ARM32内核解压流程
 简要介绍了ARM32平台上,内核解压的流程。同时,根据代码修改历史,发表了对于当前代码实现背后逻辑的一些个人见解。
简要介绍了ARM32平台上,内核解压的流程。同时,根据代码修改历史,发表了对于当前代码实现背后逻辑的一些个人见解。
已经有很多关于ARM32上内核解压流程的文章了,例如内核开发者linuxsw写的ARM32内核解压流程。本文并不详细解释解压过程的每个步骤,而是尝试从代码实现背后的需求或历史原因这样一个角度来解析实现思想,主要关注arch/arm/boot/compressed/head.S的内容,但是略去了XIP,虚拟化和EFI相关内容。
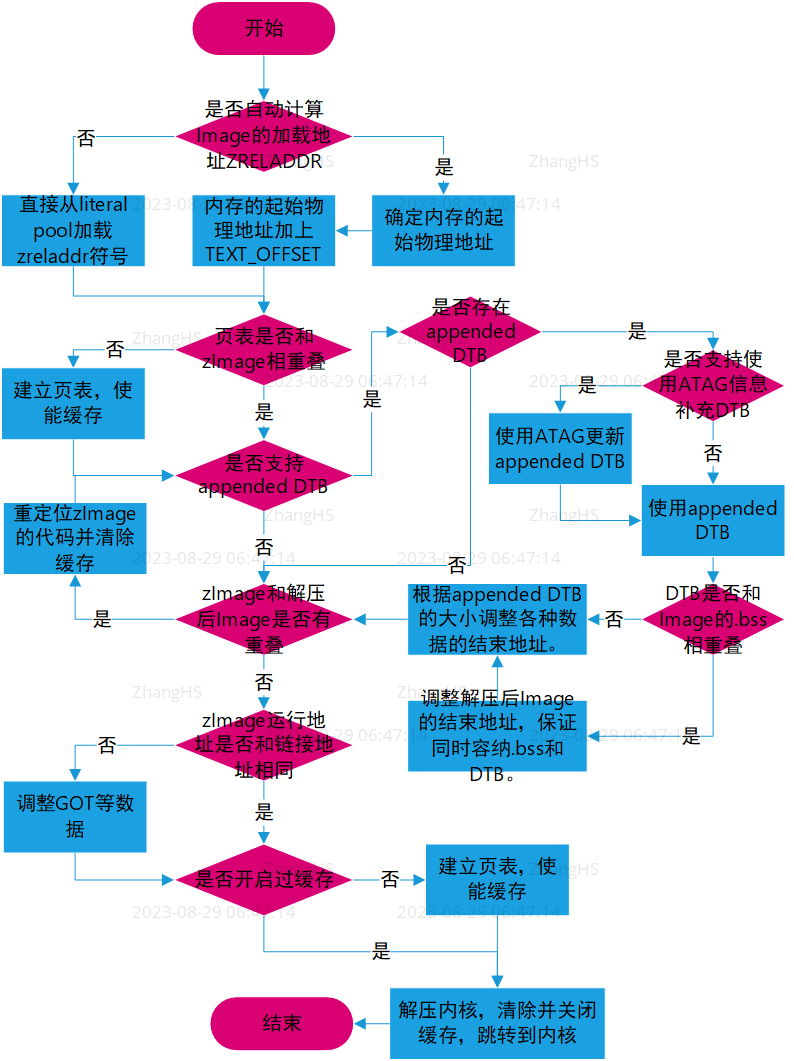
因为原始代码是用汇编写成,看起来不像C代码直观,所以个人整理了如下流程图来便于理解。每一个步骤对应到原始汇编代码的话,可能在数十行这样一个数量级。由于水平所限,只讨论ARMv7-A小端相关代码,但是对于理解整体流程应该不会有太大影响。

由以上流程图可以看出,如果在众多的分支判断中选择最简单的一条路径,实际上是一个很清晰的流程。之所以解压代码看起来比较复杂,除了是用汇编实现之外,个人觉得还有以下几点原因。
- 需要兼容不同的ARM架构,例如大端小端选择,thumb和ARM指令的选择,不同版本v4直至v7之间的选择。
- zImage和Image的位置会有多种组合可能,因为需要兼容不同的bootloader和不同的板级配置。
- 运行环境是祼系统(bare-metal),不存在C运行库。
- 需要拷贝代码并重定位。
下面是个人在阅读代码时产生的一些问题,以及相应的解释。排列顺序大致对应到代码的编写顺序。
Q:为什么zImage是位置无关代码(Position Independent Code,PIC)?
A:因为Linux希望同一个内核文件vmlinux可以运行在多平台上,而不同平台的地址空间是不相同的,所以为了支持多平台,zImage是PIC代码。
Q:为什么要确定zImage当前所在内存的起始物理地址?
A:内存的起始物理地址并不一定是0。一些情况下需要用到内存的绝对地址,例如LDR和STR指令要求知道内存实际物理地址,Image也要求必须放在相对于内存起始偏移为TEXT_OFFSET的位置。TEXT_OFFSET是由arch/arm/Makefile定义的,表示的是未压缩内核的偏移地址。
Q:zImage的解压代码可以被bootloader加载到任意地址,而zImage链接时指定的VMA默认是0。怎么保证zImage可以在任意内存地址范围正常运行?
A:因为zImage代码是PIC的,所以链接时指定的VMA和其实际运行的地址即使是不一致的,也可以运行。然而,有些地址需要在运行时实时计算。通常做法是,在汇编中定义一个标签(label),链接时记录下需要实时运算的地址和标签的相对偏移。使用adr指令采用PC相对寻址,就可以得到实际运行时标签所在地址,再加上记录下的相对偏移,就得到了运行时的实际地址。
Q:为什么通过PC地址和0xf8000000作与运算,来确定内存的起始物理地址?
A:只是一种实现上的折衷,代码注释原文使用的是balance。在内核配置CONFIG_AUTO_ZRELADDR的帮助中,也有相应说明。这个运算过程实际上要求内存的起始物理地址要对齐到128M。如果将对齐要求增加为0xf0000000,那就是按照256M对齐,有些平台可能满足不了这个条件。如果变为0xfc000000,那就是按照64M对齐。此时如果zImage被加载到第二个64M的范围内,就不能得到内存的起始地址了。从技术上,并不要求内存的起始物理地址一定是128M对齐,实际上2021年1月4号的一个补丁就是解决某些平台的内存起始地址是0x0C000000而带来的问题,该补丁经过了多次修改,v5、v6、v9、v10、v11、v12。
Q:为什么存在appended DTB时,不将其用于更正内存的起始物理地址?
A:appended DTB可能需要ATAGS来更新,而ATAGS有可能位于内存上偏移为0x100的地址,这又需要内存起始地址。这就是一个先有鸡先有蛋的问题。在0673cb38951215060d7993b43ad3c45cd413c2c3 v9的邮件讨论中有解释。为了简化设计,就只在显式传递DTB时,将其用于更正内存的起始地址。
Q:如何获取解压后内核大小?
A:定义了一个宏get_inflated_image_size,来获取解压后内核大小。内核构建系统会在压缩内核时,将解压后的大小放在压缩文件最后面4个字节,生成piggy_data,而arch/arm/boot/compressed/piggy.S用于将piggy_data和代码一起链接,并且定义了符号input_data_end,表示piggy_data的结束地址。arch/arm/boot/compressed/head.S则记录了input_data_end-4的值,从这个地址就可以读取出解压后内核大小。
Q:为什么不直接将解压后内核大小以宏定义形式,在编译解压代码时传递进去呢?
A:在2011年2月21号提交的代码中就是将解压后的大小使用链接脚本形式直接指定的。gzip算法使用压缩后的文件最后4个字节表示压缩前的大小,其它压缩算法没有这样的特点。早在2009年1月4号就通过scripts/Makefile.lib脚本为bzip2和lzma算法额外添加表示压缩前大小的这4个字节。arch/arm/boot/compressed/Makefile在生成piggy_data时,就会调用scripts/Makefile.lib中相应的命令。因此,2011年4月19号改成使用piggy_data的最后4个字节,来得到解压后的大小。
Q:zImage和Image的地址范围有重叠,怎么处理?
A:解压流程总是将zImage拷贝到Image结束的位置之后,再重新运行zImage的代码。代码不会检查zImage是否会被拷贝到有效的内存。如果zImage超出了内存范围,解压就会失败。这种情况下,就只能直接拷贝未压缩的内核。使用zImage启动需要的内存会比直接使用Image启动要大。
Q:为什么zImage重定位后,要从restart开始运行,而不是直接解压?
A:因为在重定位的过程中,为了加快搬运速度,很多寄存器都用于LDM/STM指令,之前保存这些信息的寄存器都被破坏了。理论上有些信息在重定位之后和之前是没有变化的,例如解压后内核的大小,可以将这些寄存器放在内存中之后再恢复。而有些信息在重定位之后需要更新的话,可以通过记录下重定位的偏移来更新。但是要分别出哪些信息需要更新会比较麻烦,有遗漏的风险,万一添加了新特性,又要去分辨哪些相关的内容需要在重定位之后更新。因此,重新从restart处运行便于后续维护。而从restart处,而不是start这个标签开始运行,是因为start到restart主要是运行环境的初始化,没有必要再重复运行,同时r4、r7和r8这几个寄存器的值在重定位过程中没有被破坏。
Q:解压后的Image超出了实际内存,会发生什么?
A:根据当前设计,解压后Image位于的地址一定会低于zImage运行的地址。因此这种情况下,zImage已经超出了实际内存,无法正常解压。在2011年2月12号及之前,是先解压Image。再将zImage中一小段代码进行拷贝并重定位,利用这一小段代码再将Image拷贝到实际运行地址,这种情况下就有可能将Image拷贝到实际内存之外。在2011年2月21号,就改成了将zImage的代码进行重定位,解压后的Image不需要拷贝。
Q:DTB是否会被重定位后的zImage覆盖?
A:ARM32启动文档中设置设备树的章节建议DTB的安全位置位于物理内存的起始128M之外。这个由bootloader来保证。
Q:initramfs是否会被重定位后的zImage覆盖?
A:和DTB类似,是bootloader来保证内核Image,DTB,initramfs不互相覆盖。也是在ARM32启动文档中加载initramfs的章节推荐了initramfs的加载位置,即紧跟着DTB后面。
Q:为什么有些常量使用ldr r0, =const方式,有些常量直接放在汇编指令里。
A:因为ARM指令立即数的范围是有限制的,所以只能用ldr r0, =const形式。
Q:为什么需要检查appended DTB和kernel_bss_size的大小关系?
A:当内核所在地址低于zImage的地址时,如果没有这个检查的话,内核的bss太大的话,会覆盖掉appended DTB。此时,需要重定位zImage,往更高地址移动。
Q:为什么有两次比较Image和zImage的地址范围?
A:第一次比较只是检查页表会不会和zImage有重叠,并不考虑Image是否和zImage有重叠。如果Image和zImage没有重叠,那么页表也必定不会重叠。但是,页表和zImage没有重叠,并不能保证Image和zImage没有重叠。建立页表可以加快重定位zImage的速度。如果只作一次比较,需要在不开启缓存的情况下,运行restart至dtb_check_done之间的代码,会影响启动速度。而大多数情况下,是可以建立页表并开启缓存的,多出来的第一次判断能加快启动速度。第一次判断时,zImage结束的地址并不是_end之后再加上16K,再加上1M。因为是用PC值加上的headroom标签中储存的值,而当前代码下PC比restart所在地址小8个字节,所以最终结果会少8个字节。但是多出来的1M是包括了zImage可能使用的堆栈空间,和预估的appended DTB大小,一般情况足够大了,因此少的这8个字节并不构成很大影响。并不会出现页表和重定位前的zImage有重叠的情况。
Q:为什么重定位前,,将Image的结束地址加上固定大小,并对齐到256字节?
A:最开始时,2011年2月21号的改动直接将Image结束地址向高地址对齐到256字节。2011年4月20号的改动为了避免覆盖掉拷贝的循环代码,将Image结束地址,也就是zImage重定位后的起始地址额外加上了重定位需要使用的代码的大小,即拷贝和缓存操作的代码。
这里可能出问题的原因在于,跳转到被重定位的代码之前,还需要在原来的位置运行拷贝和清除缓存的操作。如果重定位后的代码范围和这部分代码有重叠的话,这部分代码会被重定位后的代码覆盖,在跳转到重定位后的代码时就会有问题。因此,需要将重定位后的代码起始位置往高地址移动。但是这次提交的代码实现上有点问题,假设restart的地址是0x1E0,reloc_code_end的地址是0x2D0,而调整之前,Image结束地址是0x1F0,那么调整之后Image结束地址就是0x200 = (((0x2D0 - 0x1E0 + 0x100) & 0xFFFFFF00) + 0x1F0) & 0xFFFFFF00,0x200~0x2D0这段地址的内容就会被覆盖,如果跳转到重定位后的zImage之前,需要运行这一段地址上的代码就会出问题。
2011年6月12号的改动修正kernel_bss可能覆盖appended DTB这个问题,同时也调整了比较的范围,只有在Image的结束地址大于wont_overwrite这个标签的地址时,才进行重定位。这样相当于变相地,将Image结束地址增加了。
总结下来,为了避免重定位前的代码不被覆盖,需要保证其不在重定位后的代码范围内。方法就是将Image的结束地址往高地址增加,但是原来的加法操作有问题,还是有可能覆盖,只是需要同时满足以下几个条件:
- Image结束地址大于wont_overwrite标签地址,即必然大于restart标签地址。
- Image结束地址和restart标签地址在同一个对齐到256字节的块内。
- reloc_code_end标签地址和restart标签地址不在同一个对齐到256字节的块内。
- reloc_code_end标签地址除以256的余数要小于restart标签地址除以256的余数。
后面的修改隐式地增加了Image的结束地址,使得第二个条件在现有代码下基本上不满足,也就不会触发这个问题。即使触发了,被覆盖的代码也不会有运行机会。
Q:代码中有个not_relocated标签,不管有没有对zImage进行重定位,都会运行到这个地方。这是什么原因?
A:这个not_relocated和搬运zImage的重定位是不一样的概念。not_relocated标签的目的是zImage的运行地址和链接时指定的地址相同时,不需要调整GOT表。与是否需要搬运zImage没有关系,两者是相互独立的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号