NLP-零基础入门NLP之新闻文本分类
赛事理解
今天是打卡的第一天,任务是零基础入门NLP之新闻文本分类,赛事的链接如下:
赛题理解
-
赛题名称:零基础入门NLP之新闻文本分类
-
赛题目标:通过这道赛题可以引导大家走入自然语言处理的世界,带大家接触NLP的预处理、模型构建和模型训练等知识点。
-
赛题任务:赛题以自然语言处理为背景,要求选手对新闻文本进行分类,这是一个典型的字符识别问题。
赛题数据
- 赛题以匿名处理后的新闻数据为赛题数据,数据集报名后可见并可下载。赛题数据为新闻文本,并按照字符级别进行匿名处理。整合划分出14个候选分类类别:财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐的文本数据。
- 赛题数据由以下几个部分构成:训练集20w条样本,测试集A包括5w条样本,测试集B包括5w条样本。为了预防选手人工标注测试集的情况,我们将比赛数据的文本按照字符级别进行了匿名处理。
- 在数据集中标签的对应的关系如下:{'科技': 0, '股票': 1, '体育': 2, '娱乐': 3, '时政': 4, '社会': 5, '教育': 6, '财经': 7, '家居': 8, '游戏': 9, '房产': 10, '时尚': 11, '彩票': 12, '星座': 13}
评测指标
- 评价标准为类别f1_score的均值,选手提交结果与实际测试集的类别进行对比,结果越大越好。
赛事说明到这基本介绍结束,重点剖析各个部分的重要使用的方法和技术
f1_score重点介绍
F1分数(F1-score)是分类问题的一个衡量指标。一些多分类问题的机器学习竞赛,常常将F1-score作为最终测评的方法。它是精确率和召回率的调和平均数,最大为1,最小为0。
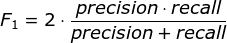
计算过程
- 首先定义以下几个概念:
- TP(True Positive):预测答案正确
- FP(False Positive):错将其他类预测为本类
- FN(False Negative):本类标签预测为其他类标
- 通过第一步的统计值计算每个类别下的precision和recall
- 精准度 / 查准率(precision):指被分类器判定正例中的正样本的比重
- 召回率 / 查全率 (recall):指的是被预测为正例的占总的正例的比重
- 另外,介绍一下常用的准确率(accuracy)的概念,代表分类器对整个样本判断正确的比
- 精准度 / 查准率(precision):指被分类器判定正例中的正样本的比重
- 通过第二步计算结果计算每个类别下的f1-score,计算方式如下
- 通过对第三步求得的各个类别下的F1-score求均值,得到最后的评测结果,计算方式如下
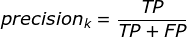
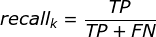
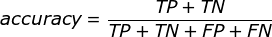

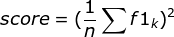
解题思路
思路1:TF-IDF + 机器学习分类器
直接使用TF-IDF对文本提取特征,并使用分类器进行分类。在分类器的选择上,可以使用SVM、LR、或者XGBoost。
TF-IDF的思路
-
计算词频
-
词频(TF) = 某个词在文章中的出现次数 / 文章总词数
-
-
某个词在文章中的出现次数
-
逆文档频率(IDF) = log(语料库的文档总数/包含该词的文档总数+1)
-
-
计算TF-IDF
-
TF-IDF = 词频(TF) * 逆文档频率(IDF)
-
可以看到,TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。所以,自动提取关键词的算法就是计算出文档的每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词。
优点:
-
简单快速,结果比较符合实际情况
缺点:
-
单纯以"词频"衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不多。
-
这种算法无法体现词的位置信息,出现位置靠前的词与出现位置靠后的词,都被视为重要性相同,这是不正确的。

思路2:FastText(了解不多,后续补充)
FastText是入门款的词向量,利用Facebook提供的FastText工具,可以快速构建出分类器。
fastText的架构和word2vec中的CBOW的架构类似,因为它们的作者都是Facebook的科学家Tomas Mikolov,而且确实fastText也算是word2vec所衍生出来的。
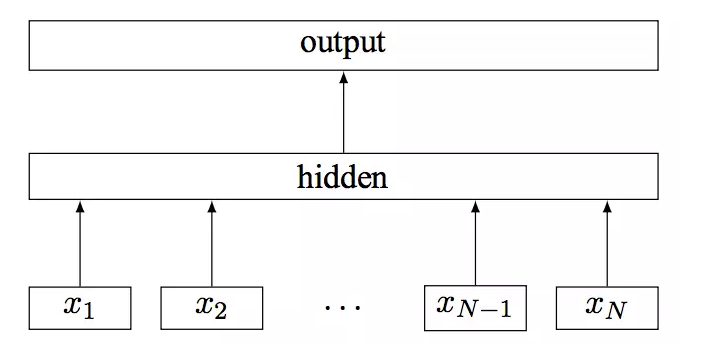
fastText模型架构
其中x1,x2,...,xN−1,xN表示一个文本中的n-gram向量,每个特征是词向量的平均值。这和前文中提到的cbow相似,cbow用上下文去预测中心词,而此处用全部的n-gram去预测指定类别。
fastText和word2vec的区别
- 相似处:
- 图模型结构很像,都是采用embedding向量的形式,得到word的隐向量表达。
- 都采用很多相似的优化方法,比如使用Hierarchical softmax优化训练和预测中的打分速度。
- 不同处:
- 模型的输出层:word2vec的输出层,对应的是每一个term,计算某term的概率最大;而fasttext的输出层对应的是分类的label。不过不管输出层对应的是什么内容,起对应的vector都不会被保留和使用。
- 模型的输入层:word2vec的输出层,是 context window 内的term;而fasttext 对应的整个sentence的内容,包括term,也包括 n-gram的内容。
- 两者本质的不同,体现在 h-softmax的使用:
- Word2vec的目的是得到词向量,该词向量 最终是在输入层得到,输出层对应的 h-softmax也会生成一系列的向量,但最终都被抛弃,不会使用。
- fastText则充分利用了h-softmax的分类功能,遍历分类树的所有叶节点,找到概率最大的label(一个或者N个)
思路3:WordVec + 深度学习分类器
WordVec是进阶款的词向量,并通过构建深度学习分类完成分类。深度学习分类的网络结构可以选择TextCNN、TextRNN或者BiLSTM。
WordVec
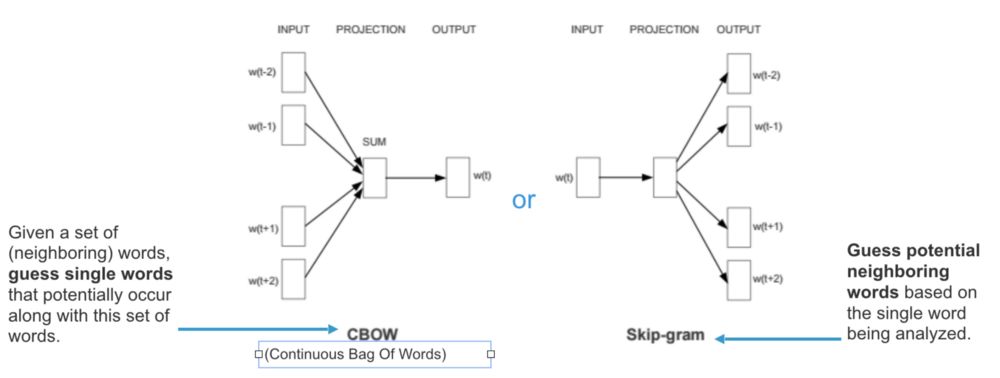
词向量(word embedding),可以很好地度量词与词之间的相似性。随着深度学习(Deep Learning)在自然语言处理中应用的普及,很多人误以为word2vec是一种深度学习算法。其实word2vec算法的背后是一个浅层神经网络,分为两种模型
- CBOW 由上下文的词语预测中间词
- Skip 由中心词预测上下文的词语
深度学习分类器(简要说明,后续详细介绍)
深层学习的分类器主要处理文本的可以使用RNN,LSTM,BiLSTM(双向LSTM),CNN(TEXTCNN)等
思路4:Bert词向量(了解不多,后续补充)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号