Scrapy 项目:QuotesBot
QuotesBot
This is a Scrapy project to scrape quotes from famous people from http://quotes.toscrape.com (github repo).
This project is only meant for educational purposes.
任务:
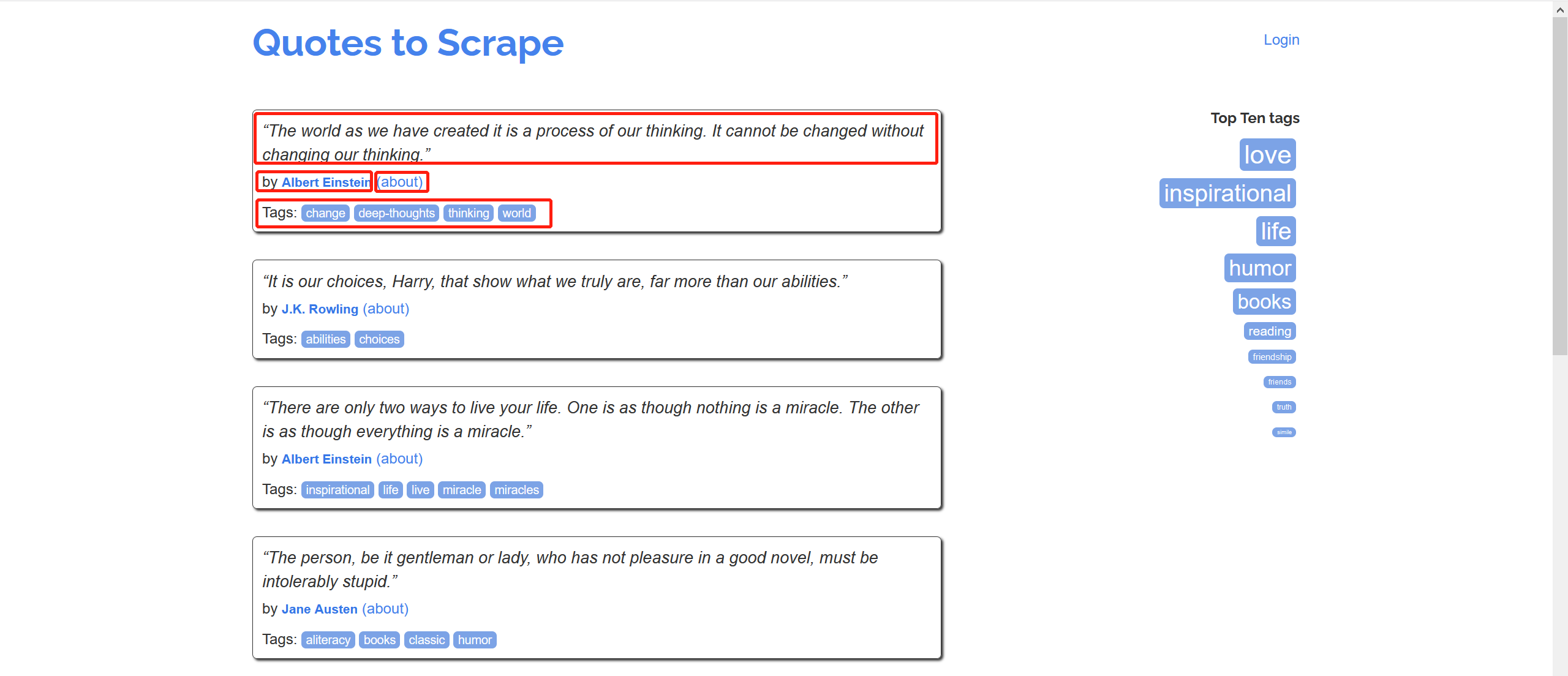
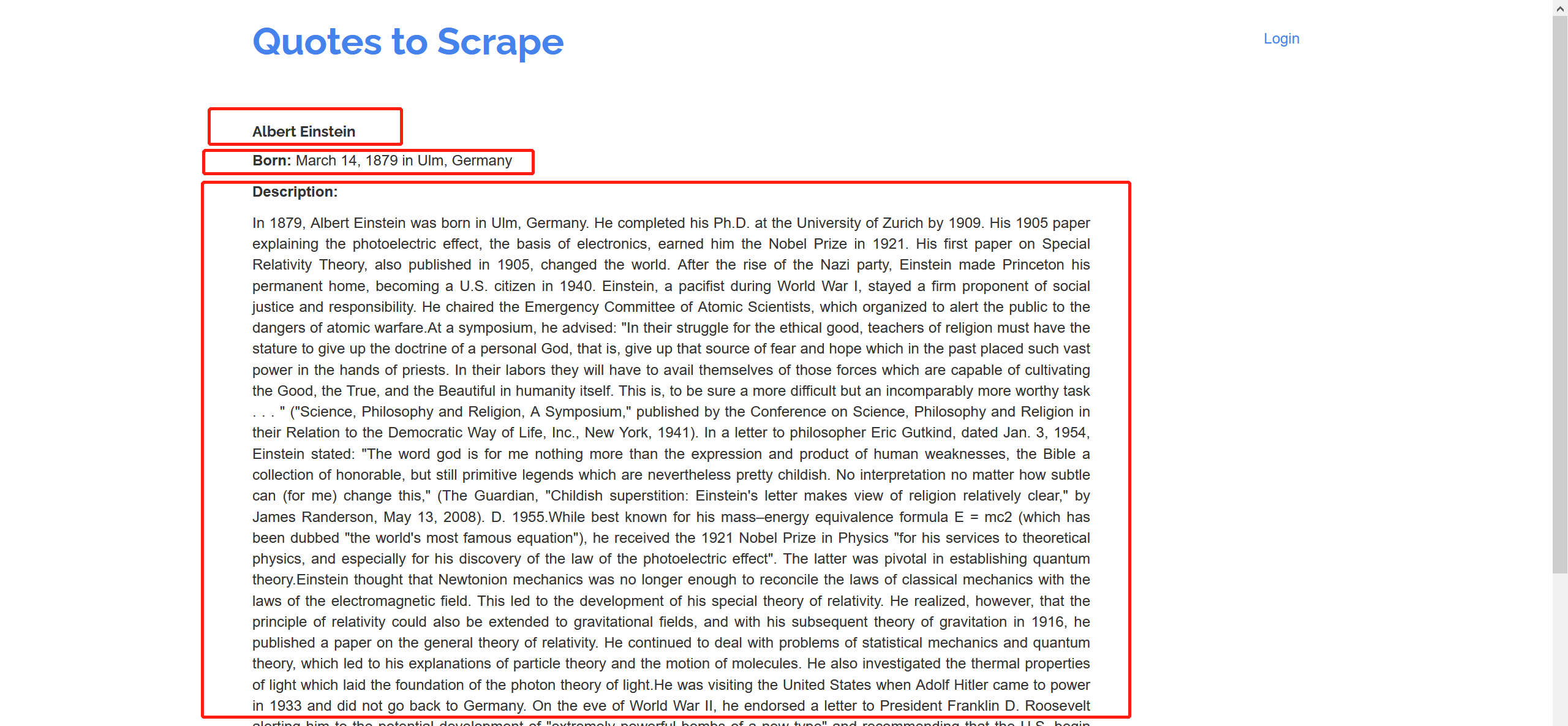
爬取该网站的名人名言、作者、作者信息(名字,生日、描述)以及名言标签,并保存
import scrapy
import re
class AuthorSpider(scrapy.Spider):
name = "author"
start_urls = ["http://quotes.toscrape.com/"]
def parse(self, response):
author_page_links = response.css('.author + a')
yield from response.follow_all(author_page_links, self.parse_author)
next_page_links = response.css('li.next a')
yield from response.follow_all(next_page_links, self.parse)
def parse_author(self, response):
def extract_with_css(query):
return response.css(query).get(default="").strip()
yield {
"name": extract_with_css("h3.author-title::text"),
"birthdate": extract_with_css(".author-born-date::text"),
"bio": extract_with_css(".author-description::text"),
}
保存:
scrapy crawl spidername -o test.csv
项目练习:
Extracted data
This project extracts quotes, combined with the respective author names and tags. The extracted data looks like this sample:
{
'author': 'Douglas Adams',
'text': '“I may not have gone where I intended to go, but I think I ...”',
'tags': ['life', 'navigation']
}
Spiders
This project contains two spiders and you can list them using the list command:
$ scrapy list
toscrape-css
toscrape-xpath
Both spiders extract the same data from the same website, but toscrape-css employs CSS selectors, while toscrape-xpath employs XPath expressions.
You can learn more about the spiders by going through the Scrapy Tutorial.
Running the spiders
You can run a spider using the scrapy crawl command, such as:
scrapy crawl toscrape-css
If you want to save the scraped data to a file, you can pass the -o option:
scrapy crawl toscrape-css -o quotes.json
项目代码:
class QuotesbotSpider(scrapy.Spider): name = "quotesbot" start_urls = ["http://quotes.toscrape.com"] def parse(self, response, **kwargs): for quote in response.css('div.quote'): yield { "author":quote.css(".author::text").get(), "text":quote.css(".text::text").get(), "tags":quote.css(".tags meta::attr(content)").get(), } next_page_link = response.css("li.next a") if next_page_link is not None: yield from response.follow_all(next_page_link, callbac
结果: