
MySQL8新特性窗口函数详解
本文博主给大家详细讲解一波 MySQL8 的新特性:窗口函数,相信大伙看完一定能有所收获🤓。
- 本文提供的 sql 示例都是基于 MySQL8,由博主亲自执行确保可用
- 博主github地址:http://github.com/wayn111 ,欢迎大家关注,点个star
简介
MySQL8 窗口函数是一种特殊的函数,它可以在一组查询行上执行类似于聚合的操作,但是不会将查询行折叠为单个输出行,而是为每个查询行生成一个结果。窗口函数可以用来处理复杂的报表统计分析场景,例如计算移动平均值、累计和、排名等。其中博主认为它展现的主要威力在于它能够让我们在不修改原有语句输出结果的基础上,直接添加新的聚合字段。
一. 语法解析
窗口函数语法如下:
window_function_name ( [argument1, argument2, ...] )
OVER (
[ PARTITION BY col1, col2, ... ]
[ORDER BY col3, col4, ...]
[ ROWS | RANGE frame_start AND frame_end ]
)
window_function_name
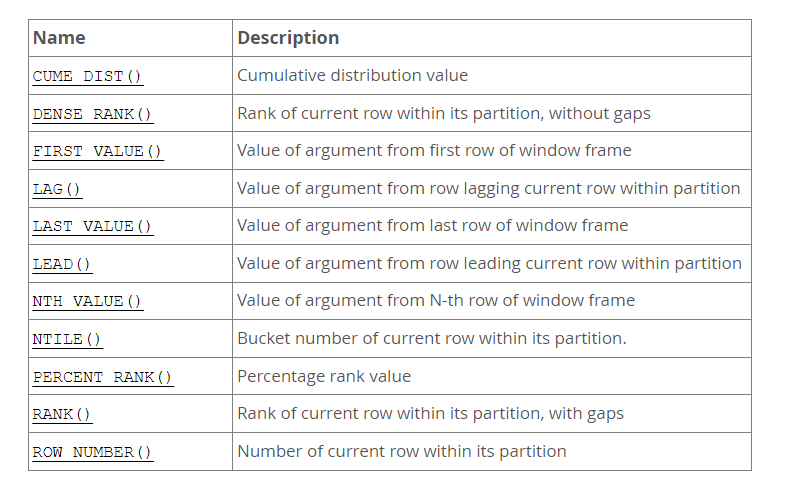
window_function_name 函数可以是聚合函数或者非聚合函数。MySQL8 支持以下几类窗口函数,
- 序号函数:用于为窗口内的每一行生成一个序号,例如
ROW_NUMBER(),RANK(),DENSE_RANK()等。 - 分布函数:用于计算窗口内的每一行在整个分区中的相对位置,例如
PERCENT_RANK(),CUME_DIST()等。 - 前后函数:用于获取窗口内的当前行的前后某一行的值,例如
LAG(),LEAD()等。 - 头尾函数:用于获取窗口内的第一行或最后一行的值,例如
FIRST_VALUE(),LAST_VALUE()等。 - 聚合函数:用于计算窗口内的某个字段的聚合值,例如
SUM(),AVG(),MIN(),MAX()等。
OVER
OVER 关键字很重要,用来标识是否使用窗口函数,语法如下
over_clause:
{OVER (window_spec) | OVER window_name}
两种形式都定义了窗口函数应该如何处理查询行。它们的区别在于窗口是直接在 OVER() 中定义,还是基于 window_name 在 OVER 字句可以重复使用。
OVER()常规用法,窗口规范直接出现在OVER子句中的括号之间。OVER window_name基于Named Windows,是由查询中其他地方的WINDOW子句定义的窗口规范的名称,可以重复使用。本文后续会进行讲解。
PARTITION BY
PARTITION BY子句用来将查询结果划分为不同的分区,窗口函数在每个分区上分别执行,语法如下
partition_clause:
PARTITION BY expr [, expr] ..
ORDER BY
ORDER BY 子句用来对每个分区内的查询结果进行排序,窗口函数将按照排序后的顺序进行计算,语法如下
order_clause:
ORDER BY expr [ASC|DESC] [, expr [ASC|DESC]] ...
frame_clause
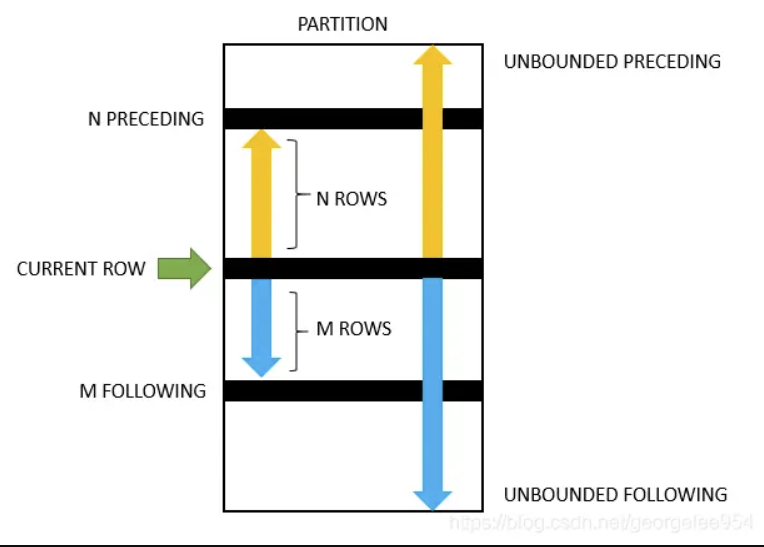
frame_clause 是窗口函数的一个可选子句,用来指定每个分区内的数据范围,可以是静态的或动态的。语法如下
frame_clause:
frame_units frame_extent
frame_units:
{ROWS | RANGE}
其中,frame_units表示窗口范围的单位,可以是ROWS或RANGE。ROWS表示基于行数,RANGE表示基于值的大小。
frame_extent表示窗口范围的起始位置和结束位置,可以是以下几种形式:
CURRENT ROW: 表示当前行。UNBOUNDED PRECEDING: 表示分区中的第一行。UNBOUNDED FOLLOWING: 表示分区中的最后一行。expr PRECEDING: 表示当前行减去expr的值。expr FOLLOWING: 表示当前行加上expr的值。
例如,如果指定了ROWS BETWEEN 2 PRECEDING AND 1 FOLLOWING,则表示窗口范围包括当前行、前两行和后一行。如果指定了RANGE BETWEEN 10 PRECEDING AND CURRENT ROW,则表示窗口范围包括当前行和值在当前行减去10以内的所有行。如果没有指定frame_clause,则默认为RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW,即从分区开始到当前行。
二. Named Windows
MySQL8的 Named Windows 是指在 WINDOW 子句中定义并命名的窗口,可以在 OVER 子句中通过窗口名来引用。使用 Named Windows 的好处是可以避免在多个OVER子句中重复定义相同的窗口,而只需要在 WINDOW 子句中定义一次,然后在 OVER 子句中引用即可。例如,下面的查询使用了三个相同的窗口:
SELECT
val,
ROW_NUMBER () OVER (ORDER BY val) AS 'row_number',
RANK () OVER (ORDER BY val) AS 'rank',
DENSE_RANK () OVER (ORDER BY val) AS 'dense_rank'
FROM numbers;
可以使用Named Windows来简化为:
SELECT
val,
ROW_NUMBER () OVER w AS 'row_number',
RANK () OVER w AS 'rank',
DENSE_RANK () OVER w AS 'dense_rank'
FROM numbers WINDOW w AS (ORDER BY val);
这样就只需要在 WINDOW 子句中定义一个名为w的窗口,然后在三个OVER子句中引用它。
如果一个 OVER 子句使用了 OVER (window_name ...) 而不是 OVER window_name,则可以在引用的窗口名后面添加其他子句来修改窗口。例如,下面的查询定义了一个包含分区的窗口,并在两个 OVER 子句中使用不同的排序来修改窗口:
SELECT
DISTINCT year, country,
FIRST_VALUE (year) OVER (w ORDER BY year ASC) AS first,
FIRST_VALUE (year) OVER (w ORDER BY year DESC) AS last
FROM sales WINDOW w AS (PARTITION BY country);
这样就可以根据不同的排序来获取每个国家的第一年和最后一年。
一个命名窗口的定义本身也可以以一个窗口名开头。这样可以实现窗口之间的引用,但不能形成循环。例如,下面的查询定义了三个命名窗口,其中第二个和第三个都引用了第一个:
SELECT
val,
SUM(val) OVER w1 AS sum_w1,
SUM(val) OVER w2 AS sum_w2,
SUM(val) OVER w3 AS sum_w3
FROM numbers
WINDOW
w1 AS (ORDER BY val),
w2 AS (w1 ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW),
w3 AS (w2 RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW);
这样就可以根据不同的范围来计算每个值的累计和。
三. SQL 示例
下面以一个简单的示例表来说明 MySQL8 窗口函数的用法,提前准备 sql 脚本如下
CREATE TABLE `sales` (
`id` int NOT NULL,
`year` int DEFAULT NULL,
`country` varchar(20) DEFAULT NULL,
`product` varchar(20) DEFAULT NULL,
`profit` int DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
INSERT INTO `test_db`.`sales` (`id`, `year`, `country`, `product`, `profit`) VALUES (1, 2000, 'Finland', 'Computer', 1500);
INSERT INTO `test_db`.`sales` (`id`, `year`, `country`, `product`, `profit`) VALUES (2, 2000, 'Finland', 'Phone', 100);
INSERT INTO `test_db`.`sales` (`id`, `year`, `country`, `product`, `profit`) VALUES (3, 2001, 'Finland', 'Phone', 10);
INSERT INTO `test_db`.`sales` (`id`, `year`, `country`, `product`, `profit`) VALUES (4, 2001, 'India', 'Calculator', 75);
INSERT INTO `test_db`.`sales` (`id`, `year`, `country`, `product`, `profit`) VALUES (5, 2000, 'India', 'Calculator', 75);
INSERT INTO `test_db`.`sales` (`id`, `year`, `country`, `product`, `profit`) VALUES (6, 2000, 'India', 'Computer', 1200);
INSERT INTO `test_db`.`sales` (`id`, `year`, `country`, `product`, `profit`) VALUES (7, 2000, 'USA', 'Calculator', 75);
INSERT INTO `test_db`.`sales` (`id`, `year`, `country`, `product`, `profit`) VALUES (8, 2000, 'USA', 'Computer', 1500);
INSERT INTO `test_db`.`sales` (`id`, `year`, `country`, `product`, `profit`) VALUES (9, 2001, 'USA', 'Calculator', 50);
INSERT INTO `test_db`.`sales` (`id`, `year`, `country`, `product`, `profit`) VALUES (12, 2002, 'USA', 'Computer', 1200);
INSERT INTO `test_db`.`sales` (`id`, `year`, `country`, `product`, `profit`) VALUES (13, 2001, 'USA', 'TV', 150);
INSERT INTO `test_db`.`sales` (`id`, `year`, `country`, `product`, `profit`) VALUES (14, 2002, 'USA', 'TV', 100);
INSERT INTO `test_db`.`sales` (`id`, `year`, `country`, `product`, `profit`) VALUES (15, 2001, 'USA', 'Computer', 1500);
这是一个销售信息表,包含年份、国家、产品和利润四个字段。让我们基于窗口函数来进行一些统计分析,例如:
问题一
计算每个国家每年的总利润,并按照国家和年份排序
SELECT year, country,
SUM(profit) OVER (PARTITION BY country, year) AS total_profit
FROM sales
ORDER BY country, year;
输出结果:
+------+---------+--------------+
| year | country | total_profit |
+------+---------+--------------+
| 2000 | Finland | 1600 |
| 2000 | Finland | 1600 |
| 2001 | Finland | 10 |
| 2000 | India | 1275 |
| 2000 | India | 1275 |
| 2001 | India | 75 |
| 2000 | USA | 1575 |
| 2000 | USA | 1575 |
| 2001 | USA | 1700 |
| 2001 | USA | 1700 |
| 2001 | USA | 1700 |
| 2002 | USA | 1300 |
| 2002 | USA | 1300 |
+------+---------+--------------+
可以看到,每个国家每年的总利润都被计算出来了,但是没有折叠为单个输出行,而是为每个查询行生成了一个结果。
在这里就体现出博主说的不修改原有结果的基础上,添加聚合字段的威力。
问题二
计算每个国家每种产品的销售排名,并按照国家和排名排序
SELECT country, product, profit,
RANK() OVER (PARTITION BY country ORDER BY profit DESC) AS rank1
FROM sales
ORDER BY country, rank1;
输出结果:
+---------+------------+--------+-------+
| country | product | profit | rank1 |
+---------+------------+--------+-------+
| Finland | Computer | 1500 | 1 |
| Finland | Phone | 100 | 2 |
| Finland | Phone | 10 | 3 |
| India | Computer | 1200 | 1 |
| India | Calculator | 75 | 2 |
| India | Calculator | 75 | 2 |
| USA | Computer | 1500 | 1 |
| USA | Computer | 1500 | 1 |
| USA | Computer | 1200 | 3 |
| USA | TV | 150 | 4 |
| USA | TV | 100 | 5 |
| USA | Calculator | 75 | 6 |
| USA | Calculator | 50 | 7 |
+---------+------------+--------+-------+
可以看到,每个国家每种产品的销售排名都被计算出来了,使用了RANK()函数,它会给相同利润的产品分配相同的排名,并跳过之后的排名。细心的朋友可能会发现相同国家产品的销售排名重复之后,下一名会跳名次,如果不想这样可以使用 DENSE_RANK() 函数,
mysql> SELECT country, product, profit,
DENSE_RANK() OVER (PARTITION BY country ORDER BY profit DESC) AS rank1
FROM sales
ORDER BY country, rank1;
+---------+------------+--------+-------+
| country | product | profit | rank1 |
+---------+------------+--------+-------+
| Finland | Computer | 1500 | 1 |
| Finland | Phone | 100 | 2 |
| Finland | Phone | 10 | 3 |
| India | Computer | 1200 | 1 |
| India | Calculator | 75 | 2 |
| India | Calculator | 75 | 2 |
| USA | Computer | 1500 | 1 |
| USA | Computer | 1500 | 1 |
| USA | Computer | 1200 | 2 |
| USA | TV | 150 | 3 |
| USA | TV | 100 | 4 |
| USA | Calculator | 75 | 5 |
| USA | Calculator | 50 | 6 |
+---------+------------+--------+-------+
问题三
计算每个国家每种产品的累计利润,并按照国家和利润排序
SELECT country, product, profit,
SUM(profit) OVER (PARTITION BY country ORDER BY profit
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cumulative_profit
FROM sales
ORDER BY country, profit;
输出结果:
+---------+------------+--------+-------------------+
| country | product | profit | cumulative_profit |
+---------+------------+--------+-------------------+
| Finland | Phone | 10 | 10 |
| Finland | Phone | 100 | 110 |
| Finland | Computer | 1500 | 1610 |
| India | Calculator | 75 | 75 |
| India | Calculator | 75 | 150 |
| India | Computer | 1200 | 1350 |
| USA | Calculator | 50 | 50 |
| USA | Calculator | 75 | 125 |
| USA | TV | 100 | 225 |
| USA | TV | 150 | 375 |
| USA | Computer | 1200 | 1575 |
| USA | Computer | 1500 | 3075 |
| USA | Computer | 1500 | 4575 |
+---------+------------+--------+-------------------+
可以看到,每个国家每种产品的累计利润都被计算出来了,使用了SUM()函数,并指定了ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW作为窗口范围,表示从分区开始到当前行。
问题四
基于Named Window 重写问题三,sql 如下
SELECT country, product, profit,
SUM(profit) OVER w1 AS cumulative_profit
FROM sales
WINDOW
w1 as (PARTITION BY country ORDER BY profit
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
ORDER BY country, profit
;
输出结果:
+---------+------------+--------+-------------------+
| country | product | profit | cumulative_profit |
+---------+------------+--------+-------------------+
| Finland | Phone | 10 | 10 |
| Finland | Phone | 100 | 110 |
| Finland | Computer | 1500 | 1610 |
| India | Calculator | 75 | 75 |
| India | Calculator | 75 | 150 |
| India | Computer | 1200 | 1350 |
| USA | Calculator | 50 | 50 |
| USA | Calculator | 75 | 125 |
| USA | TV | 100 | 225 |
| USA | TV | 150 | 375 |
| USA | Computer | 1200 | 1575 |
| USA | Computer | 1500 | 3075 |
| USA | Computer | 1500 | 4575 |
+---------+------------+--------+-------------------+
四. 窗口函数优缺点
优点:
- 窗口函数可以在不改变原表行数的情况下,对每个分区内的查询行进行聚合、排序、排名等操作,提高了数据分析的灵活性和效率。
- 窗口函数可以使用滑动窗口来处理动态的数据范围,例如计算移动平均值、累计和等。
- 窗口函数可以与普通聚合函数、子查询等结合使用,实现更复杂的查询逻辑。
缺点:
- 窗口函数的语法较为复杂,需要注意
OVER子句中的各个参数的含义和作用。 - 窗口函数的执行效率可能不如普通聚合函数,因为它需要对每个分区内的每个查询行进行计算,而不是折叠为单个输出行。
- 窗口函数只能在
SELECT列表和ORDER BY子句中使用,不能用于WHERE、GROUP BY、HAVING等子句中。
关于查询性能这里,窗口函数的性能取决于多个因素,例如窗口函数的类型、窗口的大小、分区的数量、排序的代价等。一般来说,窗口函数的性能优于使用子查询或连接的方法,因为窗口函数只需要扫描一次数据,而子查询或连接可能需要多次扫描或连接。
但是,并不是所有的窗口函数都能高效地计算。一些窗口函数,例如ROW_NUMBER()、RANK()、LEAD()等,只需要对分区内的数据进行排序,然后根据当前行的位置来计算结果,这些窗口函数的性能较好。另一些窗口函数,例如SUM()、AVG()、MIN()、MAX()等,需要对分区内或窗口内的数据进行聚合,这些窗口函数的性能较差。
为了提高窗口函数的性能,可以采用以下一些方法:
- 选择合适的窗口函数,避免使用复杂或重复的窗口函数。
- 使用
Named Windows来定义和引用窗口,避免在多个OVER子句中重复定义相同的窗口。 - 尽量减少分区和排序的代价,使用索引或物化视图来加速分区和排序。
- 尽量减少窗口的大小,使用合适的
frame_clause来限制窗口内的数据范围。 - 尽量使用并行处理来加速窗口函数的计算,利用多核或分布式系统来提高效率。
五、总结
窗口函数的应用场景很广,可以完成许多数据分析与挖掘任务。MySQL8 支持窗口函数是一个非常棒的特性,大大提高了 MySQL 在数据分析领域的竞争力。希望通过这篇文章可以帮助大家对 MySQL8 的窗口函数有一个初步的认识。
关注公众号【waynblog】每周分享技术干货、开源项目、实战经验、高效开发工具等,您的关注将是我的更新动力!

