6、计算机信息单位
计算机信息单位
1、信息的单位
1.1、基本单位
-
位(bit,比特):是计算机当中的最小数据单位,是二进制的一个数位,简称比特,一般用小b表示
-
字节(Byte):字节是计算机中存储信息的基本单位,一般用大B表示
-
位和字节的关系
- 一个字节等于八个二进制
- 1B = 8b || 1B = 8比特
-
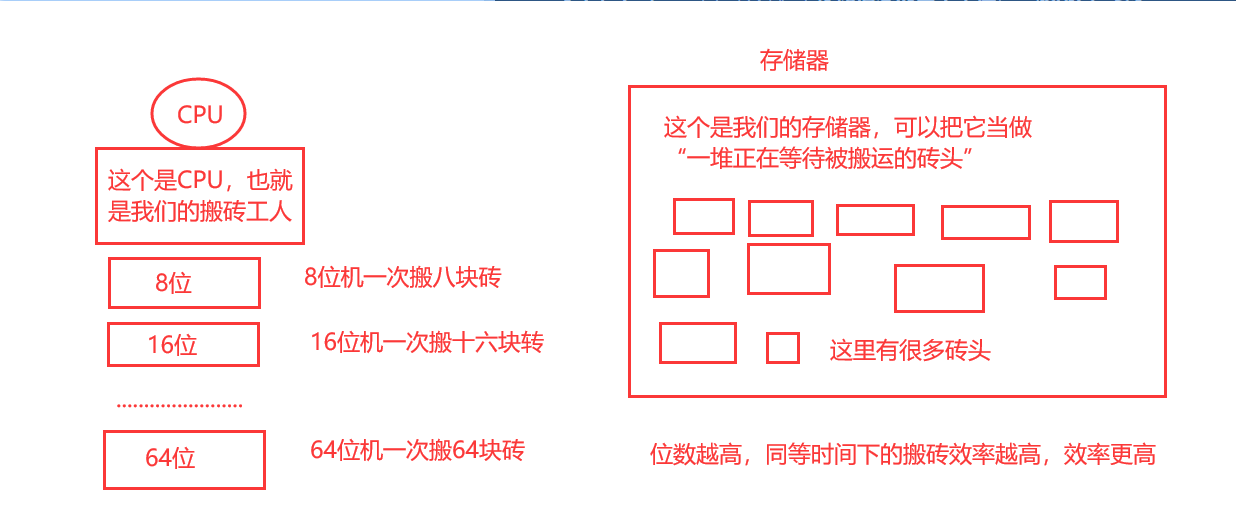
字: CPU通过数据总线一次性存储、加工、传输的数据 称为 “字”
-
字长: CPU 一次性传输,运算或者处理的二进制的位数
-
如何区分?
- 例如我这里有一串二进制数为 10101101
- 10101101这个数据本身是字
- 而10101101,共计八位,这个八位,就是字长
-
字和字长的图解
1.2、总结(位,字节,字,字长)
- 提到我们的计算机最小单位,就是比特,b,bit
- 计算机的基本单位,也就是字节,B,Byte
1.3、练习
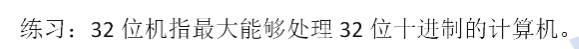
- 这道题的答案是错误,具体错误有哪些呢?
- 首先,字长代表一次性能处理XX位的二进制位数,这里的32位就是代表能够一次性处理32位二进制位数
- 这里的一次性很重要,或者说同时,如果这题只将后面的十进制改成二进制那么答案依然是错误的,因为他没有表示同时或者一次性的意思在里面
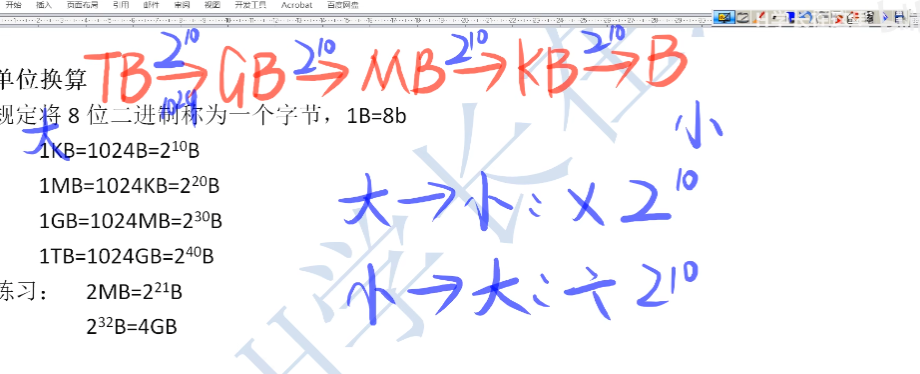
1.4、单位换算

- 这个其实没什么多讲的,因为对电脑比较了解,1024倍的关系还是知道的
- 倍率关系图
1、小练习

- 这个等后面出稍微复杂点的题在做
2、数值表示
2.1、原反补
在计算机当中采用原码,反码,补码的形式对数值进行统一
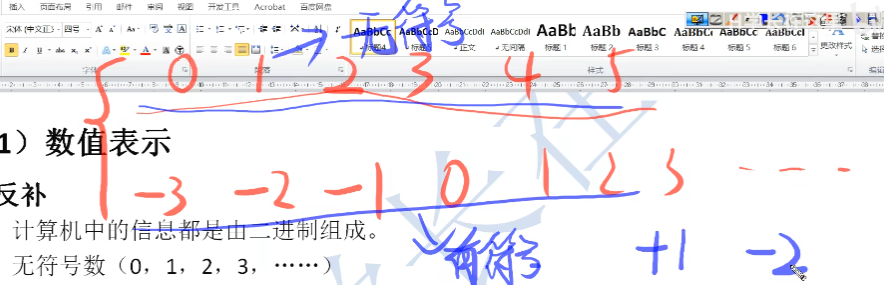
- 最开始学数字的时候,学数字的时候是从自然数开始学起的
- 从上初中开始,知道了负数的存在
- 正数和负数也被我们后来称之为无符号数和有符号数
- 通过之前的学习我们了解到,计算机的信息都是由二进制组成的,那么在计算机当中是如何表示有符号和无符号呢?
- 二进制分为0和1,用0和1我们可以用来表示正数和负数
- 所以记住口诀,0正1负
- 例子1
- 例子2
- 例子1


2.2、关于原反补
- 原码: 通常会将最高位当做符号位,也就是0正1负
- 反码: 正数的反码与原码相同(这句话挺耐人寻味的),负数的反码是在原码的基础上, “符号位” 不变,其余位取反
- 补码: 正数的补码与原码相同,负数的补码是反码的基础上加一
2.3、例题加深印象

手写


2.4、关于选择题部分的考点
- 有些时候这一类题也会考到选择题,会问以下几个问题
- 例如
- n位二进制,他的(无符号)十进制代表的范围是?
- n位二进制,他的(有符号)十进制代表的范围是?
- 状态数:
1、无符号数的范围
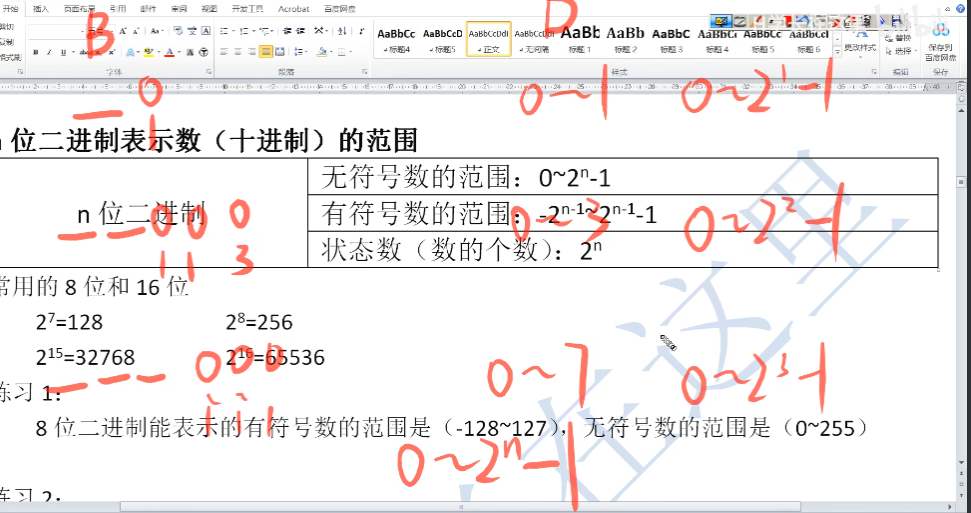
- 上图我简单说一下为什么,我们从2位和3位开始讲
- 如果是二位数的二进制数,那么他最大为11,最小为00,那么就是00-11
- 转换成十进制数,00代表0,而11代表2 + 1 = 3,所以范围是03**,(**02的2方 - 1)
- 如果是三位二进制数,那么最小为000,最大为111
- 转换成十进制数,000代表0,而111代表4 + 2 + 1 = 7,所以范围是07**(**02的3方 - 1)
2、有符号数的范围

- 如果说无符号数是从0开始的,那么有符号数就肯定是从负数开始的
- 所以范围是上述的这个
3、状态数
- 状态数其实就相当于无符号数的个数是多少个
- 例如,用二位二进制举例
- 最大11,最小00,那么可能会出现以下四种情况
- 00
- 01
- 10
- 11
- 共计四位数,四种可能的情况,所以它的状态数就是2的2次方(几位数就是几次方)
- 最大11,最小00,那么可能会出现以下四种情况
4、常用的8位和16位

2.5、练习
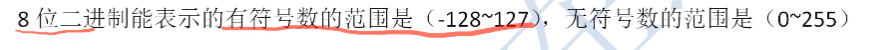

多选题

十六位

3、机器数
3.1、机器数的表示
在计算机当中,虽然基础是由二进制组成的,但是我们处理的二进制不仅仅有整数,也包含小数,根据小数点的位置是否固定,将数值分为定点数和浮点数
- 浮点数: 类似于咱们的科学技术法,例如十进制下,12500 = 0.125 * 10的5方
- 定点数:像12.5,1.25,这些,就是定点数


3.2、考点(阶码和尾数)

- 我们举的例子,是以十进制为例的,在计算机当中是以二进制来运算和处理的
- 这里直接看我的笔记吧

4、信息编码(重要)
**在计算机中,我们最常见的是 “数值(0,1.....)”,还有非数值(a-z,A-Z,中文),数值可以存储在计算机当中,非数值也是可以的 **
为什么计算机可以存储非数值呢?如何区分数值和非数值,就是因为他们编码的形式不同
4.1、计算机当中常见的信息编码
1、BCD编码

- 计算机当中使用的是二进制,而人们习惯使用的是十进制,因此,输入时,要将十进制数转换为 相对应的 二进制,而输出的时候,要将二进制转换为对应的十进制
- 常见的BCD码
- 8421BCD码: 最常见的BCD码,用4位二进制表示一位十进制(判断题,用几位二进制表示十进制码)
- 2421BCD码
- 5211码
- 余3码等等
- 所谓不同的编码,表达的意思也不同
2、字符编码
**ASCII码:漂亮国信息交换的 “标准代码” **
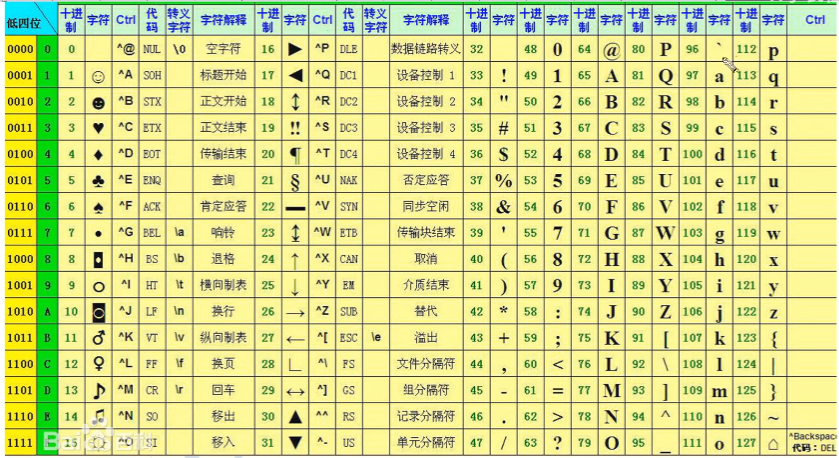
- 后期遇见问题可以参照这个阿斯克码进行对比
- 需要记住以下几点
- 空格是最小的阿斯克码,他是32
- 0的阿斯克码是48,借0推1
- A的阿斯克码是65
- a的阿斯克码是97
- a - A 是32
- b - B 是32
3、总结
- 一个阿斯克码(西文字符)占1个字节,也就是1Byte,一个字节代表8位,阿斯克码只用了低7位,最高位是0
- 共有128个字符,范围是(0-127)
- 并不是所有的阿斯克码都可以显示或者打印,比如0-31是控制字符,127是删除字符(del)
- 空格是最小的能显示的字符
- 阿斯克码的值比较,数字 < 大写字母 < 小写字母
- 对应的大小写阿斯克码之间,相差32D(32个十进制)
4.2、练习
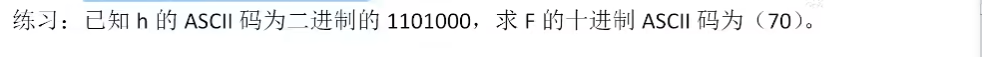
解题思路

4.3、扩展阿斯克码
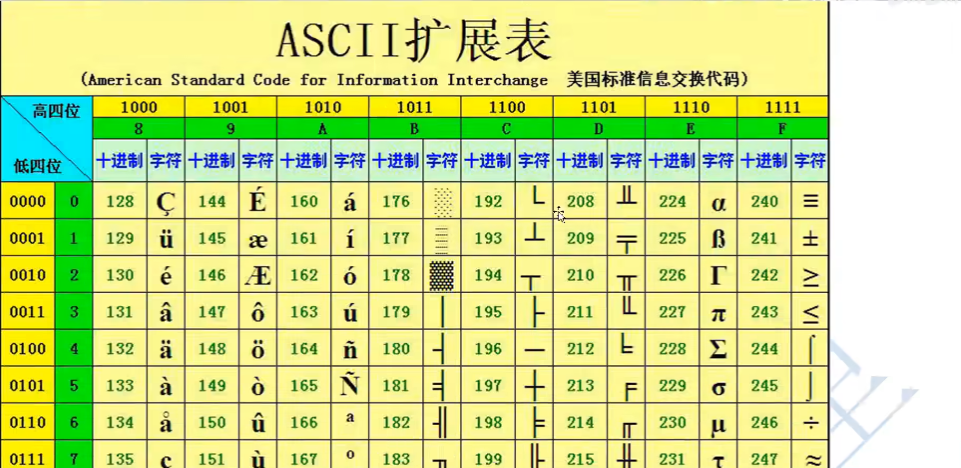
- 扩展阿斯克码的概念
- 原先我们讲过阿斯克码 占位1B,用了后七位
- 扩展的阿斯克码,最高位是1,使用了最高位,一般是拉丁字符
- 核心:共有128个字符,范围是(128-255)
4.4、中文编码(GB2312-80)
也被称之为GB3212,是80年代产生的,收录了6000多个汉字,3000多个常用汉字,但是用到后面发现不够用
西文,用ASCII码,但是我们用的不是西文
最早开始,汉化的过程非常艰辛,计算机内部还是用的英文,虽然我们现在的感触比较模糊
从GB2312 => GBK => GB18030 => BIG5
总结
- 汉字不能使用阿斯克码,但是可以使用Unicode编码
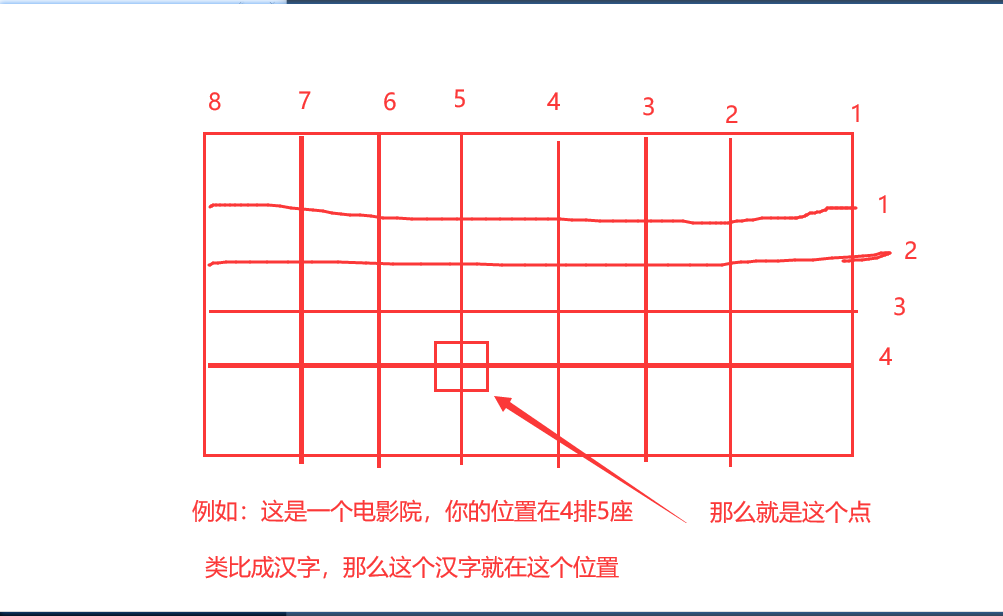
1、区位码(十进制)
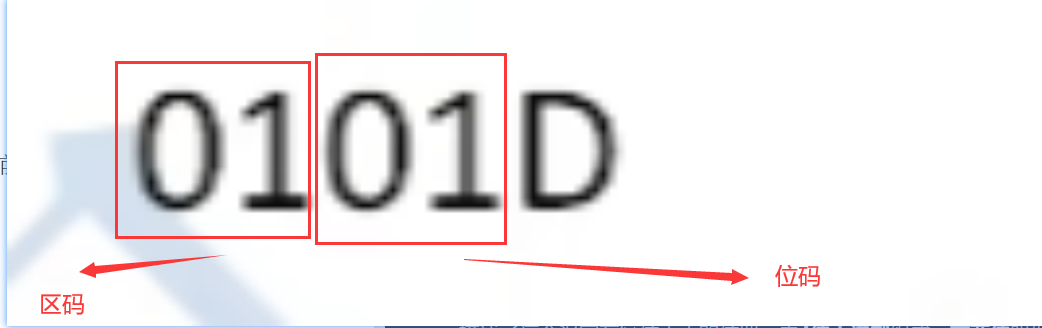
- 就像一张表,把我们最常用的那些东西收集起来
- 最小区位码为:0101D(注意,这个D代表是十进制的意思)
- 描述了这个汉字在区位表中的位置,由4位十进制组成,前两位叫做区码(横坐标),后两位叫做位码(纵坐标)
- 一横一竖,两线交汇点就是这个汉字的位置
2、国标码
其实国标码就是GB2312,他是一个汉字交换码,区位码就是国标码的一个表示形式,因为区位码会把汉字收集起来
- 国标码 = 区位码 + 2020H(16进制)
- 这里的2020H,实际上是区码 + 32十进制,位码 + 32十进制,为什么呢?
- 因为在阿斯克码中,控制字符的范围是0-31,我们跨过这个控制字符,那就是32了
- 规定: 一个汉字占两个字节,也就是2比特,每个字节的最高位为0
- 收集(6763个汉字)
- 一级汉字:(常用汉字),3755个,按拼音字母排序
- 二级汉字:(非常用汉字),3008个,按部首排序
- 出个题:
- 汉字都是按照拼音排序的(X)
- 解答: 非常用汉字是按照部首排序的
- 国标码转换区位码的过程:
- 首先国标码 = 区位码 + 2020H (也就是16进制),不同进制之间无法做加法,所以要先将区位码转换为16进制
- 接下来就是简单的进制之间的四则运算
- 最终得到我们的国标码
3、机内码
是计算机内部的一个编码方式
- **机内码 = 国标码 + 8080H (80H = 128) **
- 最小机内码为: A1A1H
- 为什么加8080H是为了与西文编码区分(也就是阿斯克码)
- 为了与希文字符进行区别,所有汉字的机内码在国标码的基础上,把两个字节的每个字节的最高位为成1,就得到了机内码
- 机内码是唯一的
- 注意
- 机内码有两个字节,每个字节的最高位都是1
4.5、练习

分三步
- 先对区位码进行十转十六进制,因为国标码和机器码都是十六进制的
- 注意:区位码转换成16进制的时候,区码和位码都需要分开转换
- 国标码 = 区位码 + 2020H
- 机器码 = 国标码 + 8080H
1、

2、

3、

4.6、经典题

4.7、汉字输入码(外码,外码不唯一)
可以分为以下几个部分

关于外码不唯一,内码唯一(伍)

运行流程

- 我们在计算机内部输入我们的汉字
- 汉字==>输入码
- 输入码通过密码本,进行转换,得到交换码
- 交换码(国标码,区位码):进行转换(8080H),从而形成我们的机内码
- 机内码要显示出来,就是我们最后的输出码
4.8、汉字字形码(输出码)
也被称作汉字字模
- 矢量子模: 不容易失真(打印横幅)
- 点阵字模: 容易失真(电脑)

这是一张电脑桌面背景放大很多倍的图片,很多马赛克,这就是点阵
1、题型
字库中存放的是汉字字形码(√)
- 其实就相当于这个图
- 最终我们输入的内容,在通过输出码进行解密,解密完成的这个过程
- 实际上就是在字库中去进行查找和翻译的
2、关于点阵的概念
- 点阵字模当中,一个点,占据一位(一个二进制),所以n*n的点阵字模,占(n * n / 8)个字节(1B = 8b(位))
- 比如 16 * 16 的点阵字模,他占( 16 * 16 /8 = 16 * 2 = 32B)
3、练习

- 一个16 * 16 占32B,那么100个自然是3200B(字节)

- 一个7 * 9点位占8B
- 全部英文字母(26 + 26 = 52个)
- 52 * 8 = 416

- 我们来分析一下这个题
- 在计算机内部,那说明在流程图当中
- 从输入码开始 => 国标码 => 十六进制机内码 => 计算机内部输出码
- 计算机内部,那就说明是计算机机内码
- 我们知道西文(阿斯克码)一个西文占一个字节,一个汉字占两个字节
- 最小的机内码是A1A1H
- 这里有六个字节,也就是说,最多六个西文,或者最多三个汉字
- 重点: 如果是汉字的话,那么就需要两个字节组成,并且这个组成遵循就近原则,谁先组成,那么哪怕他后面的字节也可以跟他组成汉字,也不行
- 下面我们看运算过程


 浙公网安备 33010602011771号
浙公网安备 33010602011771号