digits 手写数据测试
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
digits = datasets.load_digits()
(1797, 64)
y = digits.target
y.shape
(1797,)
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
array([ 0., 0., 5., 13., 9., 1., 0., 0., 0., 0., 13., 15., 10.,
15., 5., 0., 0., 3., 15., 2., 0., 11., 8., 0., 0., 4.,
12., 0., 0., 8., 8., 0., 0., 5., 8., 0., 0., 9., 8.,
0., 0., 4., 11., 0., 1., 12., 7., 0., 0., 2., 14., 5.,
10., 12., 0., 0., 0., 0., 6., 13., 10., 0., 0., 0.])
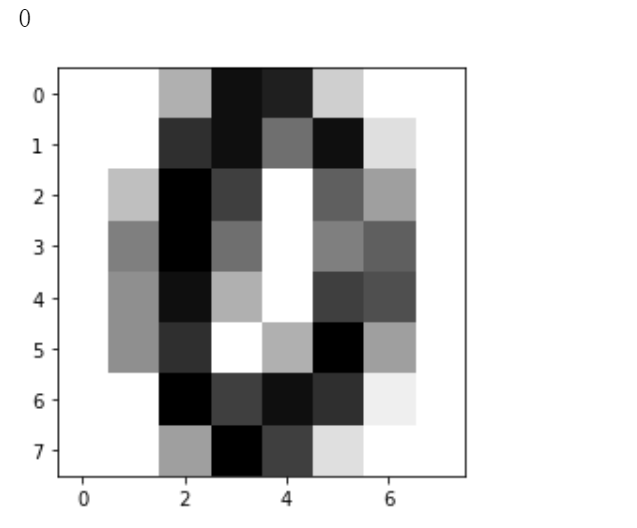
0
some_digit_image = X[666].reshape(8, 8)
plt.imshow(some_digit_image, cmap=matplotlib.cm.binary)
y[666]
![]()
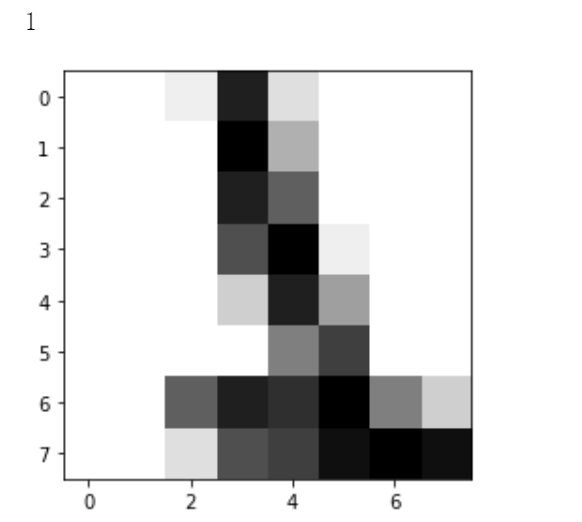
some_digit_image = X[1000].reshape(8, 8)
plt.imshow(some_digit_image, cmap=matplotlib.cm.binary)
y[1000]
![]()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=666)
knn_clf = KNeighborsClassifier(3)
knn_clf.fit(X_train, y_train)
y_predict = knn_clf.predict(X_test)
accuracy_score(y_test, y_predict)
0.9888888888888889
寻找最好的k
best_score = 0.0
best_k = -1
for k in range(1,11):
knn_clf = KNeighborsClassifier(k)
knn_clf.fit(X_train, y_train)
y_predict = knn_clf.predict(X_test)
score= accuracy_score(y_test, y_predict)
if score > best_score:
best_k = k
best_score = score
print("best_k:", best_k)
print("best_score:", best_score)
best_k: 4
best_score: 0.9916666666666667
考虑距离?不考虑距离
best_method = ""
best_score = 0.0
best_k = -1
for method in ["uniform", "distance"]:
for k in range(1,11):
knn_clf = KNeighborsClassifier(n_neighbors=k, weights=method)
knn_clf.fit(X_train, y_train)
y_predict = knn_clf.predict(X_test)
score= accuracy_score(y_test, y_predict)
if score > best_score:
best_k = k
best_score = score
best_method = method
print("best_k:", best_k)
print("best_score:", best_score)
print("best_method:", best_method)
best_k: 4
best_score: 0.9916666666666667
best_method: uniform
探索明可夫斯基距离相应的p
best_p = -1
best_method = ""
best_score = 0.0
best_k = -1
for k in range(1,11):
for p in range(1, 6):
knn_clf = KNeighborsClassifier(n_neighbors=k, weights="distance", p=p)
knn_clf.fit(X_train, y_train)
y_predict = knn_clf.predict(X_test)
score= accuracy_score(y_test, y_predict)
if score > best_score:
best_k = k
best_score = score
best_p = p
print("best_k:", best_k)
print("best_score:", best_score)
print("best_p:", p)
best_k: 3
best_score: 0.9888888888888889
best_p: 5
寻找最好的超参数 Grid Search
param_grid = [
{
"weights":["uniform"],
"n_neighbors":[i for i in range(1,11)]
},
{
"weights":["distance"],
"n_neighbors":[i for i in range(1,11)],
"p":[i for i in range(1,6)]
}
]
knn_clf = KNeighborsClassifier()
from sklearn.model_selection import GridSearchCV
%%time
grid_search = GridSearchCV(knn_clf, param_grid)
Wall time: 0 ns
%%time
grid_search.fit(X_train, y_train)
Wall time: 1min 1s
GridSearchCV(cv=None, error_score=nan,
estimator=KNeighborsClassifier(algorithm='auto', leaf_size=30,
metric='minkowski',
metric_params=None, n_jobs=None,
n_neighbors=5, p=2,
weights='uniform'),
iid='deprecated', n_jobs=None,
param_grid=[{'n_neighbors': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'weights': ['uniform']},
{'n_neighbors': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'p': [1, 2, 3, 4, 5], 'weights': ['distance']}],
pre_dispatch='2*n_jobs', refit=True, return_train_score=False,
scoring=None, verbose=0)
grid_search.best_estimator_
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=1, p=2,
weights='uniform')
knn_clf = grid_search.best_estimator_
y_predict = knn_clf.predict(X_test)
print(accuracy_score(y_test, y_predict))
0.9833333333333333
knn_clf = KNeighborsClassifier()
grid_search = GridSearchCV(knn_clf, param_grid, n_jobs=-1, verbose=2)
grid_search.fit(X_train, y_train)
knn_clf = grid_search.best_estimator_
y_predict = knn_clf.predict(X_test)
print(accuracy_score(y_test, y_predict))
Fitting 5 folds for each of 60 candidates, totalling 300 fits
[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers.
[Parallel(n_jobs=-1)]: Done 25 tasks | elapsed: 1.4s
[Parallel(n_jobs=-1)]: Done 244 tasks | elapsed: 9.9s
[Parallel(n_jobs=-1)]: Done 285 out of 300 | elapsed: 11.6s remaining: 0.5s
[Parallel(n_jobs=-1)]: Done 300 out of 300 | elapsed: 12.2s finished
grid_search.best_estimator_
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=1, p=2,
weights='uniform')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号