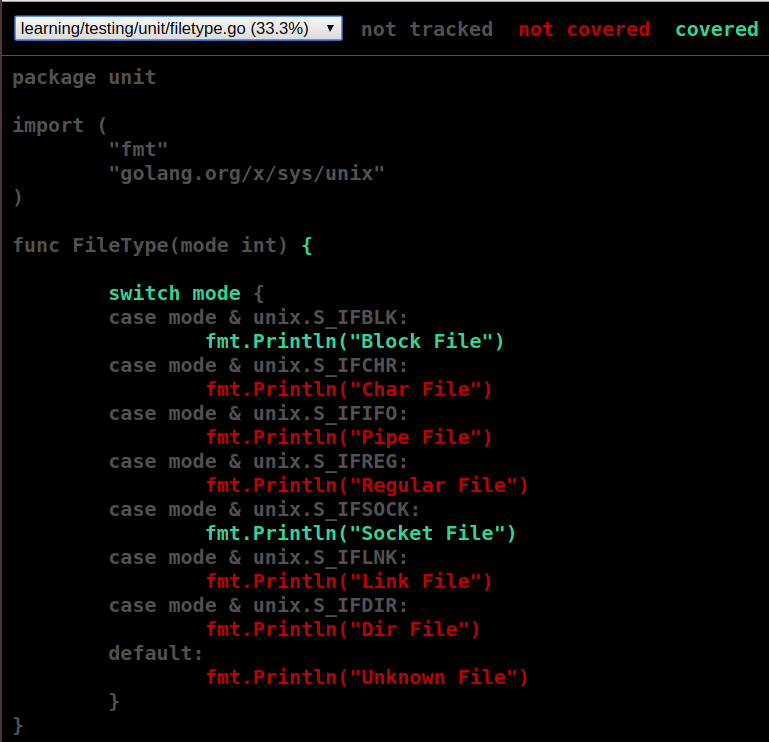
c.out生成测试覆盖率报告,可以通过 go tool cover -html=c.out -o=tag.html,生成一个html格式显示测试覆盖率。使用浏览器打开tag.html显示如下,网页绿色显示为测试已覆盖到,红色显示为测试未覆盖到,可以修改filetype_test.go完善测试程序,将测试覆盖率达到100%。
Go基准测试
基准测试是一种测试代码性能的方法,主要通过测试CPU和内存等因素,来评估代码性能,以此来调优代码性能。
Go基准测试编写规则
1、文件命名规则:
含有单元测试代码的go文件必须以_test.go结尾,Go语言测试工具只认符合这个规则的文件
单元测试文件名_test.go前面的部分最好是被测试的方法所在go文件的文件名。
2、函数声明规则:
测试函数的签名必须接收一个指向testing.B类型的指针,并且函数没有返回值。
3、函数命名规则:
单元测试的函数名必须以Benchmark开头,是可导出公开的函数,最好是Benchmark+要测试的方法函数名。
4、函数体设计规则:
b.N 是基准测试框架提供,用于控制循环次数,循环调用测试代码评估性能。
b.ResetTimer()/b.StartTimer()/b.StopTimer()用于控制计时器,准确控制用于性能测试代码的耗时。
Go基准测试go test命令选项
操作命令:go test -bench=. benchtime=3s -run=none -cpuprofile
-bench :go test默认不会基准测试,需要使用bench启动基准测试,指定匹配基准测试的函数,“.”表示运行所有基准测试
-benchtime :测试时间默认为1s,如果想测试运行时间更长,用-benchtime指定
-run :默认情况下go test会运行单元测试,为防止其干扰基准测试输出结果,
可使用-run过滤单元测试,使用none完全屏蔽,“.”运行所有单元测试
-count :指定执行多少次
$ go test -bench=. -run=none
goos: linux
goarch: amd64
pkg: learning/test/benchmark
BenchmarkSprintf-12 20000000 70.6 ns/op
PASS
ok learning/test/benchmark 1.485s
其中BenchmarkSprintf-12,12表示GOMAXPROCS,20000000表示循环次数,70.6 ns/op表示单次循环操作花费时间
-cpuprofile :生成运行时CPU详细信息
go test -bench=. -run=none -cpuprofile=xxx xxx
将会使用两个生成文件,然后进入交互模式:
$ go tool pprof benchmark.test cpu.out Sprintf.test
File: benchmark.test
Type: cpu
Time: Mar 18, 2019 at 5:01pm (CST)
Duration: 1.70s, Total samples = 1.62s (95.21%)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) top
Showing nodes accounting for 1030ms, 63.58% of 1620ms total
Showing top 10 nodes out of 57
flat flat% sum% cum cum%
220ms 13.58% 13.58% 370ms 22.84% runtime.mallocgc
130ms 8.02% 21.60% 550ms 33.95% fmt.(*pp).doPrintf
120ms 7.41% 29.01% 280ms 17.28% fmt.(*fmt).fmtInteger
120ms 7.41% 36.42% 170ms 10.49% sync.(*Pool).Put
80ms 4.94% 41.36% 110ms 6.79% fmt.(*buffer).Write (inline)
80ms 4.94% 46.30% 80ms 4.94% runtime.memmove
80ms 4.94% 51.23% 140ms 8.64% sync.(*Pool).Get
70ms 4.32% 55.56% 410ms 25.31% fmt.(*pp).printArg
70ms 4.32% 59.88% 90ms 5.56% sync.(*Pool).pin
60ms 3.70% 63.58% 340ms 20.99% fmt.(*pp).fmtInteger
(pprof) quit
-benchmem :提供每次操作分配内存的次数,以及每次分配的字节数。
$ go test -bench=. -benchmem -run=none
goos: linux
goarch: amd64
pkg: learning/test/benchmark
BenchmarkSprintf-12 20000000 70.5 ns/op 16 B/op 2 allocs/op
BenchmarkFormat-12 20000000 77.1 ns/op 18 B/op 2 allocs/op
BenchmarkItoa-12 20000000 78.4 ns/op 18 B/op 2 allocs/op
PASS
ok learning/test/benchmark 4.754s
性能对比
下面是两个关于性能测试对比的示例
值传参和指针传参
package benchmark
import (
"testing"
)
type Cat struct {
Name string
Color string
}
// 值类型传参
func Meow(c Cat) {
c.Color = "white"
}
// 指针类型传参
func Miaow(c *Cat) {
c.Color = "black"
}
func BenchmarkMeow(b *testing.B) {
c := Cat{"Meow", "yellow"}
b.ResetTimer()
for i := 0; i < b.N; i++ {
Meow(c)
}
}
func BenchmarkMiaow(b *testing.B) {
c := Cat{"Miaow", "yellow"}
b.ResetTimer()
for i := 0; i < b.N; i++ {
Miaow(&c)
}
}
性能测试结果
$ go test -bench=. -run=none -benchmem
goos: linux
goarch: amd64
pkg: learning/testing/benchmark
BenchmarkMeow-12 2000000000 0.47 ns/op 0 B/op 0 allocs/op
BenchmarkMiaow-12 2000000000 0.23 ns/op 0 B/op 0 allocs/op
PASS
ok learning/testing/benchmark 1.477s
可以看出在本示例代码中,不同传参方式,指针传递参数比值传递参数性能要优。因为值传参过程中,创建了一个临时对象(变量) ,然后将数据完整拷贝到临时对象,有时间花销。这种情况也包括函数返回值。当然在实际开发过程中,需优先考虑实际场景,如果二者都可以达到预期效果,再考虑性能优化,选择指针类型传参。
slice的不同使用方式
package benchmark
import (
"testing"
)
const TotalTimes = 1000000
func StaticCapacity() {
// 提前一次性分配好slice所需内存空间,中间不需要再扩容,len为0,cap为1000000
var s = make([]byte, 0, TotalTimes)
for i := 0; i < TotalTimes; i++ {
s = append(s, 0)
//fmt.Printf("len = %d, cap = %d\n", len(s), cap(s))
}
}
func DynamicCapacity() {
// 依赖slice底层自动扩容,中间会有很多次扩容,每次都从新分配一段新的内存空间,
// 然后把数据拷贝到新的slice内存空间,然后释放旧空间,导致引发不必要的GC
var s []byte
for i := 0; i < TotalTimes; i++ {
s = append(s, 0)
//fmt.Printf("len = %d, cap = %d\n", len(s), cap(s))
}
}
func BenchmarkStaticCapacity(b *testing.B) {
b.ResetTimer()
for i := 0; i < b.N; i++ {
StaticCapacity()
}
}
func BenchmarkDynamicCapacity(b *testing.B) {
b.ResetTimer()
for i := 0; i < b.N; i++ {
DynamicCapacity()
}
}
性能测试结果
$ go test -bench=. -run=none -benchmem
goos: linux
goarch: amd64
pkg: learning/testing/benchmark
BenchmarkStaticCapacity-12 3000 912668 ns/op 1007617 B/op 1 allocs/op
BenchmarkDynamicCapacity-12 1000 1935269 ns/op 5863427 B/op 35 allocs/op
PASS
ok learning/testing/benchmark 4.914s
可以看出StaticCapacity 性能明显优于DynamicCapacity,所以如果同一个slice被大量循环使用,可提前一次性分配好适量的内存空间
总结:在代码设计过程中,对于性能要求比较高的地方,编写基准测试非常重要,这有助于我们开发出性能更优的代码。不过性能、可用性、复用性等也要有一个相对的取舍,不能为了追求性能而过度优化。
参考:https://www.flysnow.org/2017/05/21/go-in-action-go-benchmark-test.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号