

web自动化测试---xpath方式定位页面元素
在实际应用中,如果存在多个相同元素,包括属性相同时,一般会选用这种方式,当然如果定位属性唯一的话,也是可以使用的,不过这种方式没有像id,tag,name等容易理解,下面讲下xpath定位元素的方法
| / | 从根节点选取 |
| // | 从匹配选择的当前节点选择 |
| @ | 选取属性 |
| * | 匹配任何元素节点 |
| @* | 匹配任何属性节点 |
我们就以百度首页右上一排的元素来定位,一般来说通过find_element_by_link来定位,这里我们只介绍xpath来定位的方式
我们查看下原始的百度页面中tag='a',class='mnav'的元素有多少:
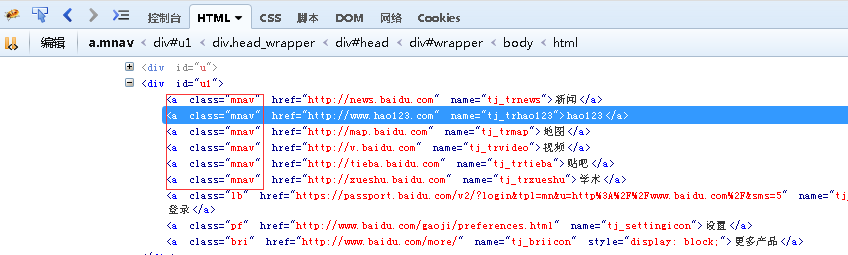
总共有6个,下面我们就来定位
1、定位第一个新闻的链接,语句如下:
driver.find_element_by_xpath('//a[@class="mnav"][1]').click()
这里用到的是短xpath,即如果不是从web的根开始查找元素,那么用 // 来表示,如果是根开始那只有一个 / 就可以了
2、定位最后一个学术链接,语句如下:
driver.find_element_by_xpath('//a[@class="mnav"][last()]').click()
#如果显示不是最后一个元素,可以写成如下:
driver.find_element_by_xpath('//a[@class-"mnav"][not last()]')
3、定位倒数第二个贴吧链接,语句如下:
driver.find_element_by_xpath('//a[@class="mnav"][last()-1]').click()
4、如果需要选取前俩个元素,则语句如下:
driver.find_element_by_xpath('//a[@class="mnav"][position()<3]')
5、我们也可以通过下面语句定位学术链接,语句如下:
driver.find_element_by_xpath('//a[@name="tj_trxueshu"]').click()
6、如果需要选取不在一起的俩个元素(比如地图和贴吧),那么可以参考如下语句:
driver.find_element_by_xpath('//a[@name="tj_trmap"]|//a[@name="tj_trtieba"')
7、通过tag也可以也可以选取:
driver.find_element_by_xpath('//*[local-name()="a"]')
#或者通过tag以a开头来获取:
driver.find_element_by_xpath('//*[starts-with(local-name(),"a")]')
#或者通过tag包含a来获取:
driver.find_element_by_xpath('//*[contains(local-name(),"a")]')
#或者通过tag的长度来获取:
dirver.find_element_by_xpath('//*[string-length(local-name())=5]')
8、父兄节点
<div>
<a id="1" href="www.baidu.com">我是第1个a标签</a>
<p>我是p标签</p>
<a id="2" href="www.baidu.com">我是第2个a标签</a>
<a id="3" href="www.baidu.com">我是第3个a标签</a>
<a id="4" href="www.baidu.com">我是第4个a标签</a>
<p>我是p标签</p>
<a id="5" href="www.baidu.com">我是第5个a标签</a>
</div>
获取第三个a标签的下一个a标签:"//a[@id='3']/following-sibling::a[1]"
获取第三个a标签后面的第N个标签:"//a[@id='3']/following-sibling::*[N]"
获取第三个a标签的上一个a标签:"//a[@id='3']/preceding-sibling::a[1]"
获取第三个a标签的前面的第N个标签:"//a[@id='3']/preceding-sibling::*[N]"
获取第三个a标签的父标签:"//a[@id=='3']/.."
关于本篇内容如有转载请注明出处;技术内容的探讨、纠错,请发邮件到70907583@qq.com

